정의 #
변수 할당자 노드는 쓰기 가능한 변수에 값을 할당하는 데 사용됩니다. 현재 지원되는 쓰기 가능한 변수는 다음과 같습니다.
- 대화 변수 .
사용법: 변수 할당자 노드를 통해 워크플로 변수를 대화 변수에 할당하여 임시로 저장할 수 있으며, 이후 대화에서 지속적으로 참조할 수 있습니다.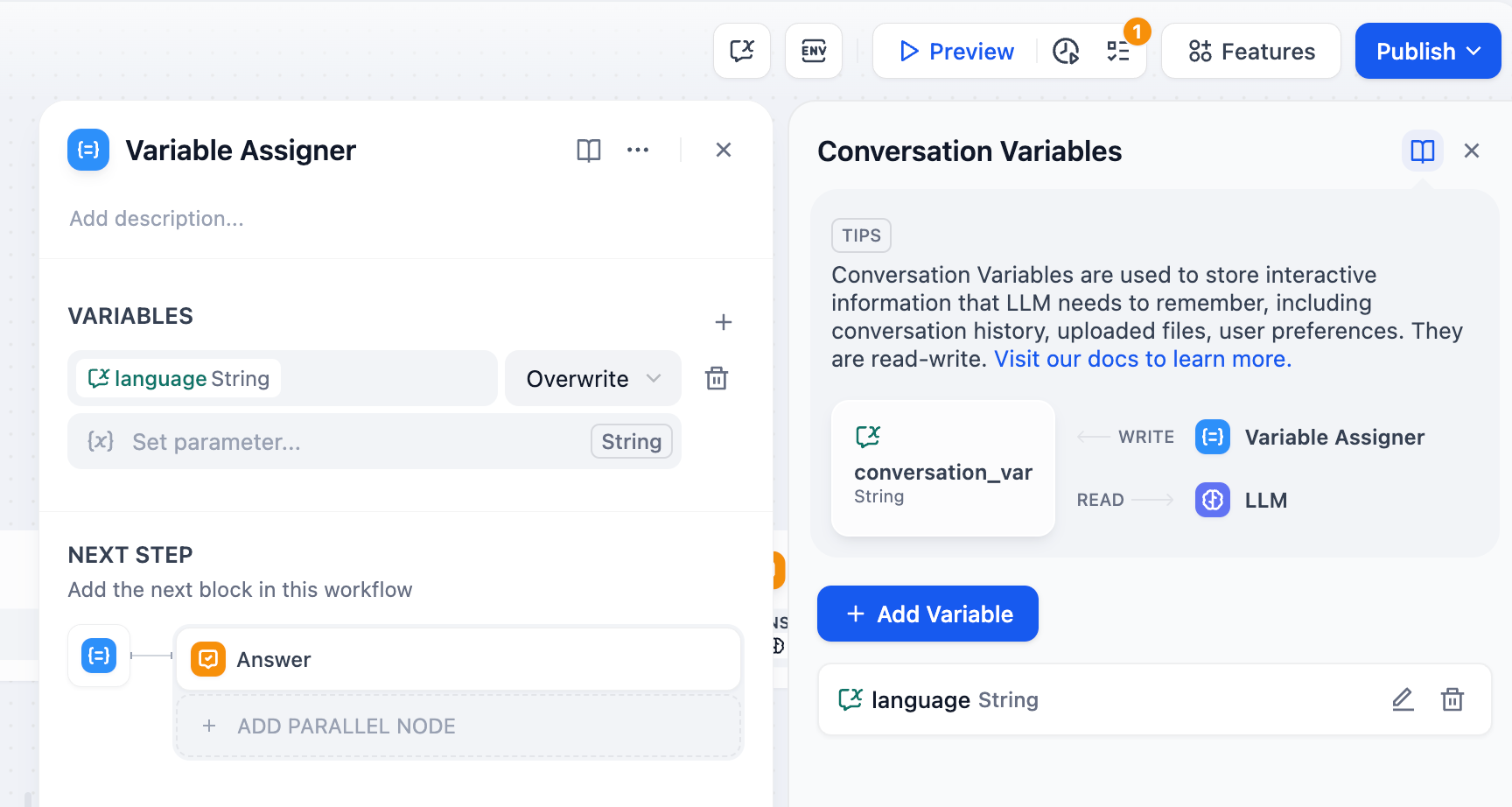
사용 시나리오 예 #
변수 할당자 노드를 사용하면 대화 프로세스의 컨텍스트, 대화 상자에 업로드된 파일, 그리고 사용자 선호도 정보를 대화 변수에 기록할 수 있습니다. 이렇게 저장된 변수는 이후 대화에서 참조되어 다양한 처리 흐름을 지시하거나 응답을 작성할 수 있습니다.시나리오 1자동으로 내용을 판단하고 추출하고 , 대화의 내역을 저장하고, 대화 내의 세션 변수 배열을 통해 중요한 사용자 정보를 기록하고, 이 내역 내용을 사용하여 후속 채팅에서 응답을 개인화합니다.예: 대화가 시작된 후, LLM은 사용자 입력 내용에 기억해야 할 사실, 선호도 또는 채팅 기록이 포함되어 있는지 자동으로 판단합니다. 만약 포함되어 있다면, LLM은 먼저 해당 정보를 추출하여 저장한 후, 이를 맥락으로 활용하여 답변합니다. 기억할 새로운 정보가 없다면, LLM은 이전에 기억했던 관련 정보를 바로 활용하여 질문에 답변합니다.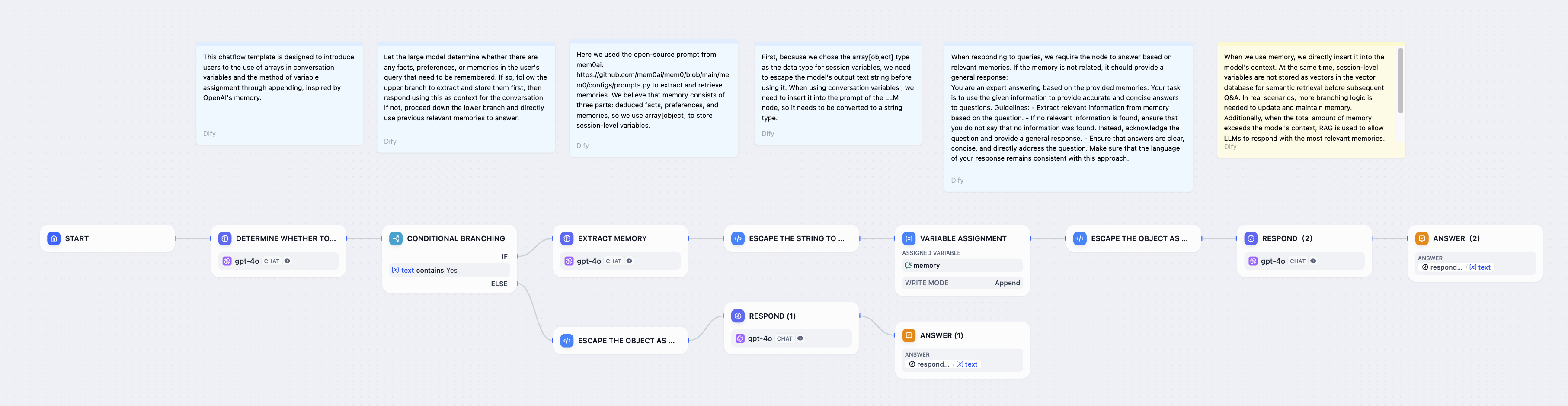 구성 프로세스:
구성 프로세스:
- 대화 변수 설정:
memories먼저, 사용자 정보, 기본 설정, 채팅 기록을 저장하기 위해 array[object] 유형의 대화 변수 배열을 설정합니다 .
- 기억을 확인하고 추출합니다.
- LLM을 사용하여 사용자 입력에 기억해야 할 새로운 정보가 포함되어 있는지 여부를 확인하는 조건 분기 노드를 추가합니다.
- 새로운 정보가 있으면 상위 분기를 따라가고 LLM 노드를 사용하여 이 정보를 추출합니다.
- 새로운 정보가 없다면, 가지를 따라 내려가서 기존의 기억을 직접 사용하여 대답하세요.
- 변수 할당/쓰기:
- 상위 분기에서 변수 할당자 노드를 사용하여 새로 추출한 정보를
memories배열에 추가합니다. - 이스케이프 함수를 사용하여 LLM에서 출력된 텍스트 문자열을 배열[객체]에 저장하기에 적합한 형식으로 변환합니다.
- 상위 분기에서 변수 할당자 노드를 사용하여 새로 추출한 정보를
- 변수 판독 및 사용:
- 이후 LLM 노드에서 배열의 내용을
memories문자열로 변환하여 LLM 프롬프트에 컨텍스트로 삽입합니다. - 이러한 기억을 활용해 개인화된 응답을 생성하세요.
- 이후 LLM 노드에서 배열의 내용을
위 다이어그램의 노드에 대한 코드는 다음과 같습니다.
- 문자열을 객체로 이스케이프합니다.
복사AI에게 물어보세요
import json
def main(arg1: str) -> object:
try:
# Parse the input JSON string
input_data = json.loads(arg1)
# Extract the memory object
memory = input_data.get("memory", {})
# Construct the return object
result = {
"facts": memory.get("facts", []),
"preferences": memory.get("preferences", []),
"memories": memory.get("memories", [])
}
return {
"mem": result
}
except json.JSONDecodeError:
return {
"result": "Error: Invalid JSON string"
}
except Exception as e:
return {
"result": f"Error: {str(e)}"
}
- 객체를 문자열로 이스케이프합니다.
복사AI에게 물어보세요
import json
def main(arg1: list) -> str:
try:
# Assume arg1[0] is the dictionary we need to process
context = arg1[0] if arg1 else {}
# Construct the memory object
memory = {"memory": context}
# Convert the object to a JSON string
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
# Wrap the JSON string in <answer> tags
result = f"<answer>{json_str}</answer>"
return {
"result": result
}
except Exception as e:
return {
"result": f"<answer>Error: {str(e)}</answer>"
}
시나리오 2초기 사용자 환경 설정 입력 기록 : 대화 중에 사용자의 언어 환경 설정 입력을 기억하고 이후 채팅에서 응답할 때 이 언어를 계속 사용합니다.예: 채팅 전에 사용자가 language입력란에 “영어”를 지정합니다. 이 언어는 대화 변수에 기록되고, LLM은 응답 시 이 정보를 참조하여 이후 대화에서도 “영어”를 계속 사용합니다.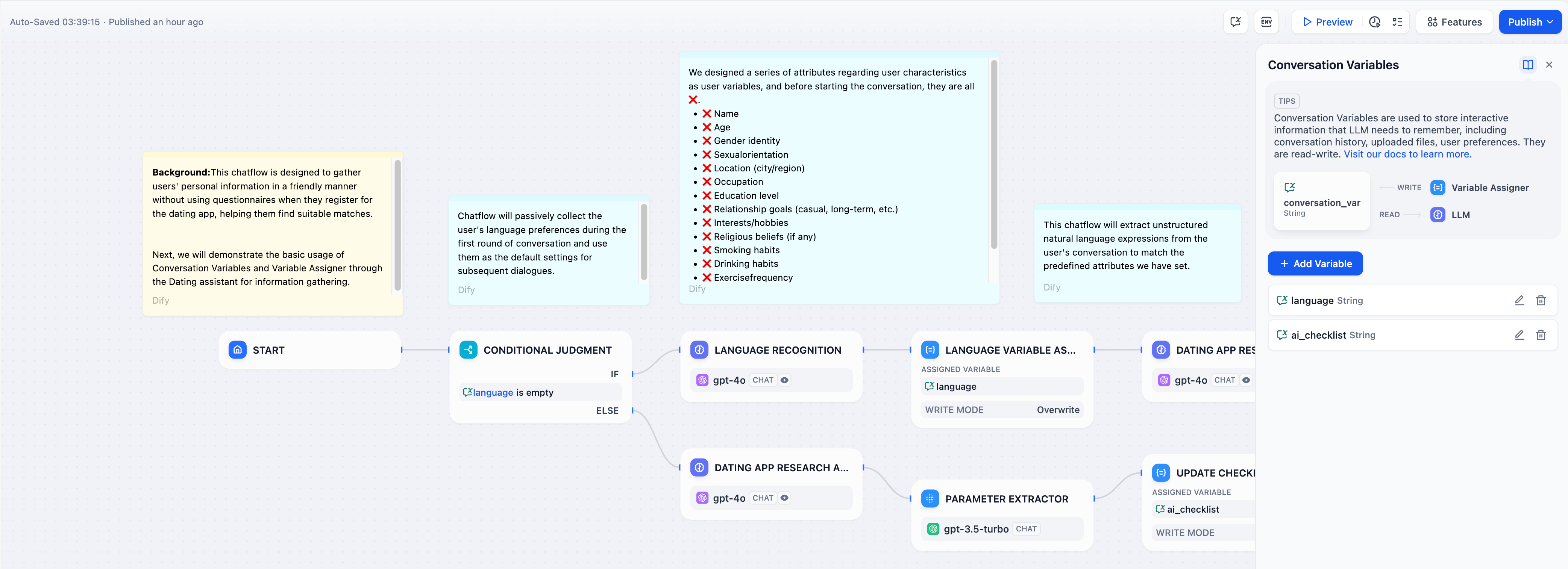 구성 가이드:대화 변수 설정 : 먼저 대화 변수를 설정합니다
구성 가이드:대화 변수 설정 : 먼저 대화 변수를 설정합니다 language. 대화 흐름 시작 부분에 조건 판단 노드를 추가하여 language변수가 비어 있는지 확인합니다.변수 쓰기/할당 : 첫 번째 채팅 라운드가 시작될 때 language변수가 비어 있으면 LLM 노드를 사용하여 사용자의 입력 언어를 추출한 다음 변수 할당자 노드를 사용하여 이 언어 유형을 대화 변수에 씁니다 language.변수 읽기 : 이후 대화 라운드에서 language변수는 사용자의 언어 선호도를 저장합니다. LLM 노드는 언어 변수를 참조하여 사용자가 선호하는 언어 유형을 사용하여 응답합니다.시나리오 3체크리스트 점검 지원 : 대화 변수를 사용하여 대화 내 사용자 입력을 기록하고, 체크리스트의 내용을 업데이트하고, 후속 대화에서 누락된 항목을 확인합니다.예: 대화 시작 후, LLM은 사용자에게 채팅 상자에 체크리스트 관련 항목을 입력하도록 요청합니다. 사용자가 체크리스트의 내용을 언급하면 해당 내용이 업데이트되어 대화 변수에 저장됩니다. LLM은 각 대화 라운드가 끝날 때마다 사용자에게 누락된 항목을 계속 보충하도록 알려줍니다.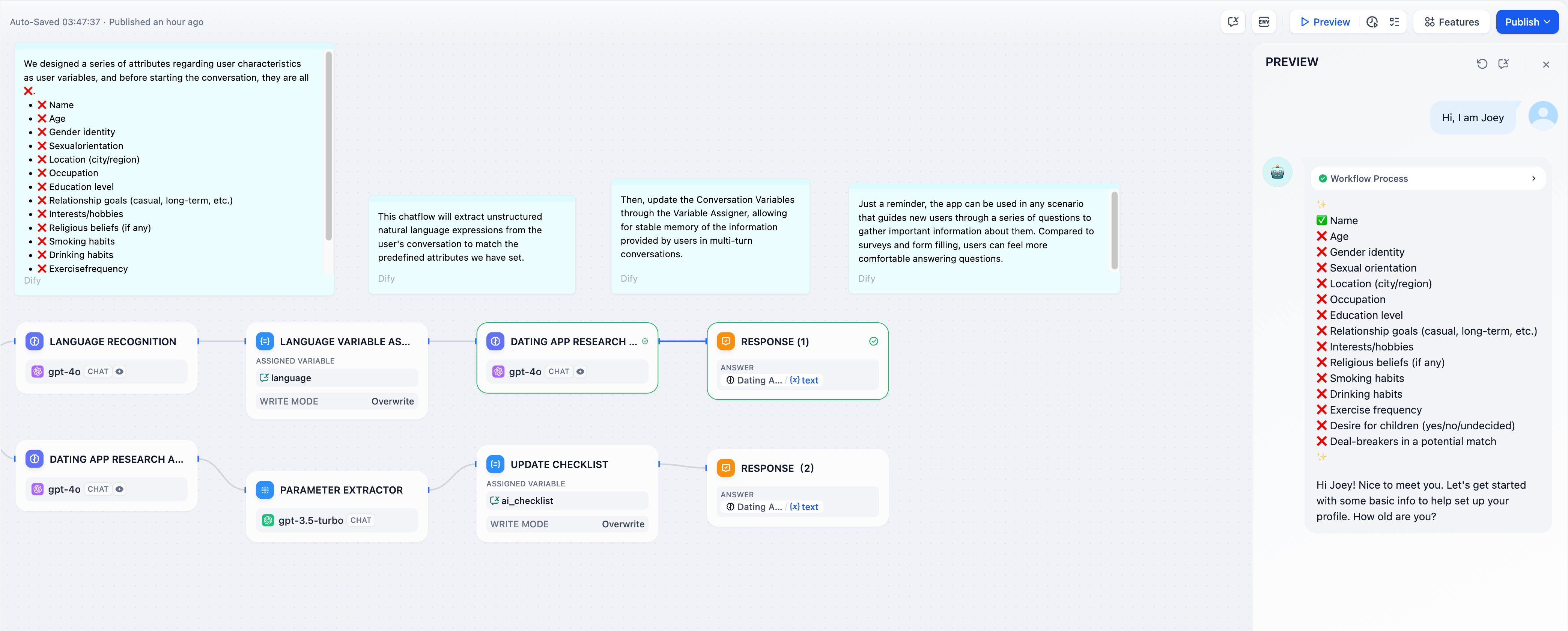 구성 프로세스:
구성 프로세스:
- 대화 변수 설정: 먼저 대화 변수를 설정하고
ai_checklist, LLM 내에서 이 변수를 참조하여 검사를 위한 컨텍스트로 사용합니다. - 변수 할당자/작성 : 각 대화 라운드 동안
ai_checklistLLM 노드 내의 값을 확인하고 사용자 입력과 비교합니다. 사용자가 새로운 정보를 제공하면 체크리스트를 업데이트하고ai_checklist변수 할당자 노드를 사용하여 출력 내용을 작성합니다. - 변수 읽기: 대화의 각 라운드에서 값을 읽고
ai_checklist사용자 입력과 비교하여 체크리스트의 모든 항목이 완료될 때까지 진행합니다.
변수 할당자 노드 사용 #
+노드 오른쪽의 아이콘을 클릭 하고 “변수 할당” 노드를 선택하세요. 대상 변수와 해당 소스 변수를 설정하세요. 이 노드를 사용하면 여러 변수에 동시에 값을 할당할 수 있습니다.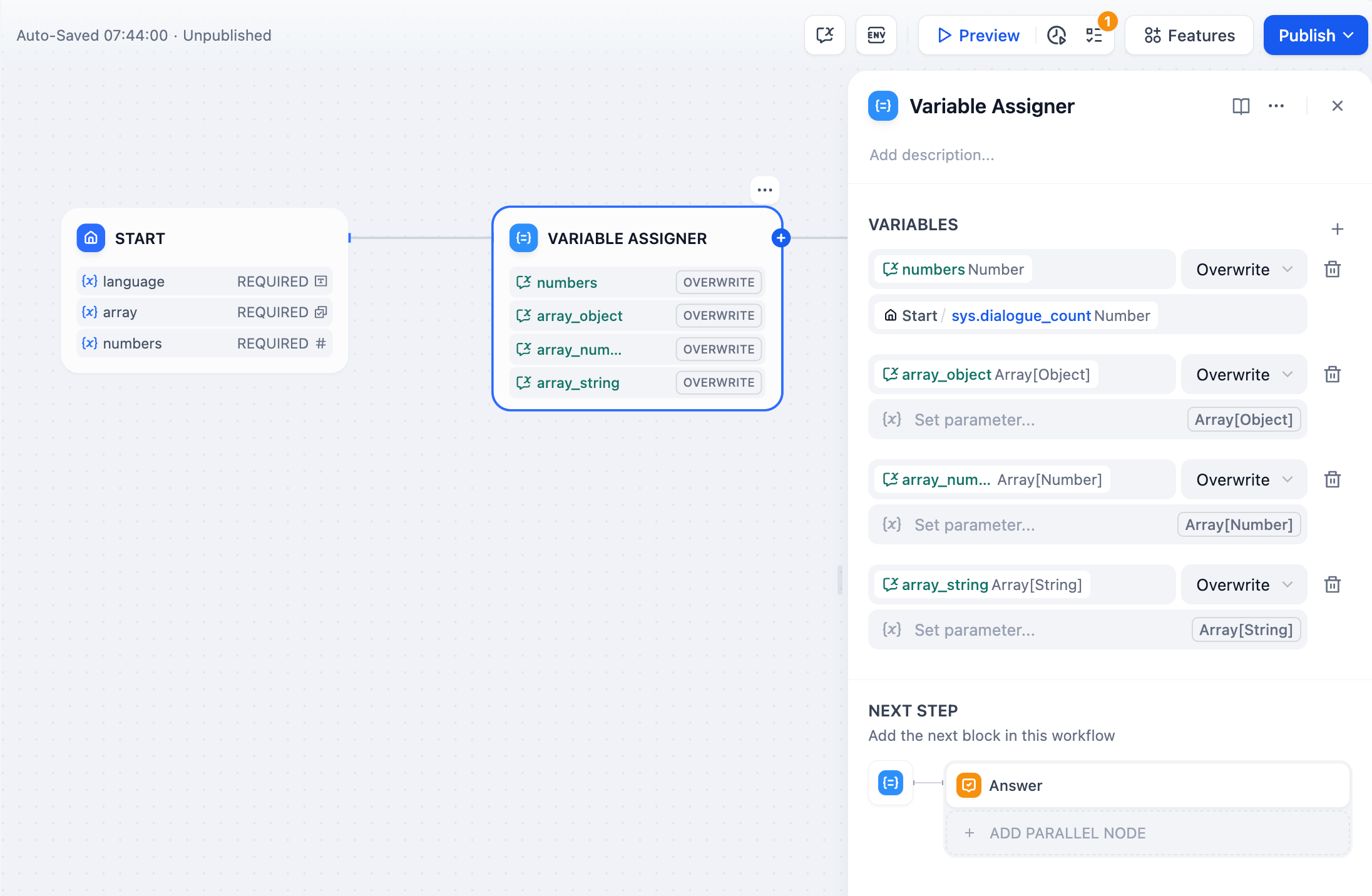 변수 설정:변수: 할당할 변수를 선택합니다. 즉, 할당해야 할 대상 대화 변수를 지정합니다.변수 설정: 할당할 변수를 선택합니다. 즉, 변환해야 할 소스 변수를 지정합니다.위 이미지에 나와 있는 변수 할당 논리는 초기 페이지에서 지정한 사용자의 언어 기본 설정을
변수 설정:변수: 할당할 변수를 선택합니다. 즉, 할당해야 할 대상 대화 변수를 지정합니다.변수 설정: 할당할 변수를 선택합니다. 즉, 변환해야 할 소스 변수를 지정합니다.위 이미지에 나와 있는 변수 할당 논리는 초기 페이지에서 지정한 사용자의 언어 기본 설정을 Start/language시스템 수준 대화 변수에 할당합니다 language.
변수 지정을 위한 작업 모드 #
대상 변수의 데이터 유형에 따라 연산 방식이 결정됩니다. 다음은 다양한 변수 유형에 따른 연산 방식입니다.
- 대상 변수 데이터 유형:
String• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 지정합니다. - 대상 변수 데이터 유형:
Number• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 할당합니다. • 산술 : 대상 변수에 덧셈, 뺄셈, 곱셈 또는 나눗셈을 수행합니다. - 대상 변수 데이터 유형:
Object• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 지정합니다. - 대상 변수 데이터 유형:
Array• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 추가 : 대상 변수의 배열에 새 요소를 추가합니다. • 확장 : 대상 변수에 새 배열을 추가하여 여러 요소를 한 번에 추가합니다. • 제거 : 배열에서 요소를 제거합니다. 첫 번째 위치(First) 또는 마지막 위치(Last)에서 제거하는 옵션이 있으며, 기본값은 “First”입니다.



