Start(시작) #
정의 #
“시작” 노드 는 Chatflow/Workflow 애플리케이션의 중요한 사전 설정 노드입니다. 사용자 입력 및 업로드된 파일 과 같은 필수적인 초기 정보를 제공하여 애플리케이션 및 후속 워크플로 노드의 정상적인 흐름을 지원합니다.
노드 구성 #
시작 노드의 설정 페이지에는 “입력 필드” 와 사전 설정 시스템 변수라는 두 섹션이 있습니다 .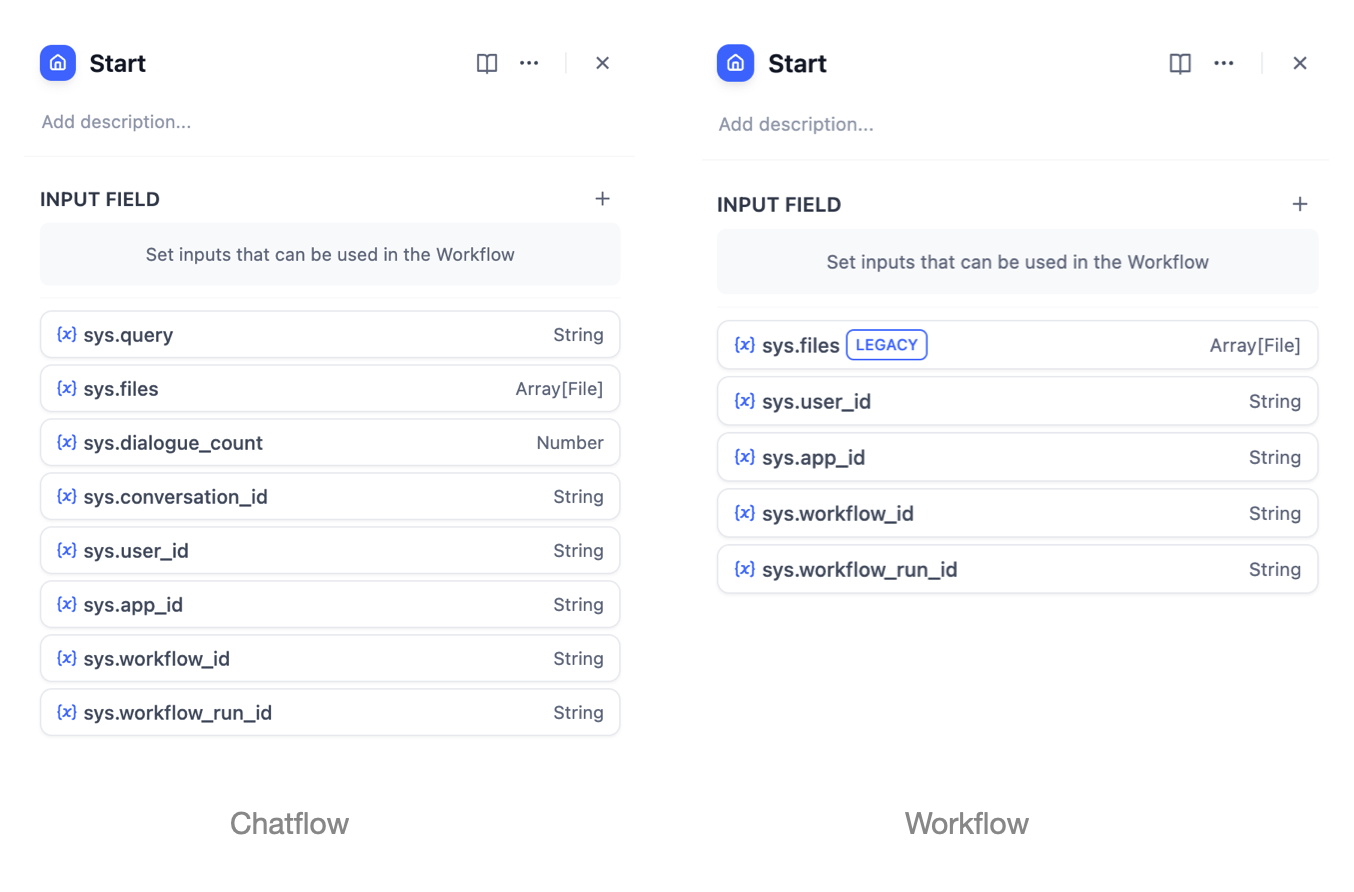
입력 필드 #
입력 필드는 사용자에게 추가 정보를 입력하라는 메시지를 표시하기 위해 애플리케이션 개발자가 구성합니다.예를 들어, 주간 보고서 애플리케이션에서 사용자는 이름, 근무 기간, 근무 세부 정보와 같은 배경 정보를 특정 형식으로 제공해야 할 수 있습니다. 이러한 예비 정보는 LLM이 더 높은 품질의 답변을 생성하는 데 도움이 됩니다.6가지 유형의 입력 변수가 지원되며, 모두 필요에 따라 설정할 수 있습니다.
- 텍스트: 사용자가 입력하는 짧은 텍스트로, 최대 길이는 256자입니다.
- 문단: 긴 텍스트로, 사용자가 더 긴 내용을 입력할 수 있습니다.
- 선택: 개발자가 설정한 고정 옵션입니다. 사용자는 사전 설정된 옵션에서만 선택할 수 있으며 사용자 정의 콘텐츠를 입력할 수 없습니다.
- 숫자: 숫자 입력만 허용합니다.
- 단일 파일: 사용자가 단일 파일을 업로드할 수 있습니다. 문서 유형, 이미지, 오디오, 비디오 및 기타 파일 유형을 지원합니다. 사용자는 로컬로 업로드하거나 파일 URL을 붙여넣을 수 있습니다. 자세한 사용 방법은 파일 업로드를 참조하세요.
- 파일 목록: 사용자가 파일을 일괄 업로드할 수 있습니다. 문서 유형, 이미지, 오디오, 비디오 및 기타 파일 유형을 지원합니다. 사용자는 로컬로 업로드하거나 파일 URL을 붙여넣을 수 있습니다. 자세한 사용법은 파일 업로드를 참조하세요.
Dify에 내장된 문서 추출 노드는 특정 문서 형식만 처리할 수 있습니다. 이미지, 오디오 또는 비디오 파일을 처리하려면 외부 데이터 도구를 참조하여 해당 파일 처리 노드를 설정하세요.
설정이 완료되면 사용자는 애플리케이션 사용 전에 LLM에 필요한 정보를 제공하도록 안내됩니다. 더 많은 정보를 제공할수록 LLM의 질의응답 효율성이 향상됩니다.
시스템 변수 #
시스템 변수는 Chatflow/Workflow 애플리케이션에서 미리 설정된 시스템 수준 매개변수로, 애플리케이션의 다른 노드에서 전역적으로 접근할 수 있습니다. 시스템 변수는 일반적으로 다중 턴 대화 애플리케이션 구축, 애플리케이션 로그 수집 및 데이터 모니터링, 다양한 애플리케이션 및 사용자 간의 사용 행동 기록과 같은 고급 개발 시나리오에서 사용됩니다.워크플로워크플로 애플리케이션은 다음과 같은 시스템 변수를 제공합니다.
| 변수 이름 | 데이터 유형 | 설명 | 노트 |
|---|---|---|---|
sys.files[유산] | 배열[파일] | 파일 매개변수는 사용자가 애플리케이션을 처음 사용할 때 업로드한 이미지를 저장합니다. | 애플리케이션 오케스트레이션 페이지 오른쪽 상단의 “기능” 섹션에서 이미지 업로드 기능을 활성화해야 합니다. |
sys.user_id | 끈 | 사용자 ID는 워크플로 애플리케이션을 사용할 때 각 사용자에게 자동으로 할당되는 고유 식별자로, 서로 다른 대화 사용자를 구별하는 데 사용됩니다. | |
sys.app_id | 끈 | 애플리케이션 ID는 시스템에서 각 Workflow 애플리케이션에 할당한 고유 식별자로, 다양한 애플리케이션을 구별하고 현재 애플리케이션의 기본 정보를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 다양한 Workflow 애플리케이션을 구별하고 찾을 수 있습니다. |
sys.workflow_id | 끈 | Workflow ID는 현재 Workflow 애플리케이션에 포함된 모든 노드 정보를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 워크플로 내에서 노드 정보를 추적하고 기록할 수 있습니다. |
sys.workflow_run_id | 끈 | Workflow 애플리케이션 실행 ID는 Workflow 애플리케이션의 실행 상태를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 애플리케이션의 실행 기록을 추적할 수 있습니다. |
챗플로우Chatflow 애플리케이션은 다음과 같은 시스템 변수를 제공합니다.
| 변수 이름 | 데이터 유형 | 설명 | 노트 |
|---|---|---|---|
sys.query | 끈 | 사용자가 대화 상자에 입력한 초기 내용 | |
sys.files | 배열[파일] | 사용자가 대화 상자에 업로드한 이미지 | 애플리케이션 오케스트레이션 페이지 오른쪽 상단의 “기능” 섹션에서 이미지 업로드 기능을 활성화해야 합니다. |
sys.dialogue_count | 숫자 | Chatflow 애플리케이션과 사용자 상호작용 중 대화 턴 수입니다. 각 턴마다 자동으로 1씩 증가합니다. if-else 노드와 함께 사용하여 풍부한 분기 논리를 생성할 수 있습니다. 예를 들어, 대화의 X번째 턴에서 대화 기록을 검토하고 분석을 제공합니다. | |
sys.conversation_id | 끈 | 대화 상호작용 세션에 대한 고유 식별자로, 모든 관련 메시지를 동일한 대화로 그룹화하여 LLM이 동일한 주제와 맥락에서 대화를 계속할 수 있도록 보장합니다. | |
sys.user_id | 끈 | 각 애플리케이션 사용자에게 할당된 고유 식별자로, 다양한 대화 사용자를 구별하는 데 사용됩니다. | |
sys.app_id | 끈 | 애플리케이션 ID는 시스템에서 각 Workflow 애플리케이션에 할당한 고유 식별자로, 다양한 애플리케이션을 구별하고 현재 애플리케이션의 기본 정보를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 다양한 Workflow 애플리케이션을 구별하고 찾을 수 있습니다. |
sys.workflow_id | 끈 | Workflow ID는 현재 Workflow 애플리케이션에 포함된 모든 노드 정보를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 워크플로 내에서 노드 정보를 추적하고 기록할 수 있습니다. |
sys.workflow_run_id | 끈 | Workflow 애플리케이션 실행 ID는 Workflow 애플리케이션의 실행 상태를 기록하는 데 사용됩니다. | 개발 기능이 있는 사용자의 경우 이 매개변수를 사용하여 애플리케이션의 실행 기록을 추적할 수 있습니다. |
End(끝) #
정의 #
워크플로의 최종 출력 내용을 정의합니다. 모든 워크플로는 실행이 완료된 후 최종 결과를 출력하기 위해 최소 하나의 종료 노드가 필요합니다.종료 노드는 프로세스의 종료 지점입니다. 이후 노드를 추가할 수 없습니다. 워크플로 애플리케이션에서는 종료 노드에 도달했을 때만 결과가 출력됩니다. 프로세스에 조건 분기가 있는 경우 여러 종료 노드를 정의해야 합니다.최종 노드는 하나 이상의 출력 변수를 선언해야 하며, 이 변수는 모든 상류 노드의 출력 변수를 참조할 수 있습니다.
Chatflow에서는 종료 노드가 지원되지 않습니다.
2가지 시나리오 #
다음의 긴 스토리 생성 워크플로 에서 , 종료 노드에서 선언된 변수는 Output상위 코드 노드의 출력입니다. 즉, 코드 노드가 실행을 완료하고 코드의 실행 결과를 출력하면 워크플로가 종료됩니다.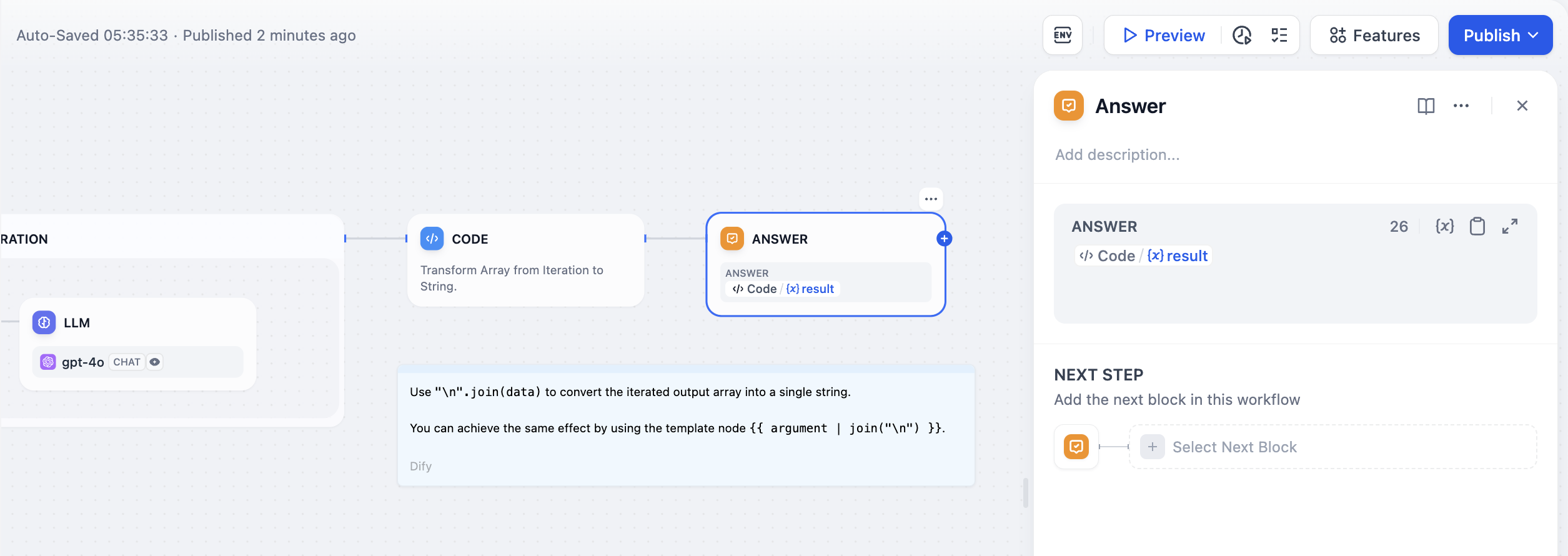 단일 경로 실행 예:
단일 경로 실행 예: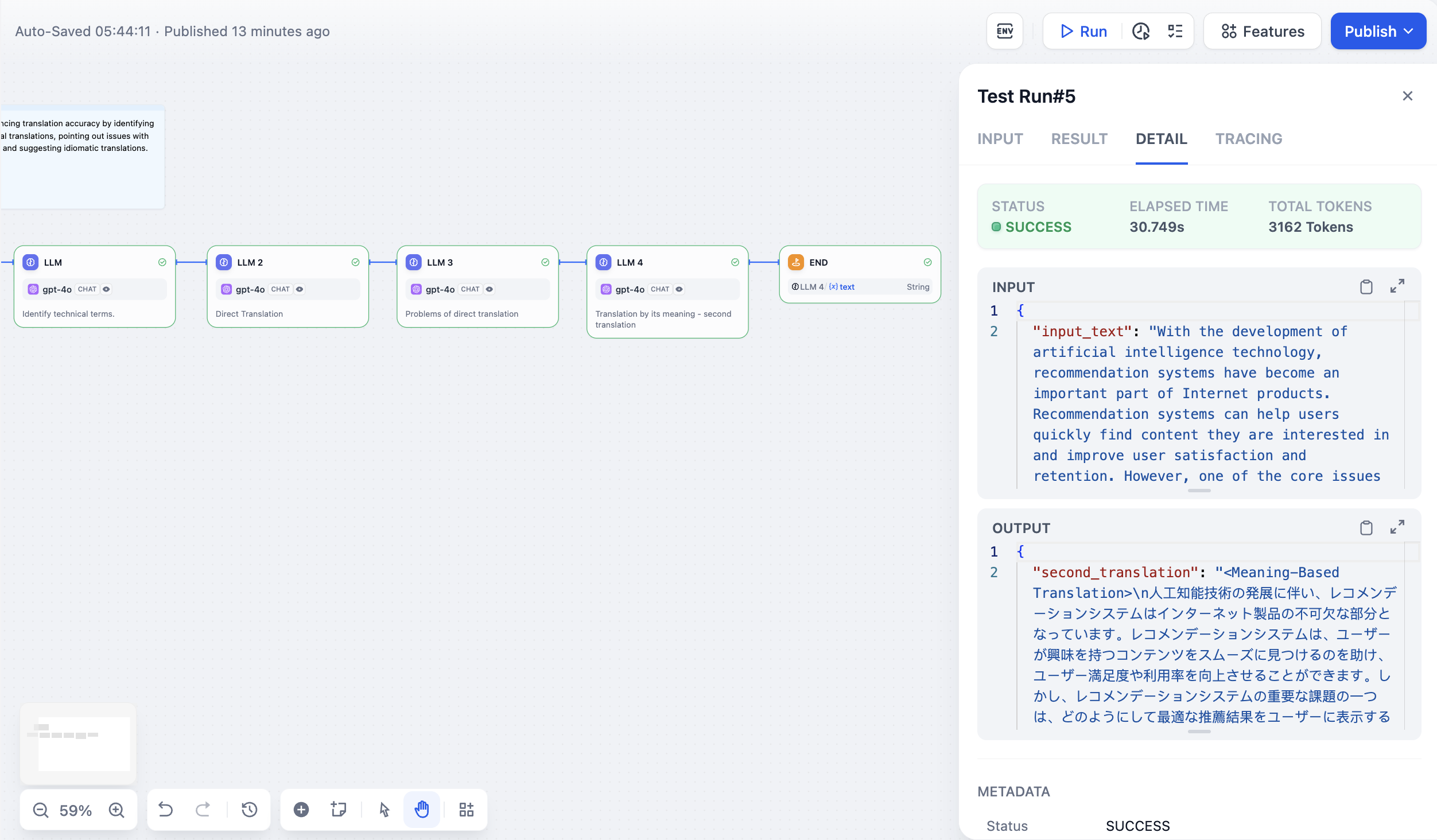 다중 경로 실행 예:
다중 경로 실행 예:
Answer(답변) #
Chatflow 프로세스에서 답변 내용 정의. 텍스트 편집기에서는 답변 형식을 유연하게 설정할 수 있습니다. 여기에는 고정된 텍스트 블록을 작성하거나, 이전 단계의 출력 변수를 답변 내용으로 활용하거나, 사용자 지정 텍스트를 변수와 병합하여 응답을 생성하는 것이 포함됩니다.답변 노드는 언제든지 원활하게 통합되어 대화 응답에 동적으로 콘텐츠를 전달할 수 있습니다. 이 설정은 실시간 편집 구성 모드를 지원하여 텍스트와 이미지 콘텐츠를 함께 정렬할 수 있습니다. 구성은 다음과 같습니다.
- 언어 모델(LLM) 노드에서 답변 내용을 출력합니다.
- 생성된 이미지 출력.
- 일반 텍스트를 출력합니다.
예제 1: 일반 텍스트를 출력합니다.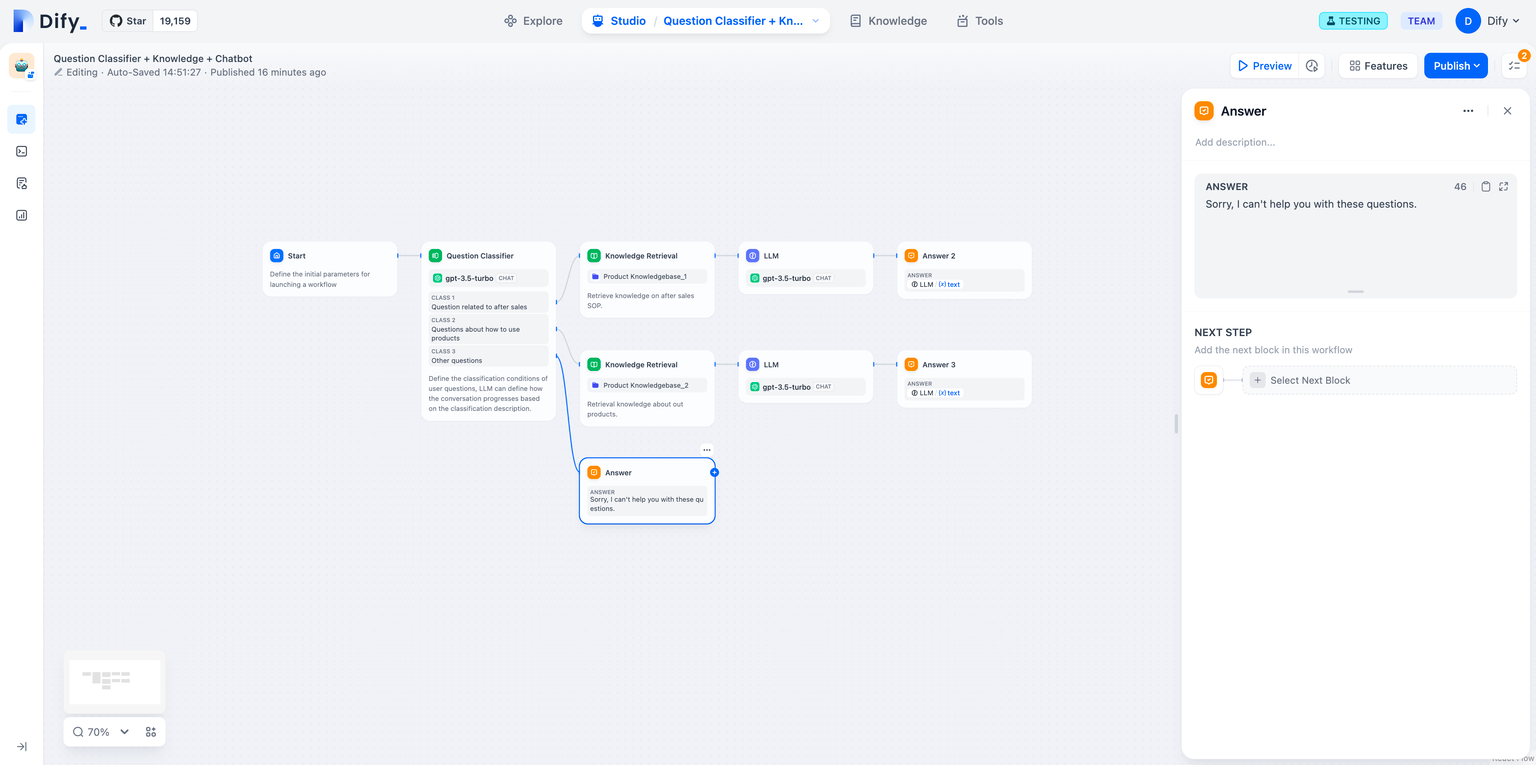 예시 2: 출력 이미지와 LLM 응답.
예시 2: 출력 이미지와 LLM 응답.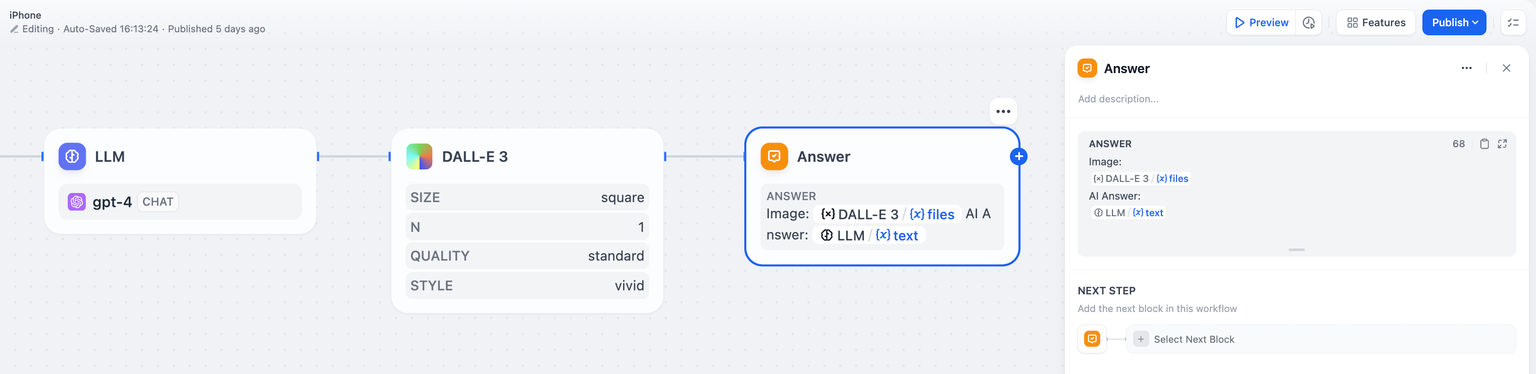
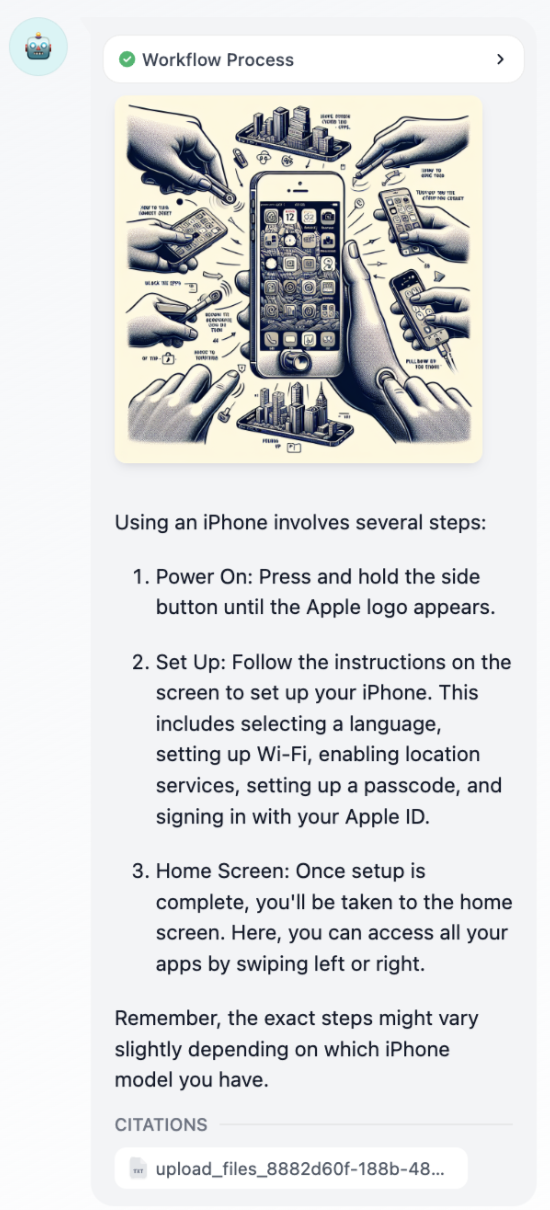
LLM #
정의 #
“시작” 노드에서 사용자가 입력한 정보(자연어, 업로드된 파일 또는 이미지)를 처리하고 효과적인 응답 정보를 제공하기 위해 대규모 언어 모델의 기능을 활용합니다.
시나리오 #
LLM은 Chatflow/Workflow의 핵심 노드로, 대규모 언어 모델의 대화형/생성형/분류형/처리 기능을 활용하여 주어진 프롬프트에 따라 광범위한 작업을 처리하며 워크플로의 여러 단계에서 사용할 수 있습니다.
- 의도 인식 : 고객 서비스 시나리오에서 사용자 문의를 식별하고 분류하여 다운스트림 프로세스를 안내합니다.
- 텍스트 생성 : 콘텐츠 생성 시나리오에서 주제와 키워드를 기반으로 관련 텍스트를 생성합니다.
- 콘텐츠 분류 : 이메일 일괄 처리 시나리오에서 문의/불만/스팸과 같은 이메일을 자동으로 분류합니다.
- 텍스트 변환 : 번역 시나리오에서 사용자가 제공한 텍스트를 지정된 언어로 번역하는 작업입니다.
- 코드 생성 : 프로그래밍 지원 시나리오에서 사용자 요구 사항에 따라 특정 비즈니스 코드를 생성하거나 테스트 사례를 작성합니다.
- RAG : 지식 기반 Q&A 시나리오에서 검색된 관련 지식을 재구성하여 사용자 질문에 답합니다.
- 이미지 이해 : 시각 기능을 갖춘 다중 모달 모델을 사용하여 이미지 내 정보에 대한 질문을 이해하고 답합니다.
- 파일 분석 : 파일 처리 시나리오에서 LLM을 사용하여 파일 내에 포함된 정보를 인식하고 분석합니다.
적절한 모델을 선택하고 프롬프트를 작성하면 Chatflow/Workflow 내에서 강력하고 안정적인 솔루션을 구축할 수 있습니다.
구성 방법 #
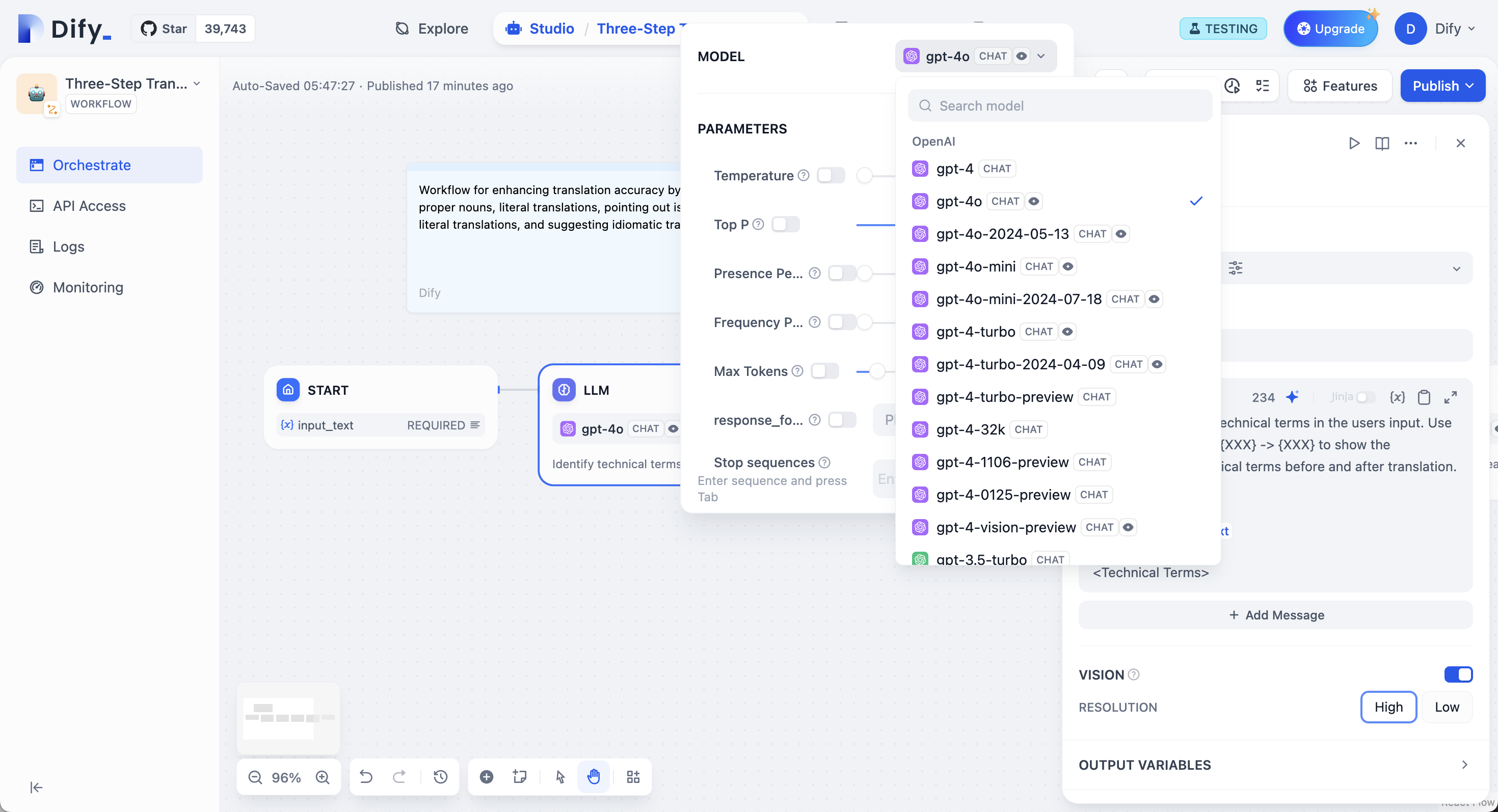
구성 단계:
- 모델 선택 : Dify는 OpenAI의 GPT 시리즈, Anthropic의 Claude 시리즈, Google의 Gemini 시리즈를 포함한 주요 글로벌 모델을 지원합니다. 모델 선택은 추론 성능, 비용, 응답 속도, 컨텍스트 윈도우 등에 따라 달라집니다. 시나리오 요구 사항과 작업 유형에 따라 적합한 모델을 선택해야 합니다.
- 모델 매개변수 구성 : 모델 매개변수는 온도, TopP, 최대 토큰, 응답 형식 등과 같은 생성 결과를 제어합니다. 선택을 용이하게 하기 위해 시스템은 Creative, Balanced, Precise의 세 가지 사전 설정 매개변수 세트를 제공합니다.
- 프롬프트 작성 : LLM 노드는 사용하기 쉬운 프롬프트 작성 페이지를 제공합니다. 채팅 모델이나 완성 모델을 선택하면 다양한 프롬프트 작성 구조가 표시됩니다.
- 고급 설정 : 메모리를 활성화하고, 메모리 창을 설정하고, 더 복잡한 프롬프트에 Jinja-2 템플릿 언어를 사용할 수 있습니다.
처음으로 Dify를 사용하는 경우 LLM 노드에서 모델을 선택하기 전에 시스템 설정-모델 공급자 에서 모델 구성을 완료해야 합니다.
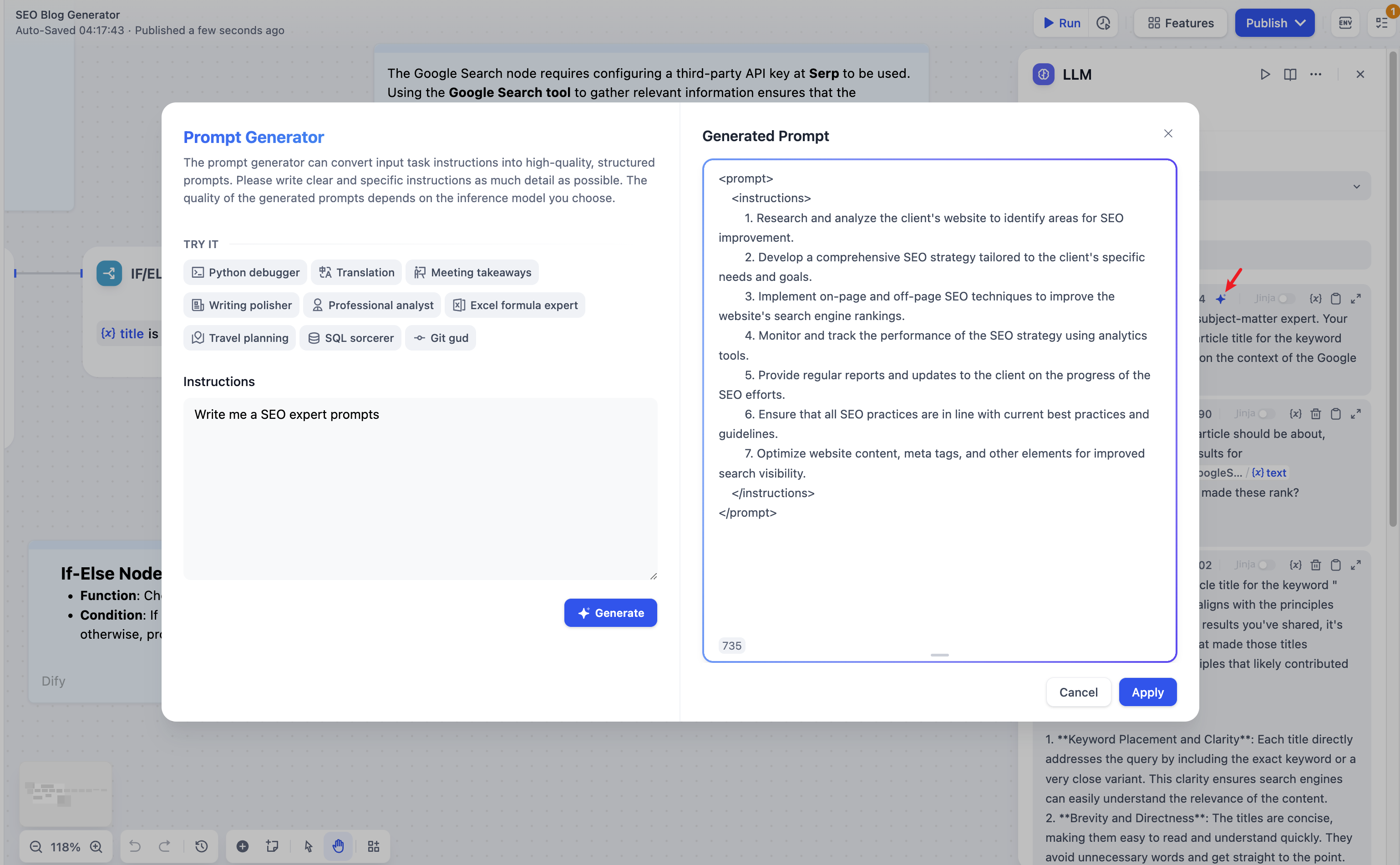
글쓰기 프롬프트 #
LLM 노드에서 모델 입력 프롬프트를 사용자 지정할 수 있습니다. 채팅 모델을 선택하면 시스템/사용자/비서 섹션을 사용자 지정할 수 있습니다.프롬프트 생성기효과적인 시스템 프롬프트(시스템)를 생각해내는 데 어려움을 겪고 있다면 프롬프트 생성기를 사용하여 AI 기능을 활용하여 특정 비즈니스 시나리오에 적합한 프롬프트를 빠르게 만들 수 있습니다.
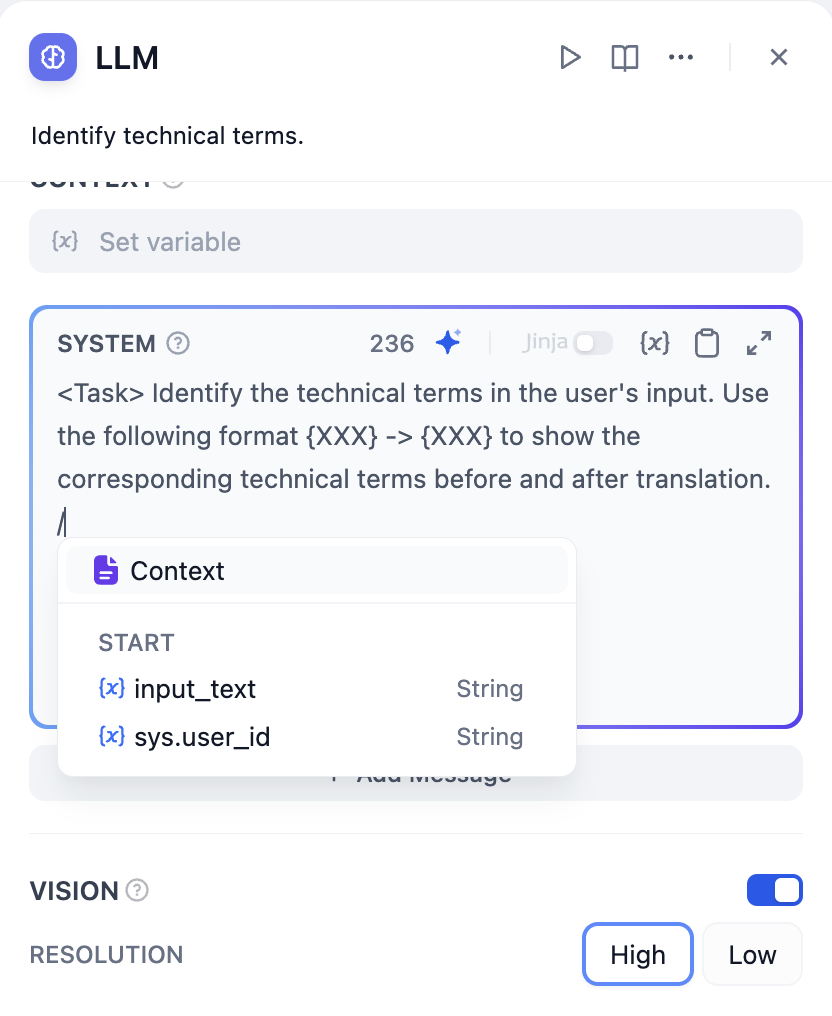
프롬프트 편집기에서 또는 를 입력하여 변수 삽입 메뉴를 불러와 특수 변수 블록 이나 업스트림 노드 변수를 컨텍스트 콘텐츠로 프롬프트에 삽입 할 수 있습니다./{
특수 변수에 대한 설명 #
컨텍스트 변수컨텍스트 변수는 LLM 노드 내에서 정의되는 특수한 유형의 변수로, 외부에서 검색된 텍스트 콘텐츠를 프롬프트에 삽입하는 데 사용됩니다.

공통 지식 기반 Q&A 애플리케이션에서 지식 검색의 다운스트림 노드는 일반적으로 LLM 노드입니다. 지식 검색의 출력 변수는 연관 및 할당을 위해 LLM 노드 내의 컨텍스트 변수result 에 구성되어야 합니다 . 연관 후, 프롬프트의 적절한 위치에 컨텍스트 변수를 삽입하면 외부에서 검색된 지식을 프롬프트에 통합할 수 있습니다.이 변수는 LLM 응답을 위한 프롬프트 컨텍스트에 도입된 외부 지식으로 사용될 수 있을 뿐만 아니라 세그먼트 참조 정보가 포함된 데이터 구조로 인해 애플리케이션의 인용 및 귀속 기능도 지원합니다.
컨텍스트 변수가 시작 노드의 문자열 유형 변수와 같이 상위 노드의 공통 변수와 연결된 경우 컨텍스트 변수는 여전히 외부 지식으로 사용할 수 있지만 인용 및 귀속 기능은 비활성화됩니다.파일 변수Claude 3.5 Sonnet 과 같은 일부 LLM은 이제 파일 내용의 직접 처리를 지원하여 프롬프트에서 파일 변수를 사용할 수 있습니다. 잠재적인 문제를 방지하려면 애플리케이션 개발자는 파일 변수를 사용하기 전에 LLM 공식 웹사이트에서 지원되는 파일 유형을 확인해야 합니다.
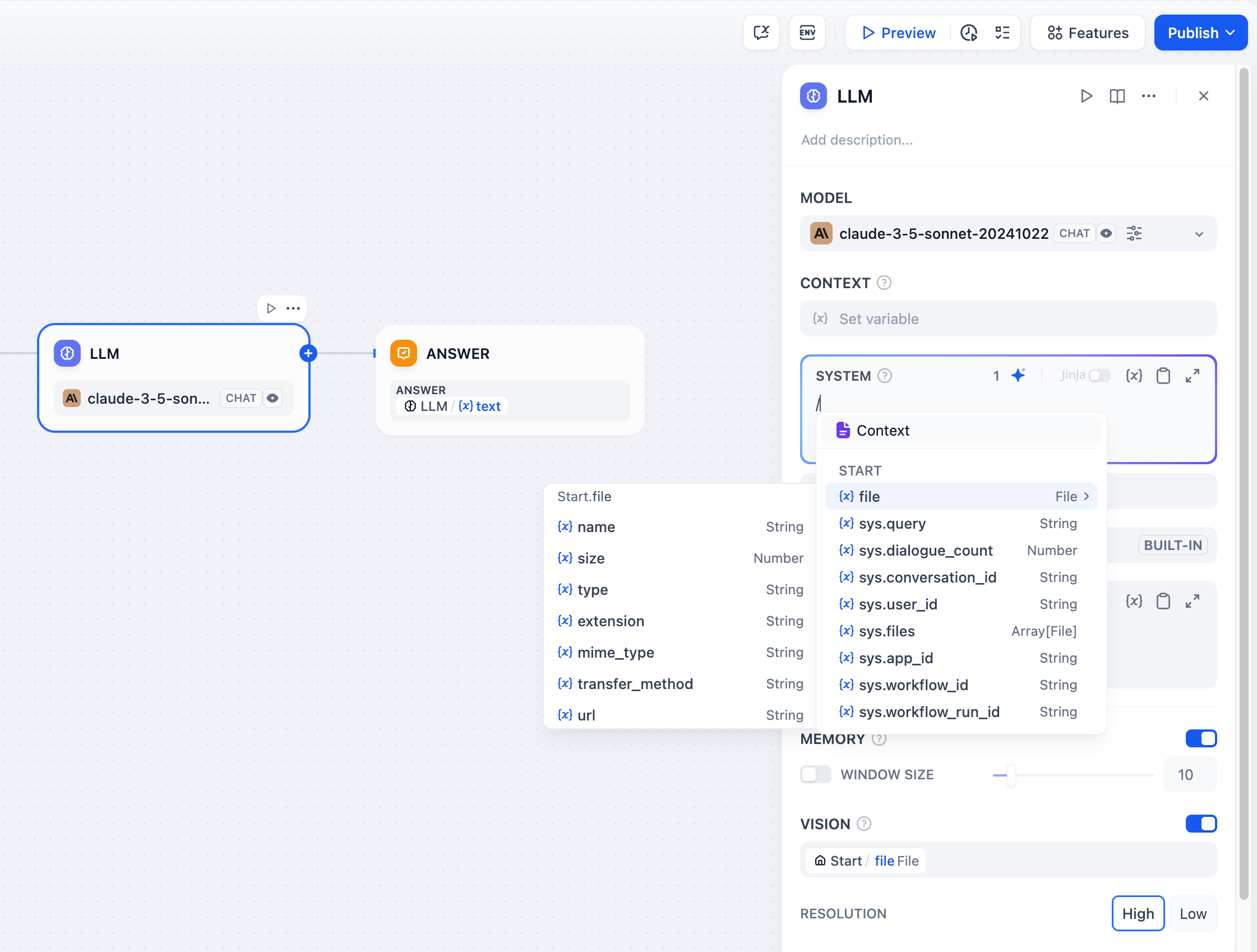
파일 업로드 기능이 있는 Chatflow/Workflow 애플리케이션을 구축하는 방법에 대한 지침은 파일 업로드를 참조하세요 .
대화 내역텍스트 완성 모델(예: gpt-3.5-turbo-Instruct)에서 대화 기억을 구현하기 위해 Dify는 기존 프롬프트 전문가 모드(단종) 에서 대화 기록 변수를 설계했습니다 . 이 변수는 Chatflow의 LLM 노드로 이관되어 AI와 사용자 간의 채팅 기록을 프롬프트에 삽입하는 데 사용되며, 이를 통해 LLM이 대화의 맥락을 이해하는 데 도움을 줍니다.
대화 기록 변수는 널리 사용되지 않으며 Chatflow에서 텍스트 완성 모델을 선택할 때만 삽입할 수 있습니다.
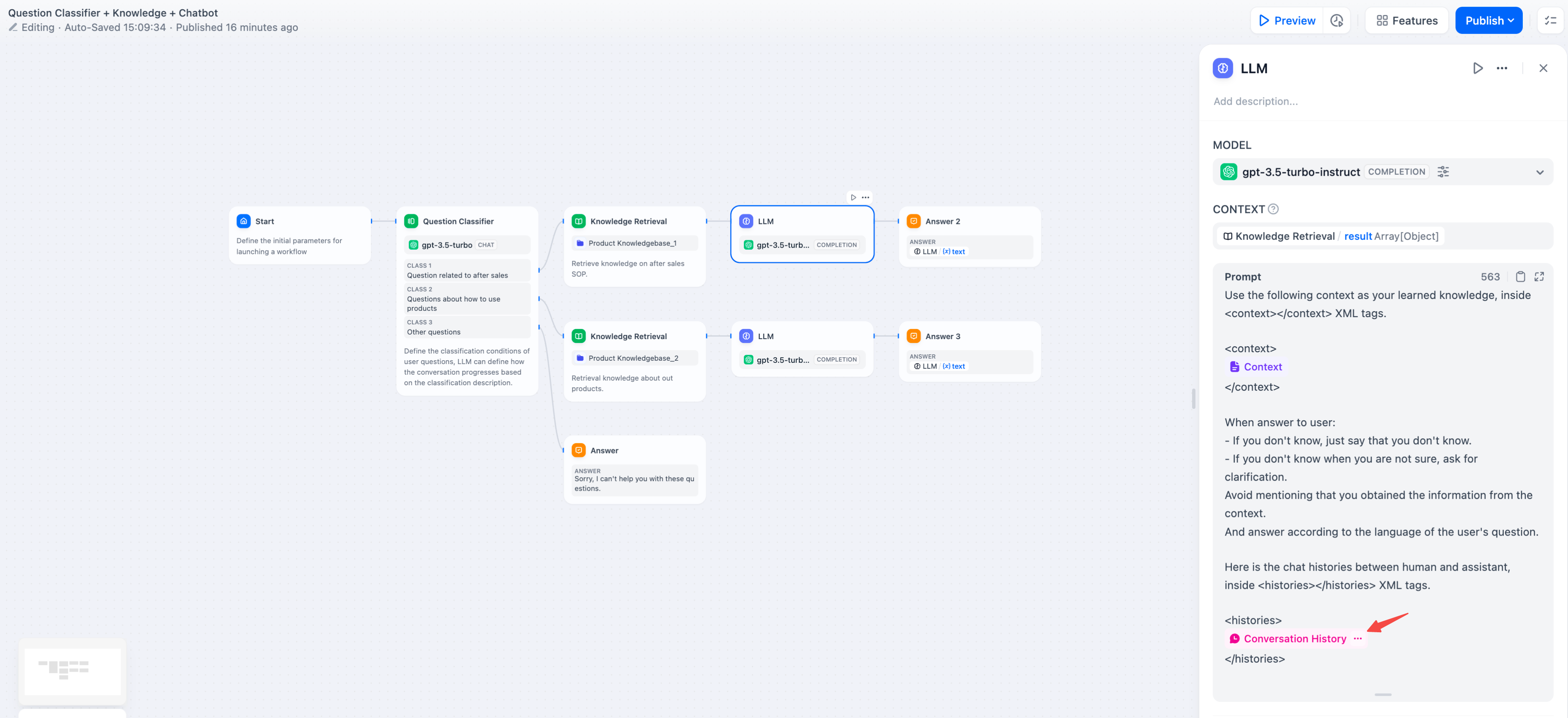
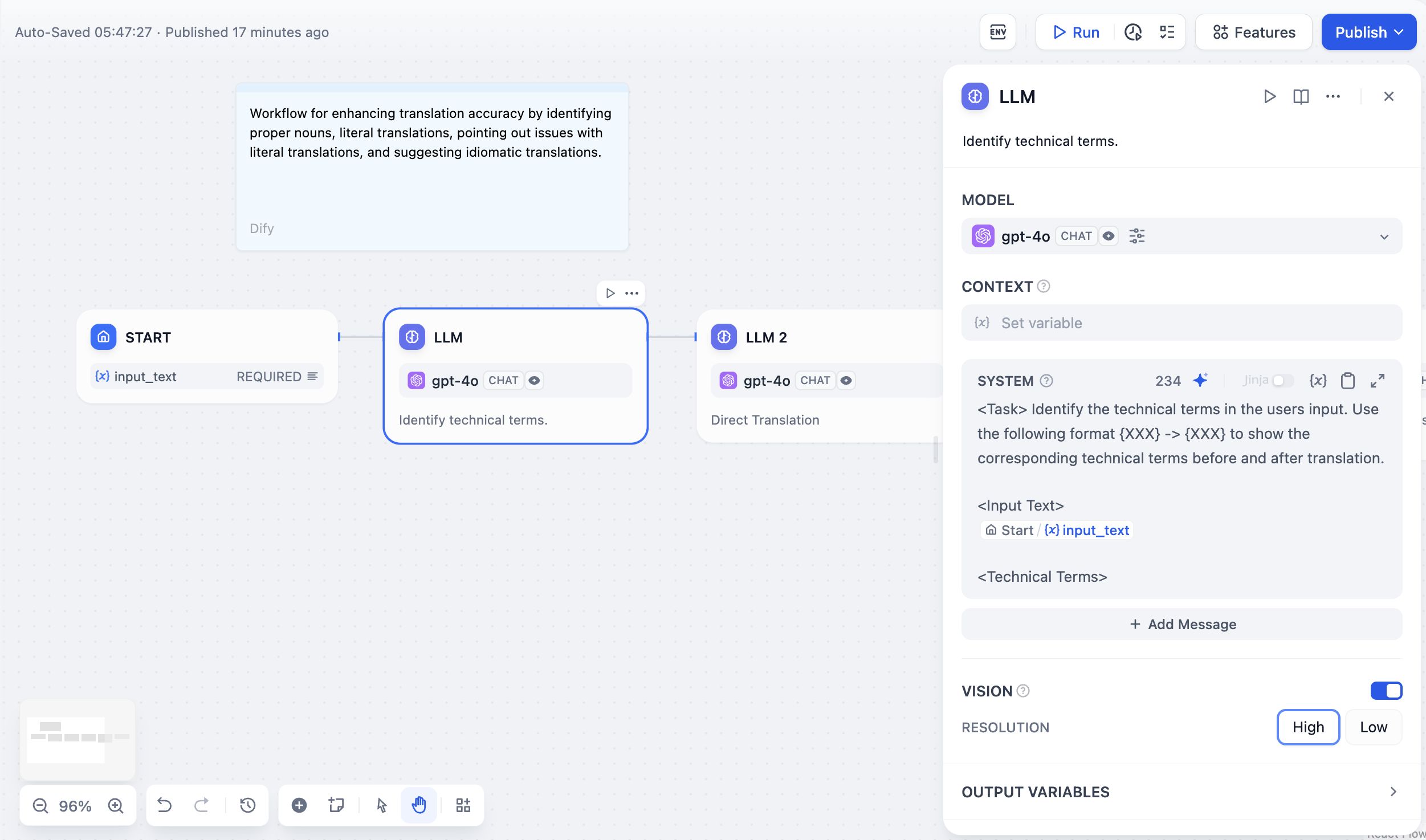
모델 매개변수모델의 매개변수는 모델의 출력에 영향을 미칩니다. 모델마다 매개변수가 다릅니다. 다음 그림은 의 매개변수 목록을 보여줍니다 gpt-4.
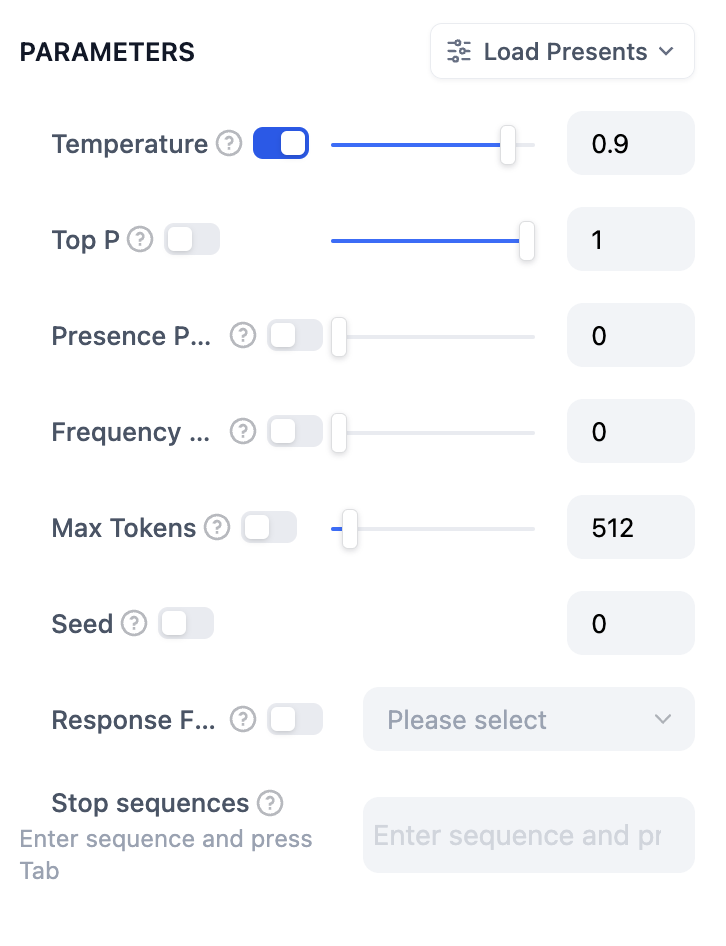
주요 매개변수 용어는 다음과 같이 설명됩니다.온도 : 일반적으로 0과 1 사이의 값으로, 무작위성을 제어합니다. 온도가 0에 가까울수록 결과가 더 확실하고 반복적입니다. 1에 가까울수록 결과가 더 무작위적입니다.상위 P : 결과의 다양성을 제어합니다. 모델은 확률을 기반으로 후보 단어를 선택하여 누적 확률이 사전 설정된 임계값 P를 초과하지 않도록 합니다.존재 페널티 : 이미 생성된 콘텐츠에 페널티를 부과하여 동일한 엔터티 또는 정보의 반복 생성을 줄이는 데 사용됩니다. 이를 통해 모델이 새롭거나 다른 콘텐츠를 생성하도록 유도합니다. 매개변수 값이 증가할수록 후속 세대에서 이미 생성된 콘텐츠에 더 큰 페널티가 적용되어 콘텐츠 반복 생성 가능성이 낮아집니다.빈도 페널티 : 너무 자주 등장하는 단어나 구의 생성 확률을 낮춰 페널티를 부과합니다. 매개변수 값이 증가할수록 자주 등장하는 단어나 구에 더 큰 페널티가 부과됩니다. 매개변수 값이 높을수록 이러한 단어의 빈도가 감소하여 텍스트의 어휘 다양성이 증가합니다.이러한 매개변수가 무엇인지 이해가 안 되면 사전 설정을 불러와서 창의적, 균형적, 정밀함의 세 가지 사전 설정 중에서 선택할 수 있습니다.
고급 기능 #
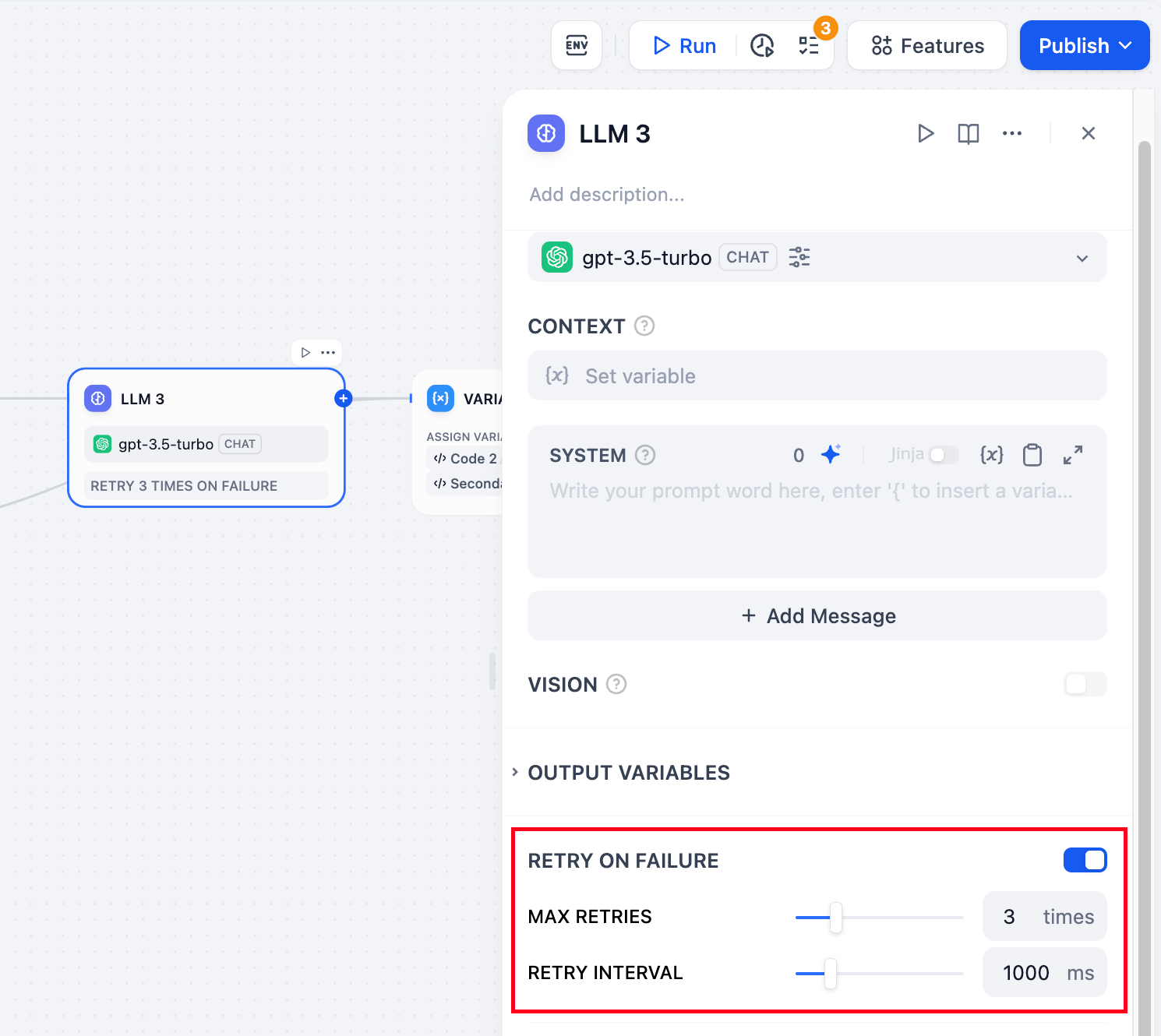
메모리 : 이 기능을 활성화하면 의도 분류기에 대한 각 입력에 대화의 채팅 기록이 포함되어 LLM이 맥락을 이해하고 대화형 대화에서 질문 이해도를 향상시키는 데 도움이 됩니다.메모리 창 : 메모리 창이 닫히면 시스템은 모델의 컨텍스트 창에 따라 전달되는 채팅 기록의 양을 동적으로 필터링합니다. 창이 열려 있으면 사용자는 전달되는 채팅 기록의 양(숫자 기준)을 정확하게 제어할 수 있습니다.대화 역할 이름 설정 : 모델 학습 단계의 차이로 인해, 각 모델은 역할 이름 지침을 다르게 준수합니다(예: 사람/비서, 사람/AI, 사람/비서 등). 시스템은 여러 모델의 신속한 응답 효과에 맞춰 대화 역할 이름 설정을 제공합니다. 역할 이름을 수정하면 대화 기록의 역할 접두사가 변경됩니다.Jinja-2 템플릿 : LLM 프롬프트 편집기는 Jinja-2 템플릿 언어를 지원하여, 이 강력한 Python 템플릿 언어를 활용하여 가벼운 데이터 변환 및 논리 처리를 수행할 수 있습니다. 공식 문서 를 참조하세요 .실패 시 재시도 : 노드에서 발생하는 일부 예외의 경우, 일반적으로 노드를 다시 재시도하는 것으로 충분합니다. 오류 재시도 기능이 활성화되어 있으면 오류 발생 시 노드는 미리 설정된 전략에 따라 자동으로 재시도합니다. 최대 재시도 횟수와 각 재시도 간격을 조정하여 재시도 전략을 설정할 수 있습니다.
- 최대 재시도 횟수는 10회입니다.
- 최대 재시도 간격은 5000ms입니다.
오류 처리 : 현재 노드에 장애가 발생했을 때 메인 프로세스를 중단시키지 않고 오류 메시지를 표시하거나, 백업 경로를 통해 작업을 계속 진행할 수 있는 다양한 노드 오류 처리 전략을 제공합니다. 자세한 내용은 오류 처리를 참조하십시오 .구조화된 출력 : LLM이 사용 가능하고 안정적이며 예측 가능한 형식으로 데이터를 반환하도록 보장하여 사용자가 LLM 노드가 데이터를 반환하는 방식을 정확하게 제어할 수 있도록 돕습니다.
JSON 스키마 편집기
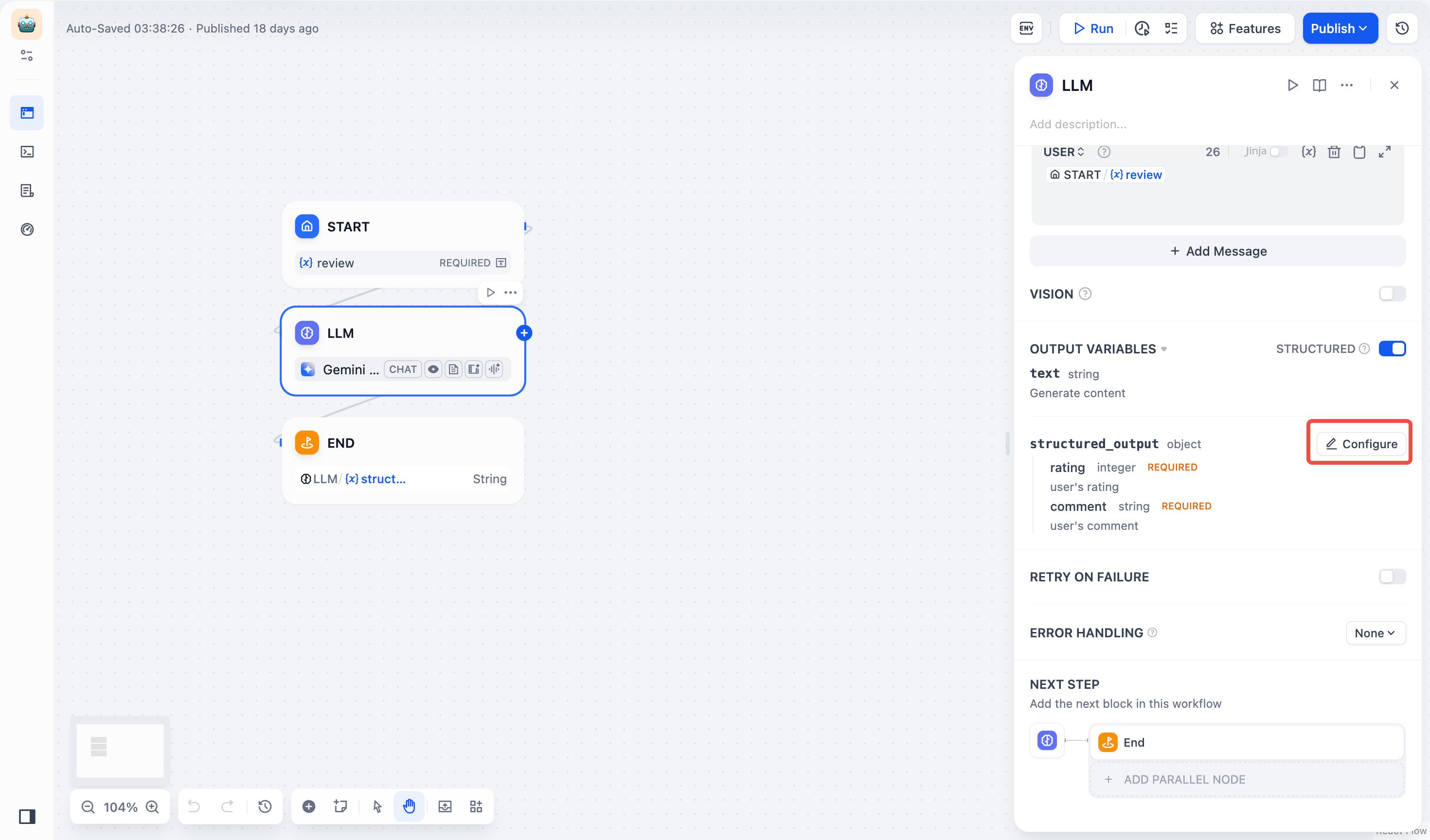
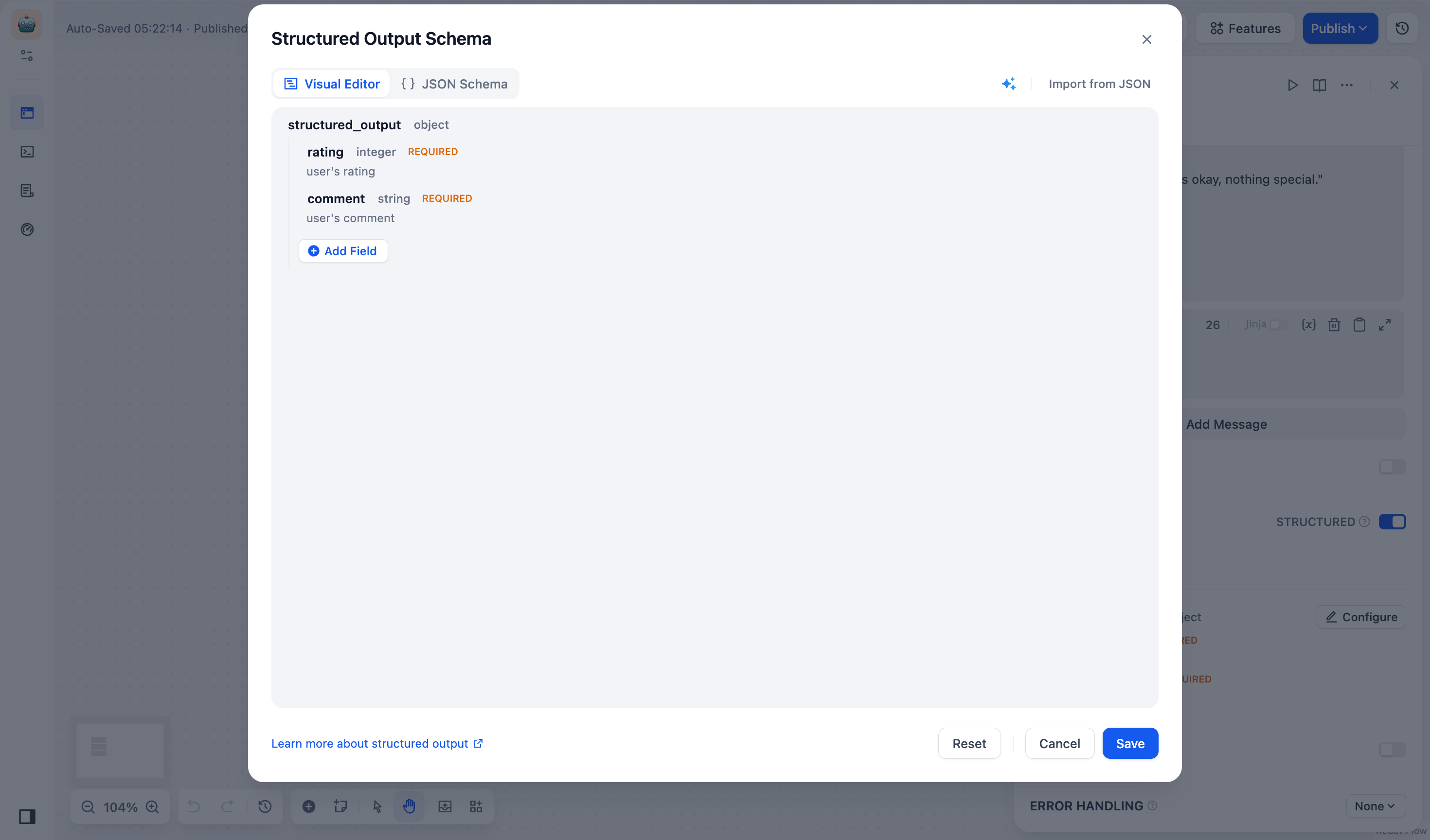
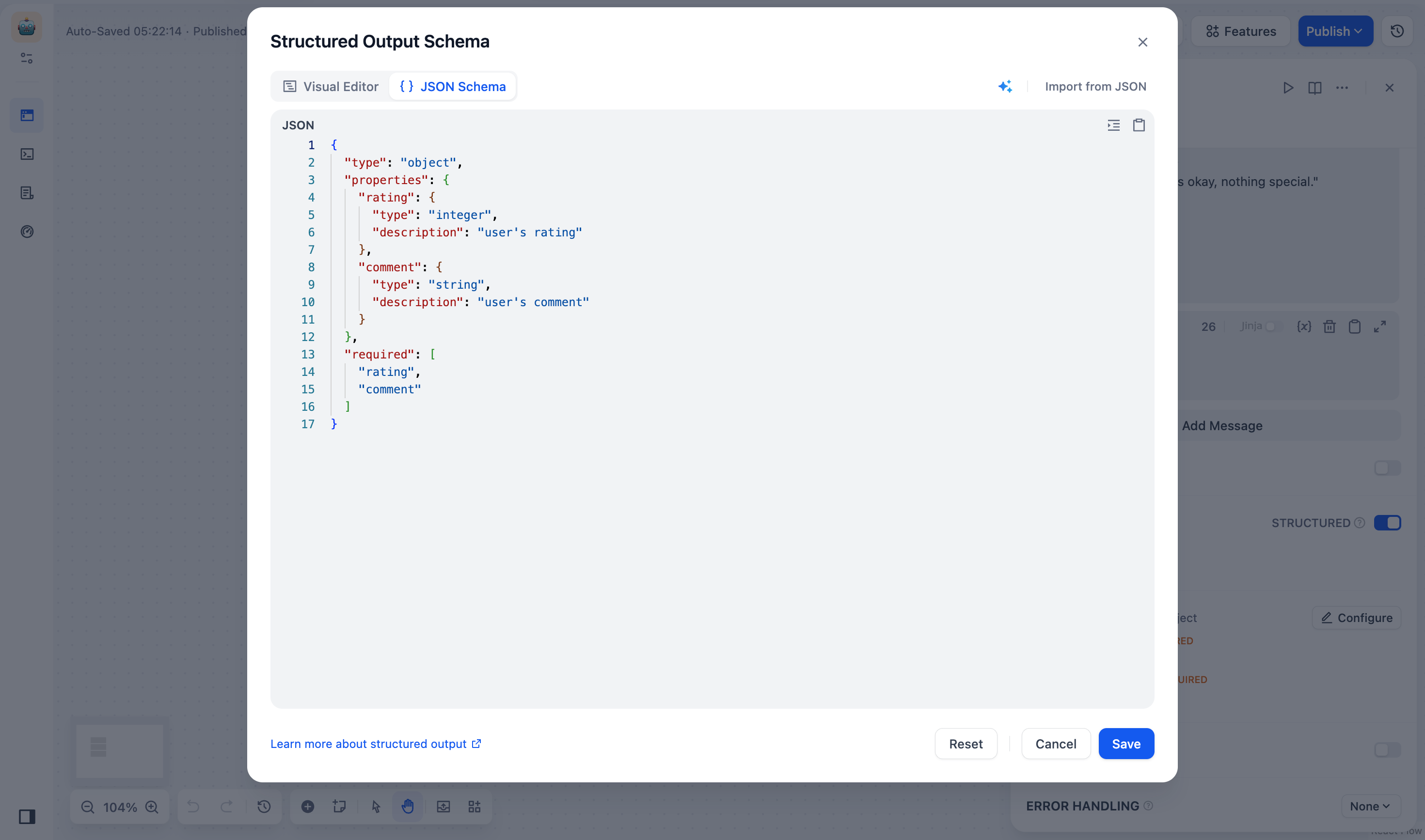
사용 사례 #
- 지식 기반 콘텐츠 읽기
지능형 고객 서비스 애플리케이션을 구축하는 것과 같이 워크플로 애플리케이션이 ” 지식 기반 ” 콘텐츠를 읽을 수 있도록 하려면 다음 단계를 따르세요.
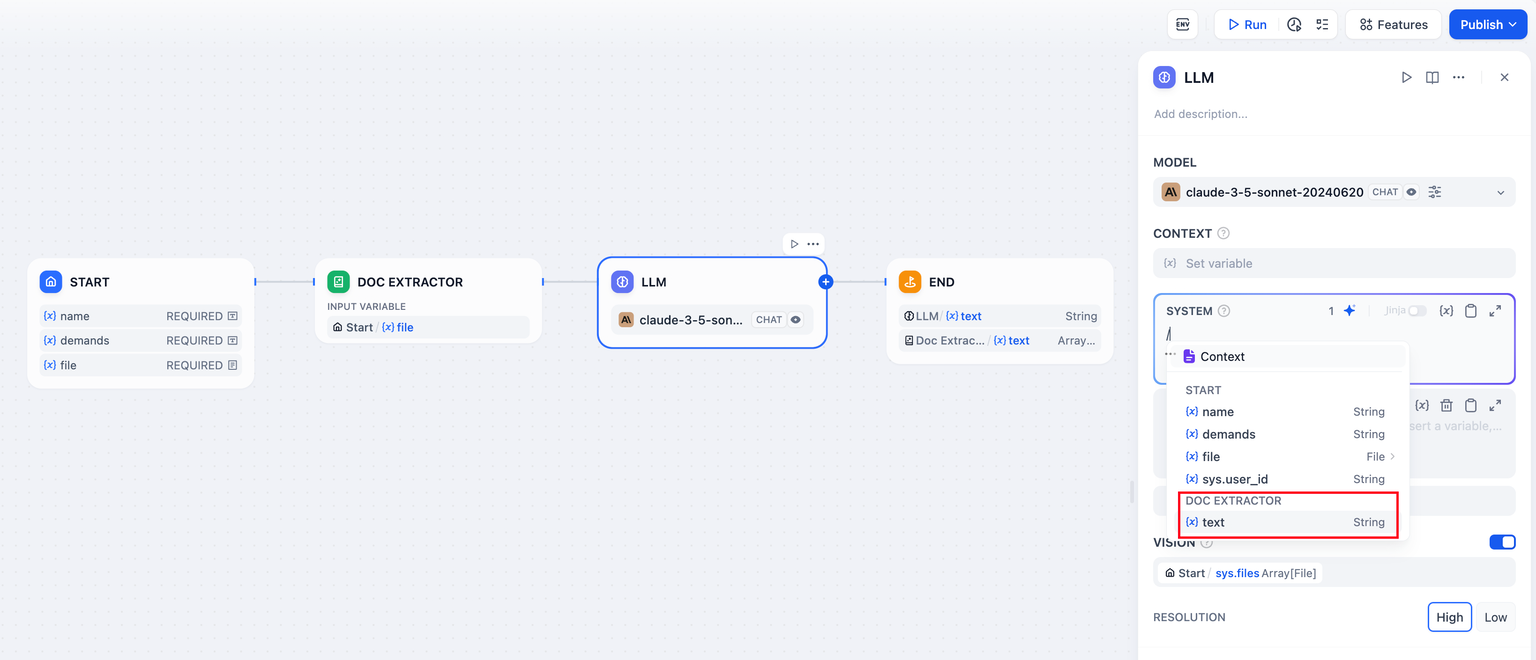
- LLM 노드 상류에 지식 기반 검색 노드를 추가합니다.
- 지식 검색 노드의 출력 변수를 LLM 노드의 컨텍스트 변수 에 채웁니다 .
result - LLM이 지식 기반 내의 텍스트를 읽을 수 있는 기능을 제공하려면 애플리케이션 프롬프트에 컨텍스트 변수를 삽입합니다 .
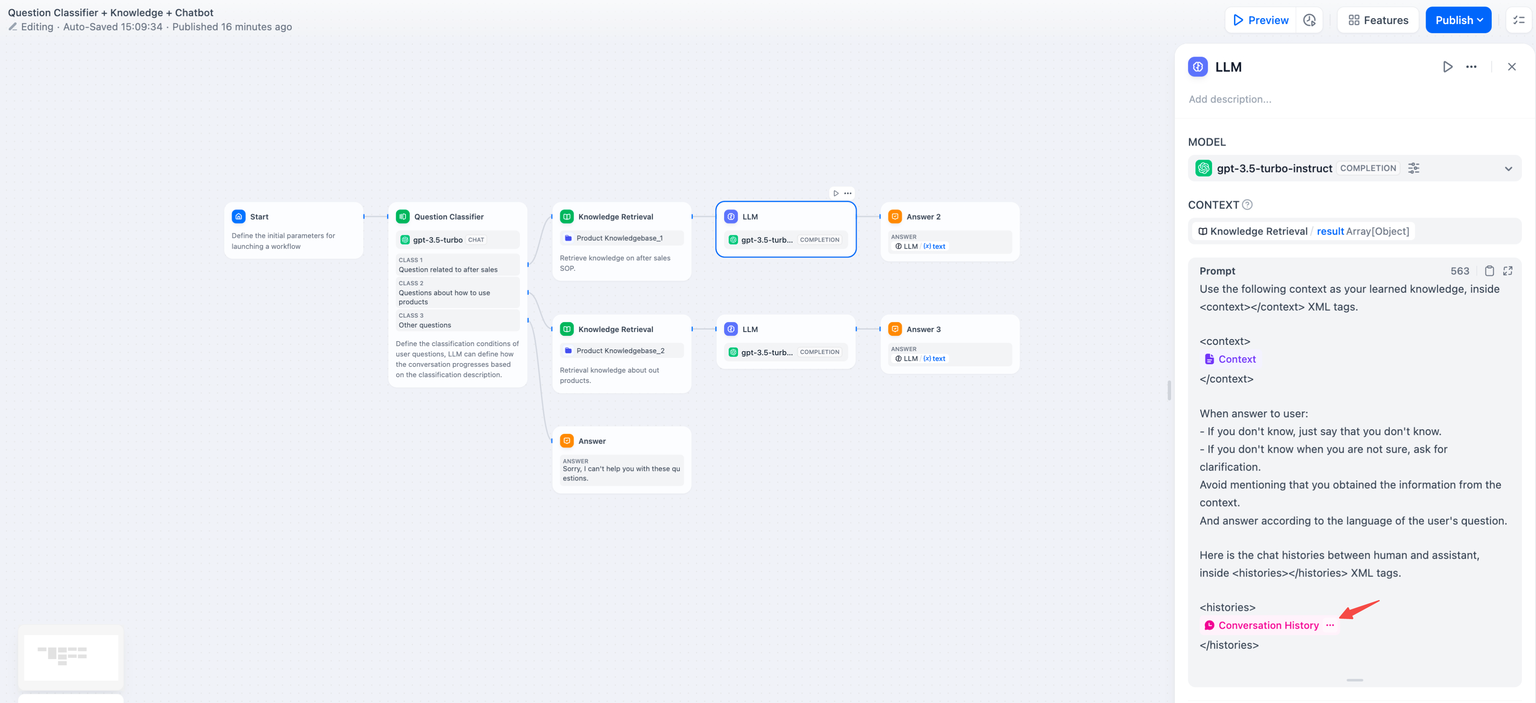
지식 검색 노드의 가변 출력에는 세분화된 참조 정보도 포함됩니다. 인용 및 귀속result 기능을 통해 정보 출처를 확인할 수 있습니다 .
업스트림 노드의 일반 변수도 컨텍스트 변수에 채워질 수 있습니다. 예를 들어 시작 노드의 문자열 유형 변수가 있지만, 인용 및 귀속 기능은 효과가 없습니다.
- 문서 파일 읽기
ChatPDF 애플리케이션을 구축하는 등 워크플로 애플리케이션에서 문서 내용을 읽을 수 있도록 하려면 다음 단계를 따르세요.
- “시작” 노드에 파일 변수를 추가합니다.
- LLM 노드의 상류에 문서 추출 노드를 추가하고 파일 변수를 입력 변수로 사용합니다.
- LLM 노드의 프롬프트에 문서 추출기 노드의 출력 변수를 입력합니다 .
text
자세한 내용은 파일 업로드 를 참조하세요 .
- 오류 처리
LLM 노드는 정보를 처리할 때 입력 텍스트가 토큰 제한을 초과하거나 키 매개변수가 누락되는 등의 오류가 발생할 수 있습니다. 개발자는 다음 단계에 따라 예외 분기를 구성하여 노드 오류 발생 시 전체 흐름이 중단되지 않도록 비상 계획을 실행할 수 있습니다.
- LLM 노드에서 “오류 처리”를 활성화합니다.
- 오류 처리 전략 선택 및 구성
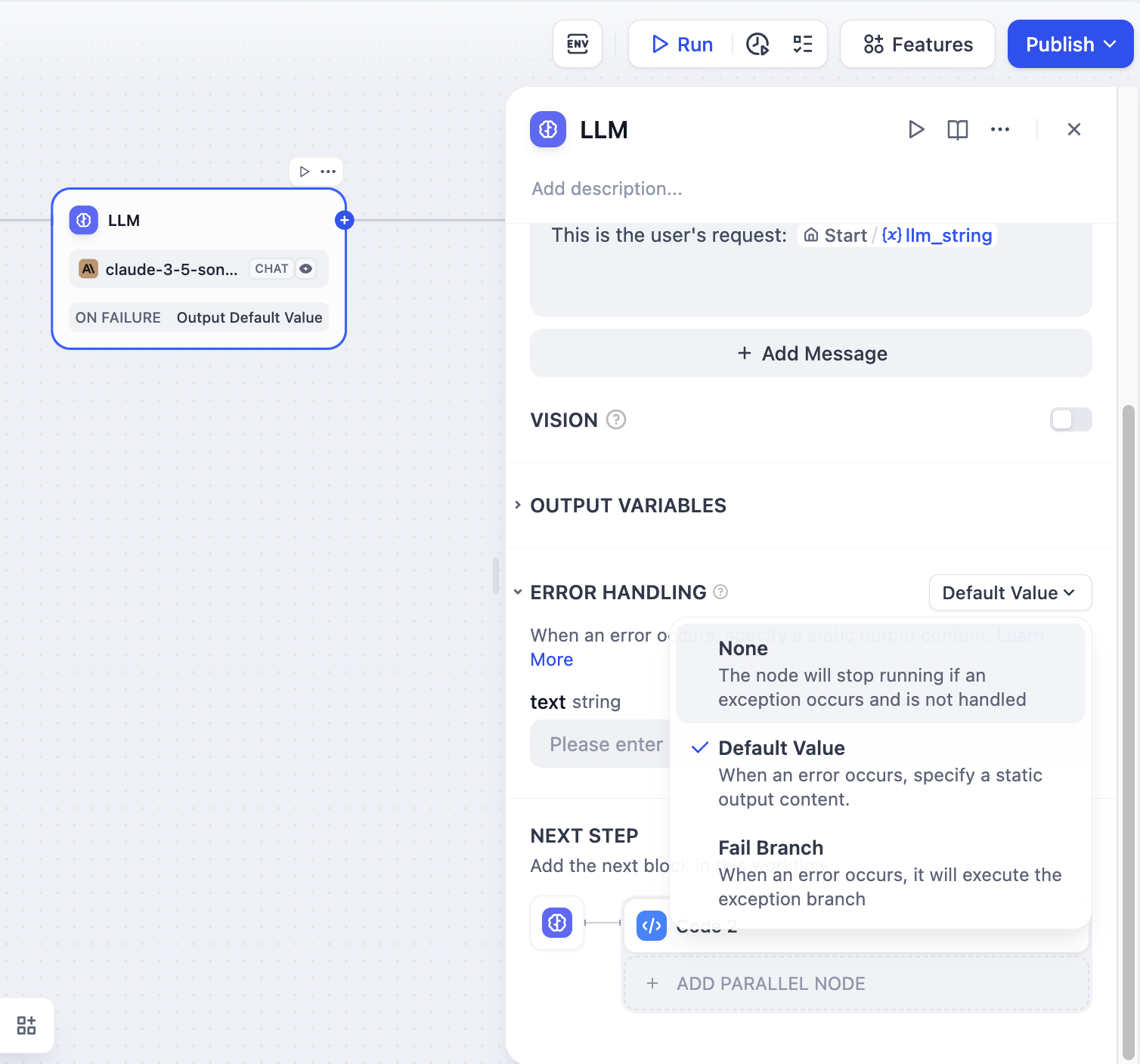
예외 처리 방법에 대한 자세한 내용은 오류 처리를 참조하세요 .
- 구조화된 출력
사례: 고객 정보 접수 양식
지식 검색 #
페이지 복사
지식 기반 검색 노드는 Dify 지식 기반에서 사용자 질문과 관련된 텍스트 콘텐츠를 쿼리하도록 설계되었으며, 이는 대규모 언어 모델(LLM)에서 후속 답변의 컨텍스트로 사용될 수 있습니다. 지식 기반 검색 노드 구성에는 4가지 주요 단계가 포함됩니다.
지식 기반 검색 노드 구성에는 4가지 주요 단계가 포함됩니다.
- 쿼리 변수 선택
- 쿼리를 위한 지식 기반 선택
- 메타데이터 필터링 적용
- 검색 전략 구성
쿼리 변수 선택지식 기반 검색 시나리오에서 쿼리 변수는 일반적으로 사용자의 입력 질문을 나타냅니다. 대화형 애플리케이션의 “시작” 노드에서 시스템은 “sys.query”를 사용자 입력 변수로 미리 설정합니다. 이 변수는 사용자 질문과 가장 밀접한 관련이 있는 텍스트 청크를 지식 기반에서 쿼리하는 데 사용할 수 있습니다. 지식 기반에 전송되는 최대 쿼리 내용은 200자입니다.쿼리를 위한 지식 기반 선택지식 기반 검색 노드 내에서 Dify의 기존 지식 기반을 추가할 수 있습니다. Dify에서 지식 기반을 생성하는 방법은 지식 기반 도움말 문서를 참조하세요 .메타데이터 필터링 적용메타데이터 필터링을 사용하여 지식 기반에서 문서 검색을 세부적으로 조정할 수 있습니다. 자세한 내용은 애플리케이션 내 지식 기반 통합 에서 메타데이터 필터링을 참조하세요 .검색 전략 구성노드 내 개별 지식 베이스의 인덱싱 전략 및 검색 모드를 수정할 수 있습니다. 이러한 설정에 대한 자세한 설명은 지식 베이스 도움말 문서를 참조하세요 .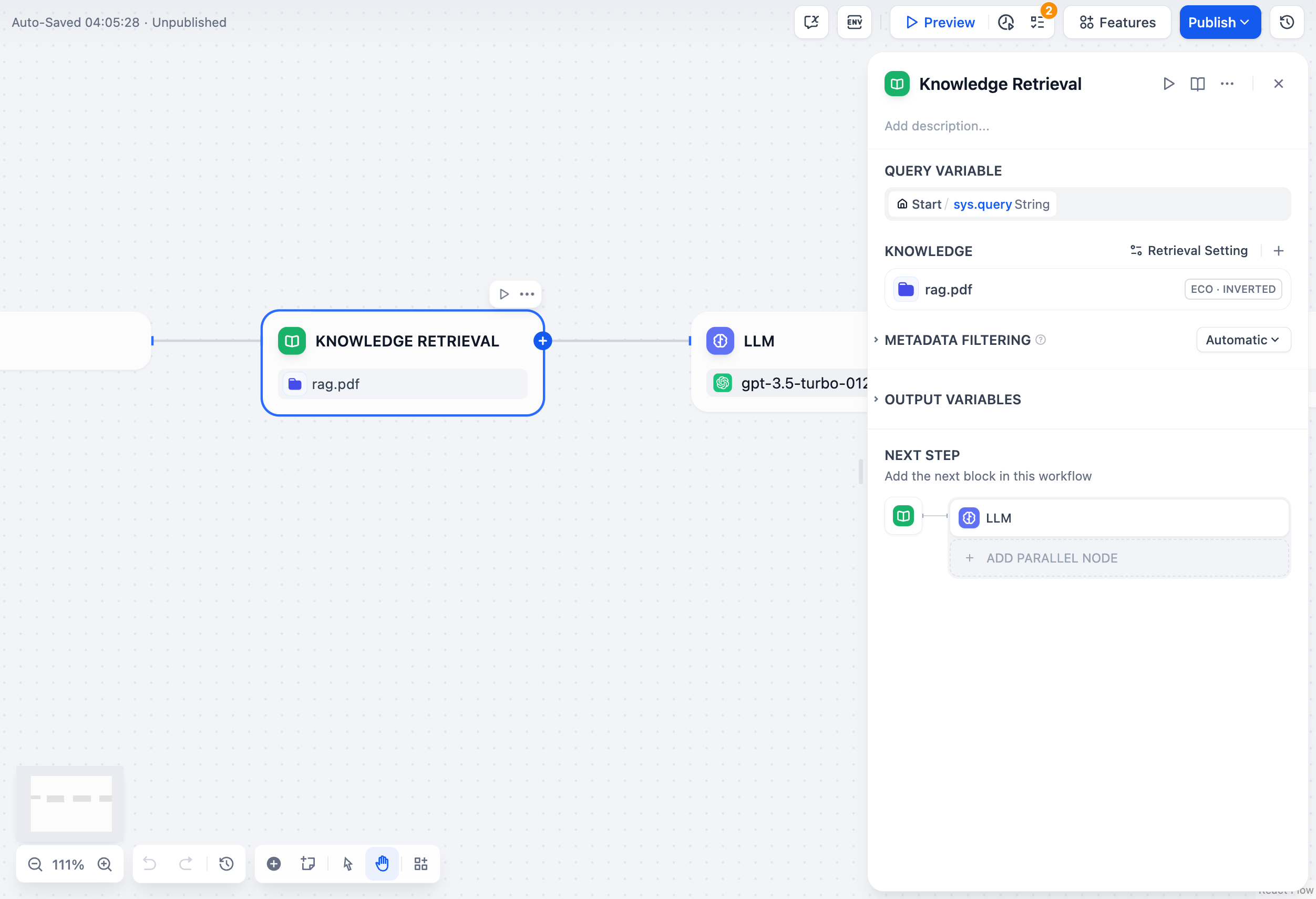 Dify는 다양한 지식 기반 검색 시나리오에 대해 “N-to-1 Recall”과 “Multi-way Recall”이라는 두 가지 회수 전략을 제공합니다. N-to-1 모드에서는 지식 기반 쿼리가 함수 호출을 통해 실행되므로 시스템 추론 모델을 선택해야 합니다. Multi-way Recall 모드에서는 결과 재순위 지정을 위해 Rerank 모델을 구성해야 합니다. 이 두 가지 회수 전략에 대한 자세한 설명은 도움말 문서 의 검색 모드 설명을 참조하십시오 .
Dify는 다양한 지식 기반 검색 시나리오에 대해 “N-to-1 Recall”과 “Multi-way Recall”이라는 두 가지 회수 전략을 제공합니다. N-to-1 모드에서는 지식 기반 쿼리가 함수 호출을 통해 실행되므로 시스템 추론 모델을 선택해야 합니다. Multi-way Recall 모드에서는 결과 재순위 지정을 위해 Rerank 모델을 구성해야 합니다. 이 두 가지 회수 전략에 대한 자세한 설명은 도움말 문서 의 검색 모드 설명을 참조하십시오 .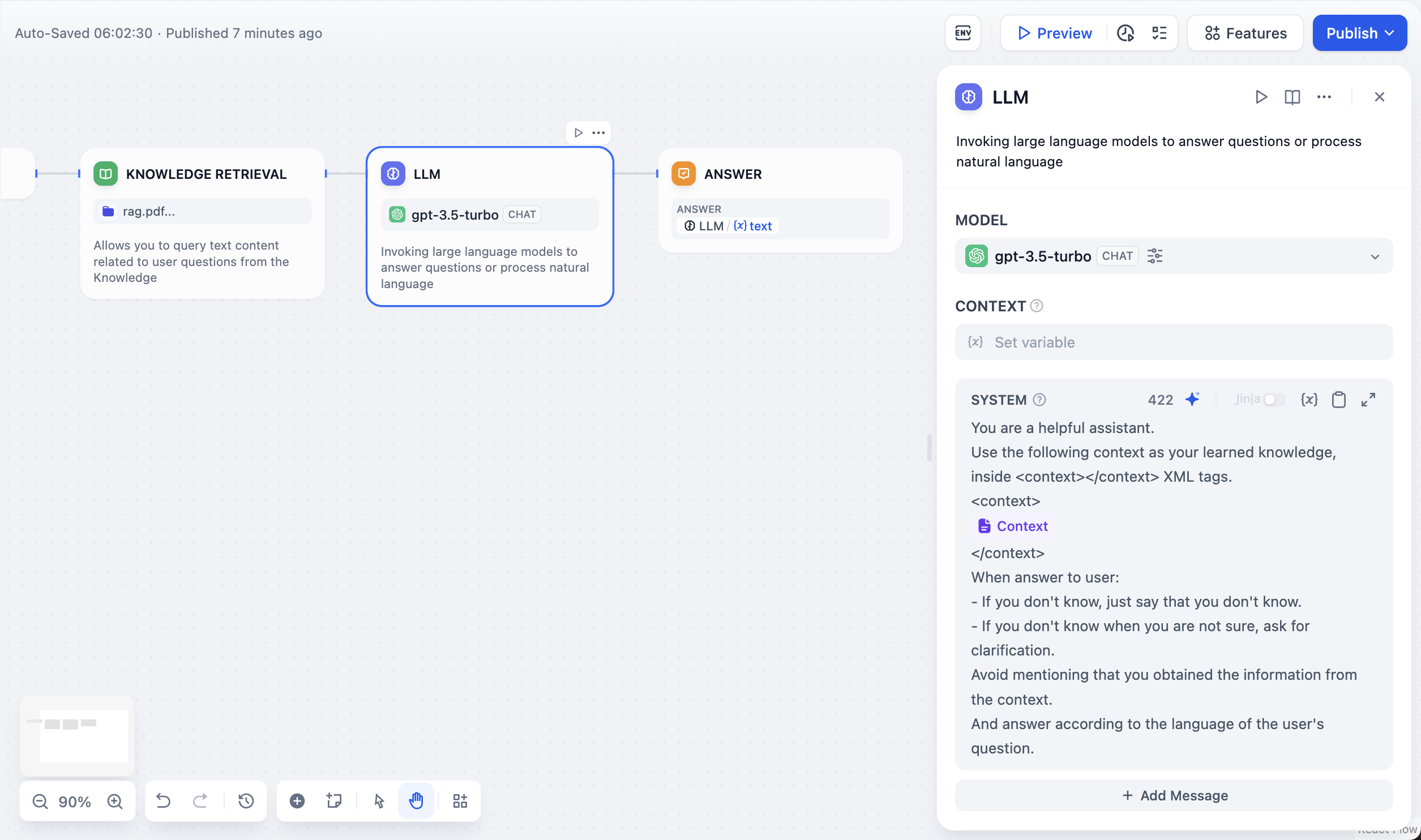
질문 분류기 #
페이지 복사
1. 정의 #
분류 설명을 정의함으로써 문제 분류기는 사용자 입력을 해당 범주에 추론하고 일치시켜 분류 결과를 출력할 수 있습니다.
2. 시나리오 #
일반적인 사용 사례로는 고객 서비스 대화 의도 분류, 제품 리뷰 분류, 대량 이메일 분류 등이 있습니다 .일반적인 제품 고객 서비스 Q&A 시나리오에서 문제 분류기는 지식 기반 검색 전 예비 단계 역할을 할 수 있습니다. 사용자의 입력 질문을 분류하여 다양한 하위 지식 기반 쿼리로 연결하여 사용자 질문에 정확하게 답변할 수 있도록 합니다.다음 다이어그램은 제품 고객 서비스 시나리오에 대한 워크플로 템플릿의 예입니다.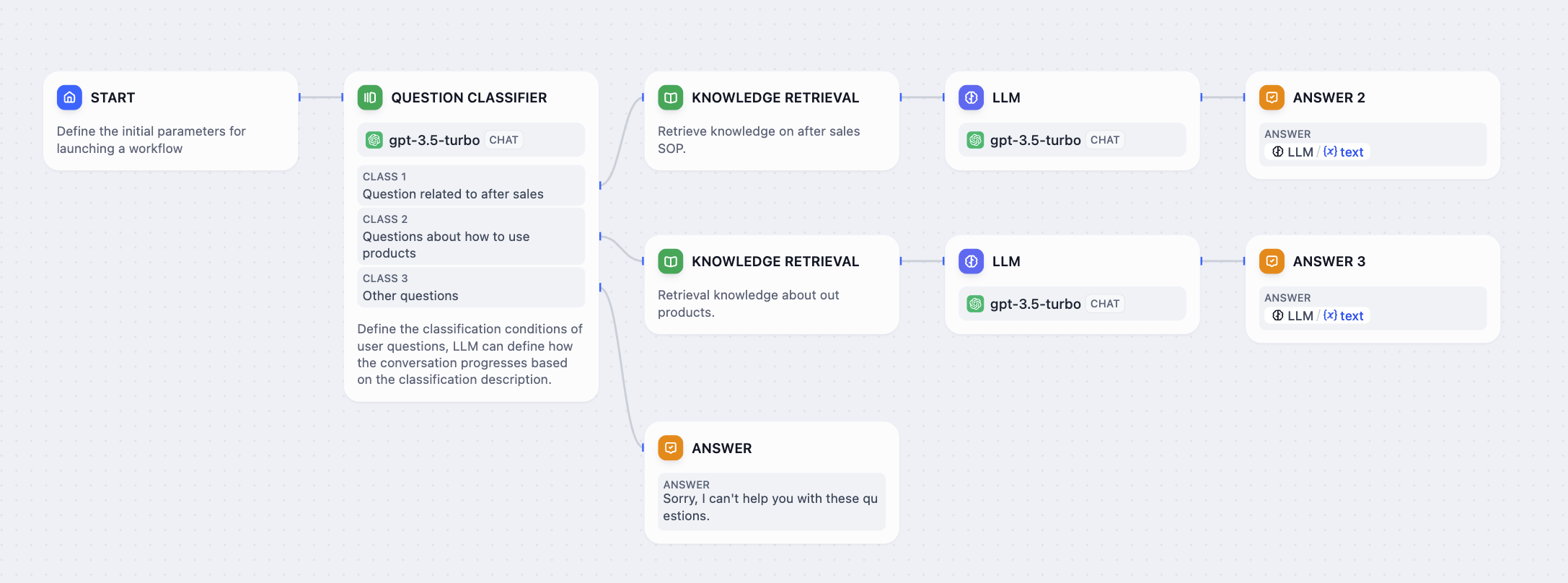 이 시나리오에서는 세 가지 분류 라벨/설명을 설정합니다.
이 시나리오에서는 세 가지 분류 라벨/설명을 설정합니다.
- 카테고리 1: 애프터서비스 관련 질문
- 카테고리 2: 제품 사용 관련 질문
- 카테고리 3: 기타 질문
사용자가 다양한 질문을 입력하면 문제 분류기는 설정된 분류 라벨/설명에 따라 자동으로 질문을 분류합니다.
- “ 아이폰 14 연락처 설정은 어떻게 하나요? ” —> “ 제품 사용 관련 문의 ”
- “ 보증 기간은 어떻게 되나요? ” —> “ 애프터서비스 관련 문의 ”
- “ 오늘 날씨는 어때요? ” —> “ 기타 질문 ”
3. 구성 방법 #
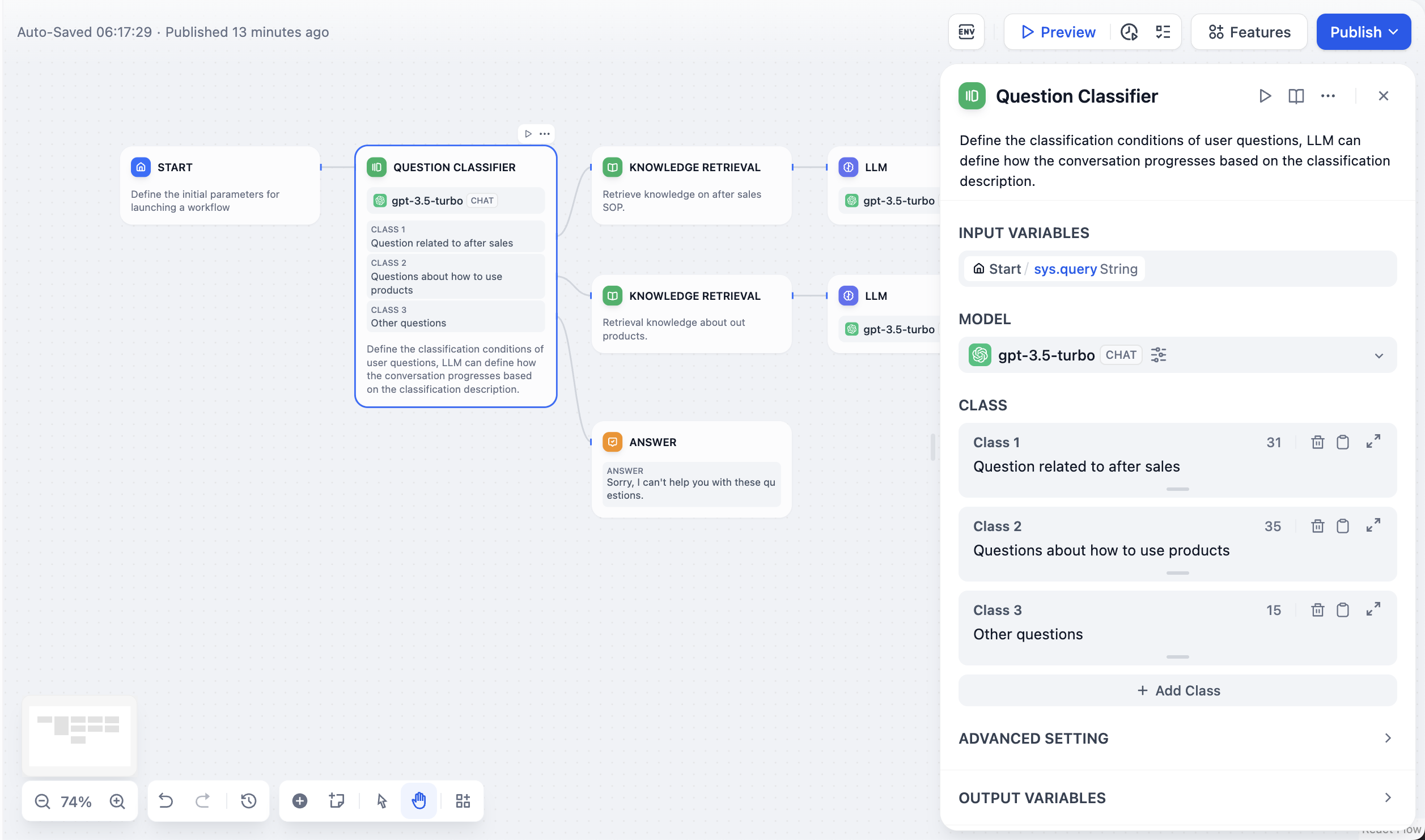 구성 단계:
구성 단계:
- 입력 변수 선택 : 이는 분류될 콘텐츠를 의미하며, 일반적으로 고객 서비스 Q&A 시나리오에서의 사용자 질문입니다. 예:
sys.query. - 추론 모델 선택 : 문제 분류기는 대규모 언어 모델의 자연어 분류 및 추론 기능을 활용합니다. 적절한 모델을 선택하면 분류 효율성을 높일 수 있습니다.
- 분류 라벨/설명 작성 : 각 카테고리에 대해 키워드나 설명적 문장을 작성하여 여러 분류를 수동으로 추가할 수 있으며, 이를 통해 대규모 언어 모델이 분류 기준을 더 잘 이해하는 데 도움이 됩니다.
- 해당 다운스트림 노드 선택 : 분류 후, 문제 분류 노드는 분류 노드와 다운스트림 노드 간의 관계에 따라 흐름을 다른 경로로 지시할 수 있습니다.
고급 설정: #
지침 : 고급 설정 – 지침 에서 분류기의 기능을 향상시키기 위해 더 자세한 분류 기준 등의 보충 지침을 추가할 수 있습니다.메모리 : 이 기능을 활성화하면 문제 분류기의 각 입력에 대화의 채팅 기록이 포함되어 LLM이 맥락을 이해하고 대화형 대화에서 질문 이해도를 향상시키는 데 도움이 됩니다.메모리 창 : 메모리 창이 닫히면 시스템은 모델의 컨텍스트 창에 따라 전달되는 채팅 기록의 양을 동적으로 필터링합니다. 창이 열려 있으면 사용자는 전달되는 채팅 기록의 양(숫자 기준)을 정확하게 제어할 수 있습니다.출력 변수 :class_name분류 출력 레이블을 저장합니다. 필요한 경우 다운스트림 노드에서 이 분류 결과를 참조할 수 있습니다.
조건 분기 IF/ELSE #
페이지 복사
정의 #
if/else 조건에 따라 워크플로를 두 개의 분기로 나눌 수 있습니다.조건 분기 노드는 세 부분으로 구성됩니다.
- IF 조건: 변수를 선택하고, 조건을 설정하고, 조건을 만족하는 값을 지정합니다.
- IF 조건이 로 평가되면
TrueIF 경로를 실행합니다. - 조건이 로 평가되면
FalseELSE 경로를 실행합니다. - ELIF 조건이 로 평가되면
TrueELIF 경로를 실행합니다. - ELIF 조건이 로 평가되면
False다음 ELIF 경로를 계속 평가하거나 최종 ELSE 경로를 실행합니다.
조건 유형
- 포함
- 포함하지 않음
- 로 시작합니다
- ~로 끝남
- ~이다
- 아니다
- 비어있습니다
- 비어있지 않습니다
대본 #
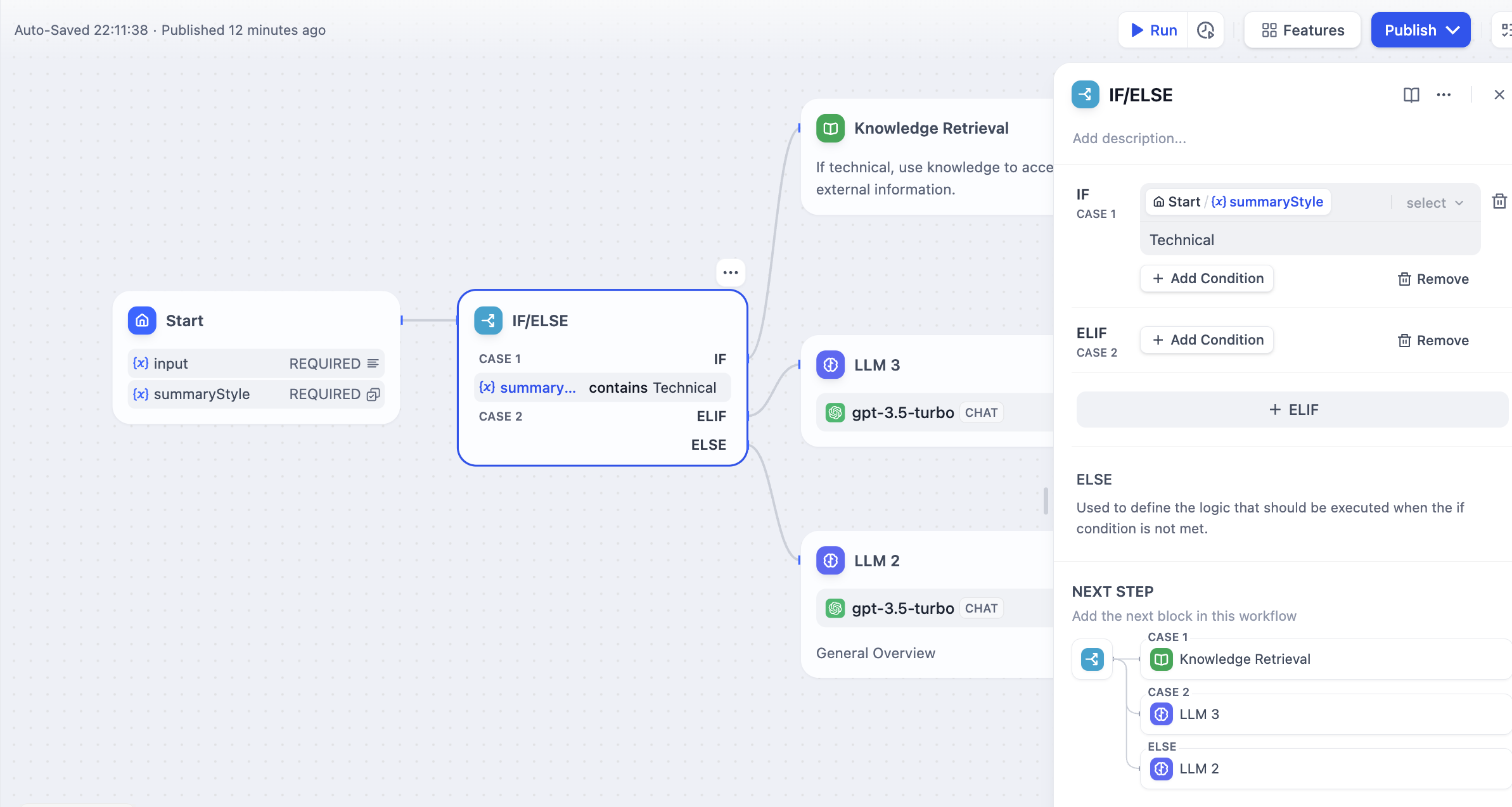 위의 텍스트 요약 워크플로를 예로 들어 보겠습니다.
위의 텍스트 요약 워크플로를 예로 들어 보겠습니다.
- IF 조건:
summarystyle시작 노드에서 조건을 포함technical으로 변수를 선택합니다 . - IF 조건이 로 평가되면
True지식 검색 노드를 통해 기술 관련 지식을 쿼리하여 IF 경로를 따른 다음 LLM 노드를 통해 응답합니다(다이어그램 상단 절반에 표시됨). - 조건이 로 평가되지만
False변수 의ELIF입력에 가 포함되지 않지만 조건에 가 포함되는 조건이 추가된 경우, 조건이 가인 지 확인한 다음 해당 경로 내에 정의된 단계를 실행합니다.summarystyletechnologyELIFscienceELIFTrue - 조건이 , 즉 입력 변수에 , 도, 도 포함되지 않는
ELIF경우 , 다음 조건을 계속 평가하거나 최종 경로를 실행합니다.FalsetechnologyscienceELIFELSE - IF 조건이 로 평가되면
False, 즉summarystyle변수 input 에 를 포함하지 않으면technicalELSE 경로를 실행하고 LLM2 노드(다이어그램 하단)를 통해 응답합니다.
다중 조건 판단복잡한 조건 판단의 경우 여러 개의 조건 판단을 설정하고 조건 사이에 AND 또는 OR를 구성하여 각각 조건의 교집합 이나 합집합을 구할 수 있습니다 .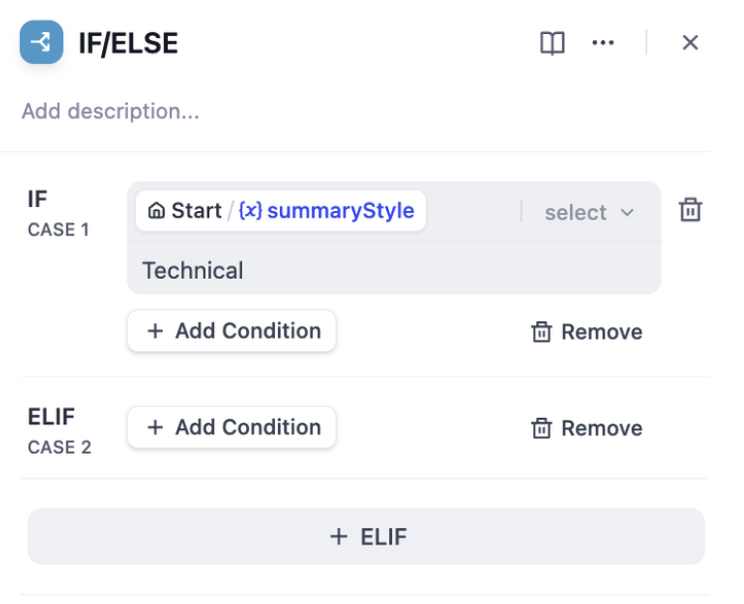
코드 실행 #
페이지 복사
목차 #
소개 #
코드 노드는 워크플로 내에서 데이터 변환을 수행하기 위해 Python/NodeJS 코드 실행을 지원합니다. 워크플로를 간소화하고 산술 연산, JSON 변환, 텍스트 처리 등의 시나리오에 적합합니다.이 노드는 개발자의 유연성을 크게 향상시켜 워크플로 내에 사용자 지정 Python 또는 JavaScript 스크립트를 내장하고 사전 설정된 노드로는 불가능한 방식으로 변수를 조작할 수 있도록 합니다. 구성 옵션을 통해 필요한 입력 및 출력 변수를 지정하고 해당 실행 코드를 작성할 수 있습니다.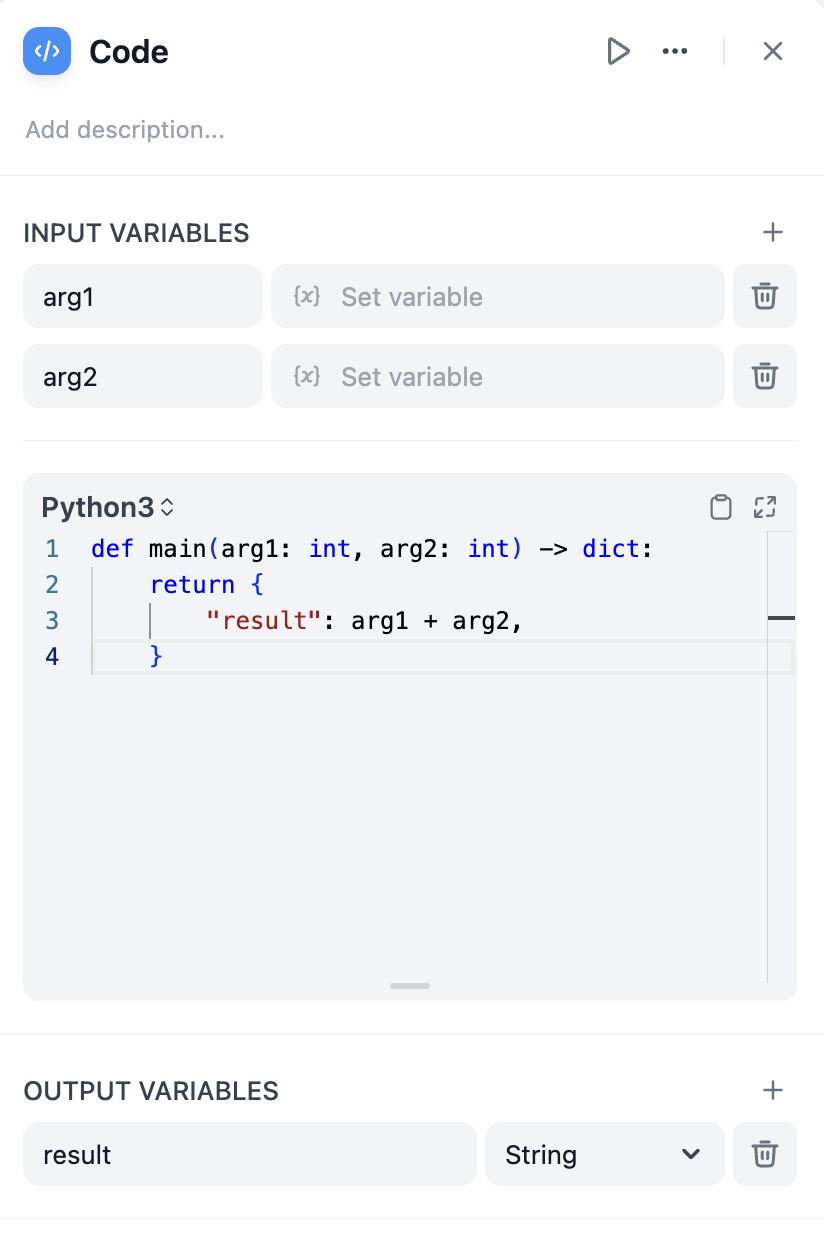
구성 #
코드 노드에서 다른 노드의 변수를 사용해야 하는 경우, 변수 이름을 정의하고 해당 변수를 참조해야 합니다 . 변수 참조input variables 를 참조하세요 .
사용 시나리오 #
코드 노드를 사용하면 다음과 같은 일반적인 작업을 수행할 수 있습니다.
구조화된 데이터 처리 #
워크플로에서는 JSON 문자열 구문 분석, 추출 및 변환과 같은 비정형 데이터 처리를 자주 처리해야 합니다. 대표적인 예로 HTTP 노드에서 데이터를 처리하는 것을 들 수 있습니다. 일반적인 API 반환 구조에서 데이터는 여러 계층의 JSON 객체 내에 중첩될 수 있으며, 특정 필드를 추출해야 합니다. 코드 노드를 사용하면 이러한 작업을 수행할 수 있습니다. 다음은 data.nameHTTP 노드에서 반환된 JSON 문자열에서 필드를 추출하는 간단한 예입니다.복사AI에게 물어보세요
def main(http_response: str) -> dict:
import json
data = json.loads(http_response)
return {
# Note to declare 'result' in the output variables
'result': data['data']['name']
}
수학적 계산 #
워크플로에서 복잡한 수학 계산을 수행해야 할 때도 코드 노드를 사용할 수 있습니다. 예를 들어, 복잡한 수학 공식을 계산하거나 데이터에 대한 통계 분석을 수행하는 경우입니다. 다음은 배열의 분산을 계산하는 간단한 예입니다.복사AI에게 물어보세요
def main(x: list) -> dict:
return {
# Note to declare 'result' in the output variables
'result': sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
}
데이터 연결 #
때로는 여러 지식 검색, 데이터 검색, API 호출 등 여러 데이터 소스를 연결해야 할 수 있습니다. 코드 노드를 사용하면 이러한 데이터 소스를 통합할 수 있습니다. 다음은 두 지식 베이스의 데이터를 병합하는 간단한 예입니다.복사AI에게 물어보세요
def main(knowledge1: list, knowledge2: list) -> dict:
return {
# Note to declare 'result' in the output variables
'result': knowledge1 + knowledge2
}
로컬 배포 #
로컬 배포 사용자인 경우, 악성 코드가 실행되지 않도록 샌드박스 서비스를 시작해야 합니다. 이 서비스를 사용하려면 Docker가 필요합니다. 샌드박스 서비스에 대한 자세한 내용은 여기에서 확인할 수 있습니다 . 또한, 다음 방법을 통해 서비스를 직접 시작할 수도 있습니다 docker-compose.복사AI에게 물어보세요
docker-compose -f docker-compose.middleware.yaml up -d
보안 정책 #
Python과 JavaScript 실행 환경은 모두 보안을 위해 엄격하게 격리(샌드박스)되어 있습니다. 즉, 개발자는 파일 시스템에 직접 접근하거나, 네트워크 요청을 하거나, 운영 체제 수준의 명령을 실행하는 등 많은 시스템 리소스를 소모하거나 보안 위험을 초래할 수 있는 함수를 사용할 수 없습니다. 이러한 제한을 통해 과도한 시스템 리소스 소모를 방지하면서 코드의 안전한 실행이 보장됩니다.
고급 기능 #
실패 시 재시도노드에서 발생하는 일부 예외의 경우, 일반적으로 노드를 다시 시도하는 것으로 충분합니다. 오류 재시도 기능이 활성화되어 있으면 오류 발생 시 노드는 미리 설정된 전략에 따라 자동으로 재시도합니다. 최대 재시도 횟수와 각 재시도 간격을 조정하여 재시도 전략을 설정할 수 있습니다.
- 최대 재시도 횟수는 10회입니다.
- 최대 재시도 간격은 5000ms입니다.
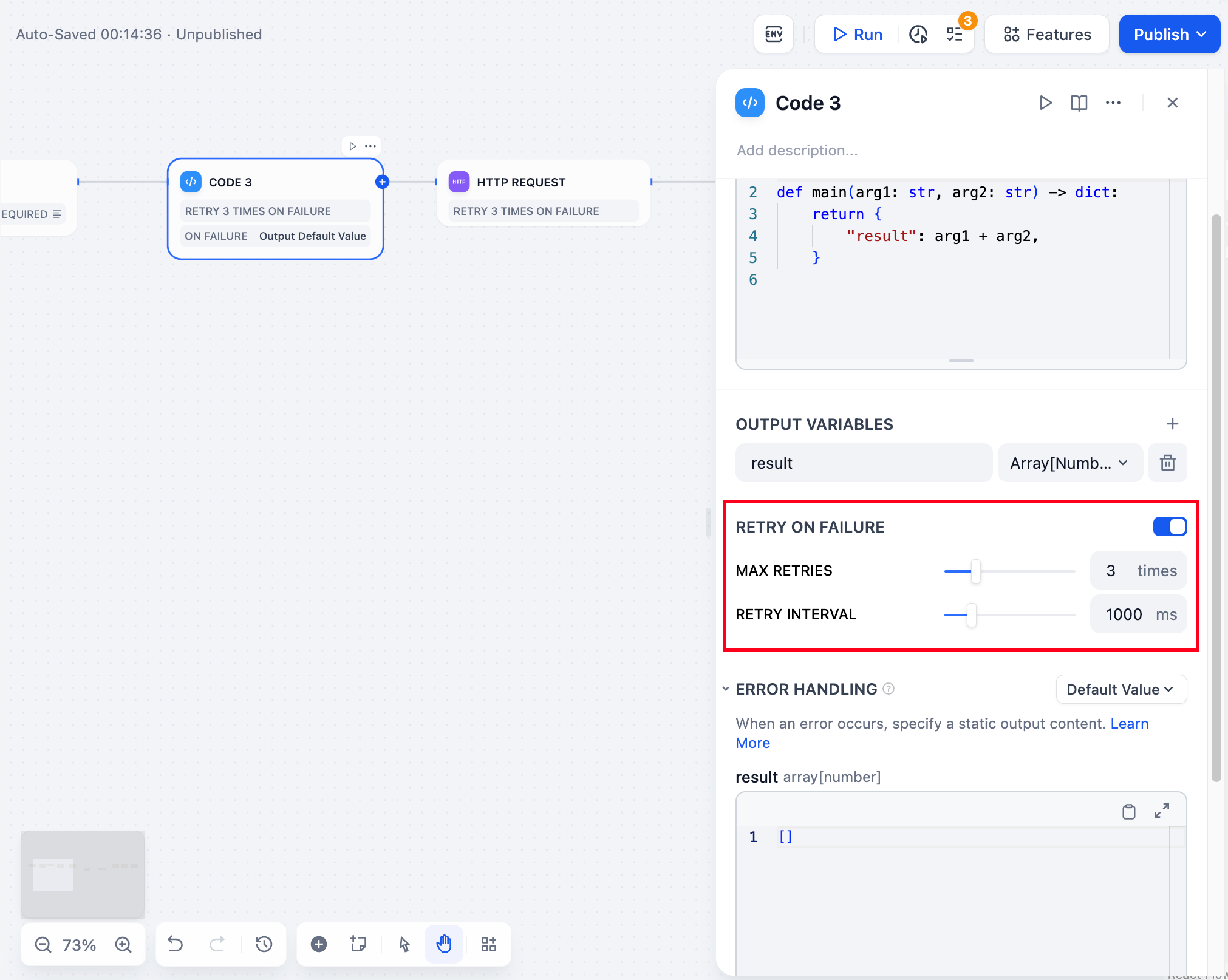 오류 처리정보를 처리할 때 코드 노드에서 코드 실행 예외가 발생할 수 있습니다. 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
오류 처리정보를 처리할 때 코드 노드에서 코드 실행 예외가 발생할 수 있습니다. 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
- 코드 노드에서 “오류 처리”를 활성화합니다.
- 오류 처리 전략 선택 및 구성
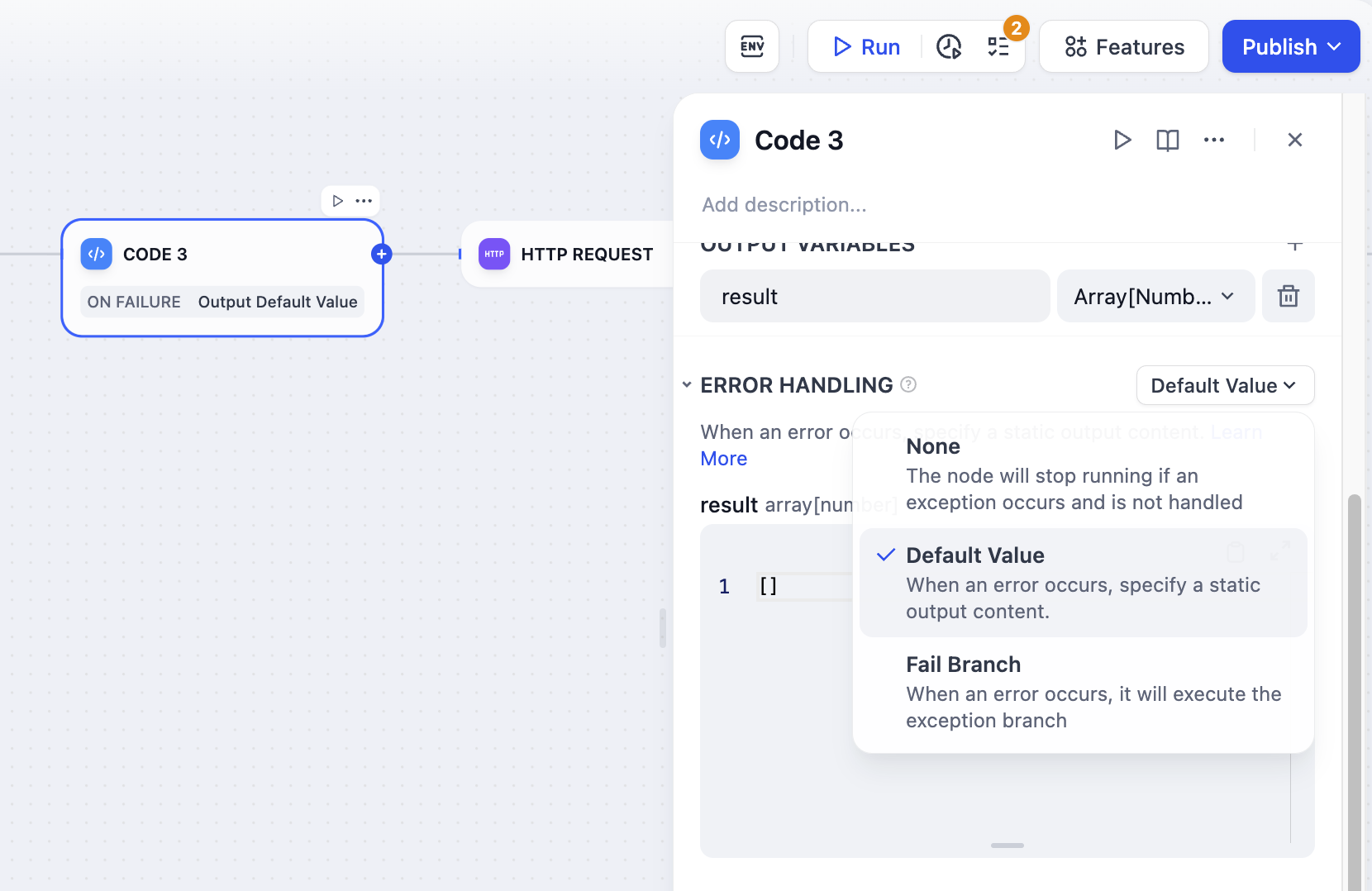 예외 처리 접근 방식에 대한 자세한 내용은 오류 처리를 참조하세요 .
예외 처리 접근 방식에 대한 자세한 내용은 오류 처리를 참조하세요 .
자주 묻는 질문 #
왜 코드 노드에 코드를 저장할 수 없나요?코드에 잠재적으로 위험한 동작이 포함되어 있는지 확인하세요. 예:복사AI에게 물어보세요
def main() -> dict:
return {
"result": open("/etc/passwd").read(),
}
이 코드 조각에는 다음과 같은 문제가 있습니다.
- 승인되지 않은 파일 접근: 이 코드는 Unix/Linux 시스템의 중요한 시스템 파일인 “/etc/passwd” 파일을 읽으려고 시도합니다. 이 파일은 사용자 계정 정보를 저장합니다.
- 민감한 정보 공개: “/etc/passwd” 파일에는 사용자 이름, 사용자 ID, 그룹 ID, 홈 디렉터리 경로 등 시스템 사용자에 대한 중요한 정보가 포함되어 있습니다. 직접 액세스하면 정보 유출이 발생할 수 있습니다.
위험한 코드는 Cloudflare WAF에 의해 자동으로 차단됩니다. 브라우저의 “웹 개발자 도구”에서 “네트워크” 탭을 확인하여 차단 여부를 확인할 수 있습니다.
템플릿(Template) #
템플릿을 사용하면 Python용 강력한 템플릿 구문인 Jinja2를 사용하여 이전 노드의 변수를 동적으로 서식 지정하고 결합하여 단일 텍스트 기반 출력으로 만들 수 있습니다. 여러 소스의 데이터를 후속 노드에 필요한 특정 구조로 결합하는 데 유용합니다. 아래의 간단한 예시는 다양한 이전 출력을 조합하여 기사를 구성하는 방법을 보여줍니다.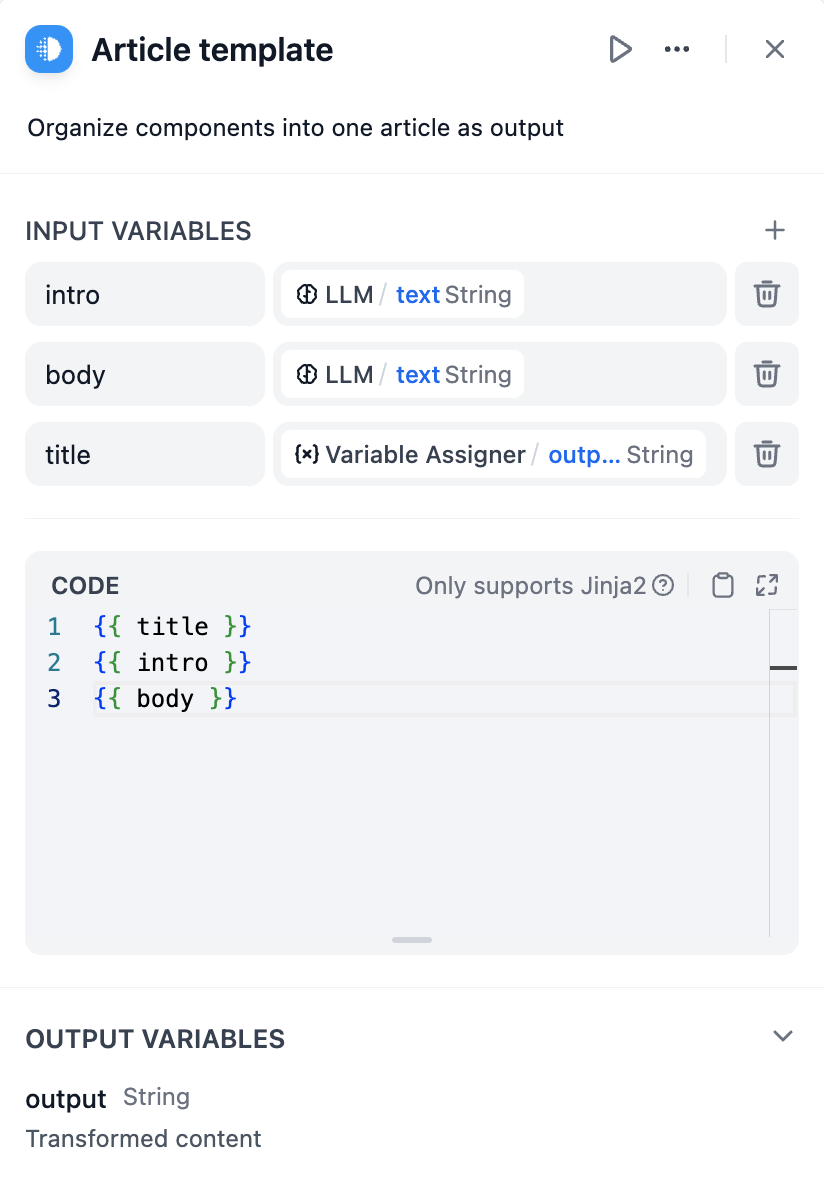 단순한 사용 사례 외에도 Jinja의 다양한 작업에 대한 설명서 에 따라 더욱 복잡한 템플릿을 만들 수 있습니다 . 지식 검색 노드에서 검색된 청크와 관련 메타데이터를 형식화된 마크다운으로 구조화하는 템플릿은 다음과 같습니다.복사AI에게 물어보세요
단순한 사용 사례 외에도 Jinja의 다양한 작업에 대한 설명서 에 따라 더욱 복잡한 템플릿을 만들 수 있습니다 . 지식 검색 노드에서 검색된 청크와 관련 메타데이터를 형식화된 마크다운으로 구조화하는 템플릿은 다음과 같습니다.복사AI에게 물어보세요
{% for item in chunks %}
### Chunk {{ loop.index }}.
### Similarity: {{ item.metadata.score | default('N/A') }}
#### {{ item.title }}
##### Content
{{ item.content | replace('\n', '\n\n') }}
---
{% endfor %}
 이 템플릿 노드는 LLM 응답이 시작되기 전에 Chatflow 내에서 최종 사용자에게 중간 출력을 반환하는 데 사용될 수 있습니다.
이 템플릿 노드는 LLM 응답이 시작되기 전에 Chatflow 내에서 최종 사용자에게 중간 출력을 반환하는 데 사용될 수 있습니다.
Chatflow의 노드
Answer는 비종단형입니다. 흐름 내 여러 지점에서 응답을 출력하기 위해 어디에나 삽입할 수 있습니다.
예: HTML 양식 렌더링 지원:복사AI에게 물어보세요
<form data-format="json"> // Default to text
<label for="username">Username:</label>
<input type="text" name="username" />
<label for="password">Password:</label>
<input type="password" name="password" />
<label for="content">Content:</label>
<textarea name="content"></textarea>
<label for="date">Date:</label>
<input type="date" name="date" />
<label for="time">Time:</label>
<input type="time" name="time" />
<label for="datetime">Datetime:</label>
<input type="datetime" name="datetime" />
<label for="select">Select:</label>
<input type="select" name="select" data-options='["hello","world"]'/>
<input type="checkbox" name="check" data-tip="By checking this means you agreed"/>
<button data-size="small" data-variant="primary">Login</button>
</form>
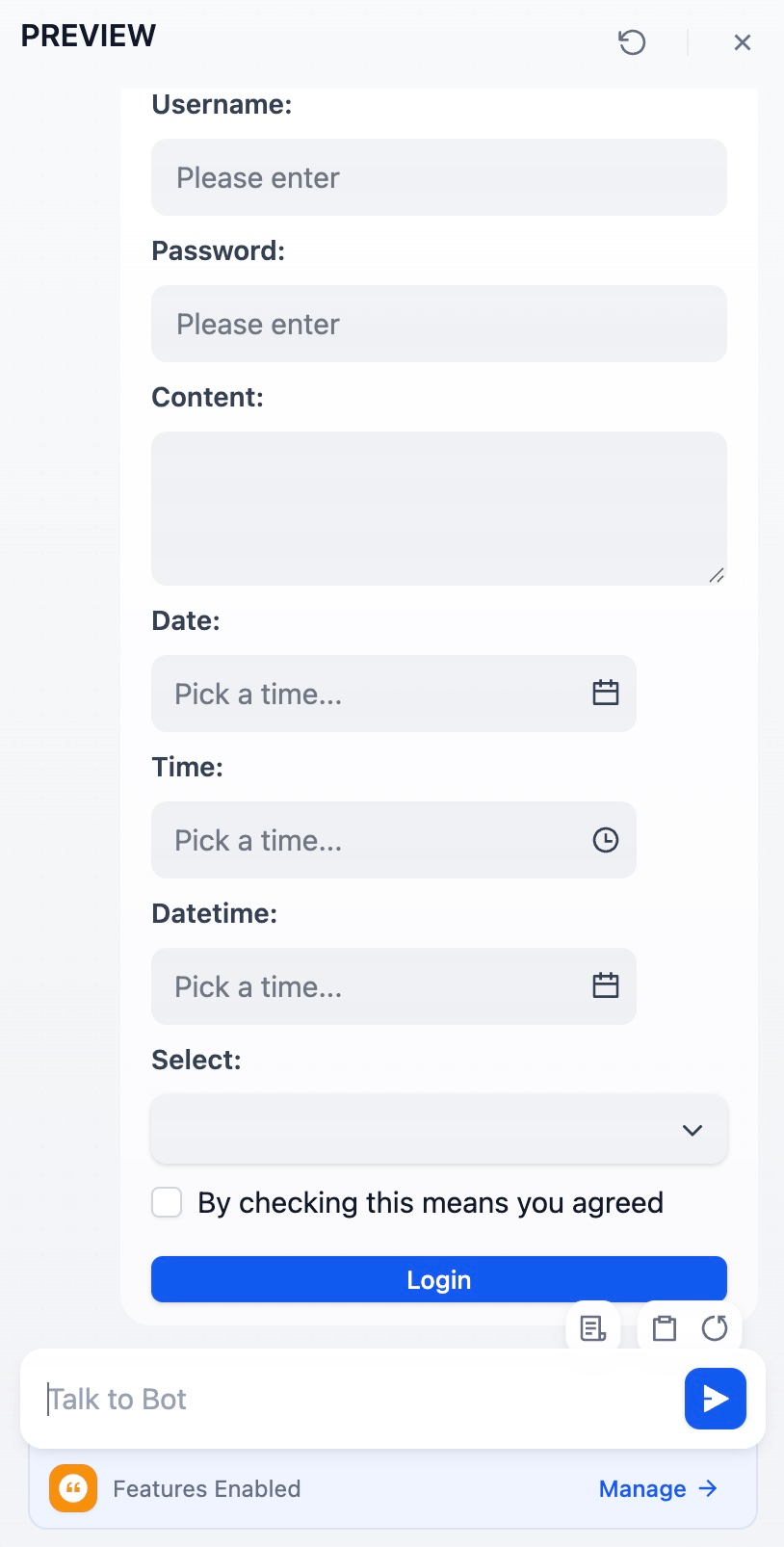
문서 추출기 #
페이지 복사
정의 #
LLM은 문서 내용을 직접 읽거나 해석할 수 없습니다. 따라서 문서 추출 노드를 통해 사용자가 업로드한 문서의 정보를 구문 분석하고 읽어서 텍스트로 변환한 후, LLM에 전달하여 파일 내용을 처리해야 합니다.
응용 프로그램 시나리오 #
- ChatPDF나 ChatWord와 같이 파일과 상호 작용할 수 있는 LLM 애플리케이션을 구축합니다.
- 사용자가 업로드한 파일의 내용을 분석하고 조사합니다.
노드 기능 #
문서 추출 노드는 정보 처리 센터로 이해될 수 있습니다. 입력 변수의 파일을 인식하고 읽고, 정보를 추출하여 다운스트림 노드가 호출할 수 있도록 문자열 유형의 출력 변수로 변환합니다.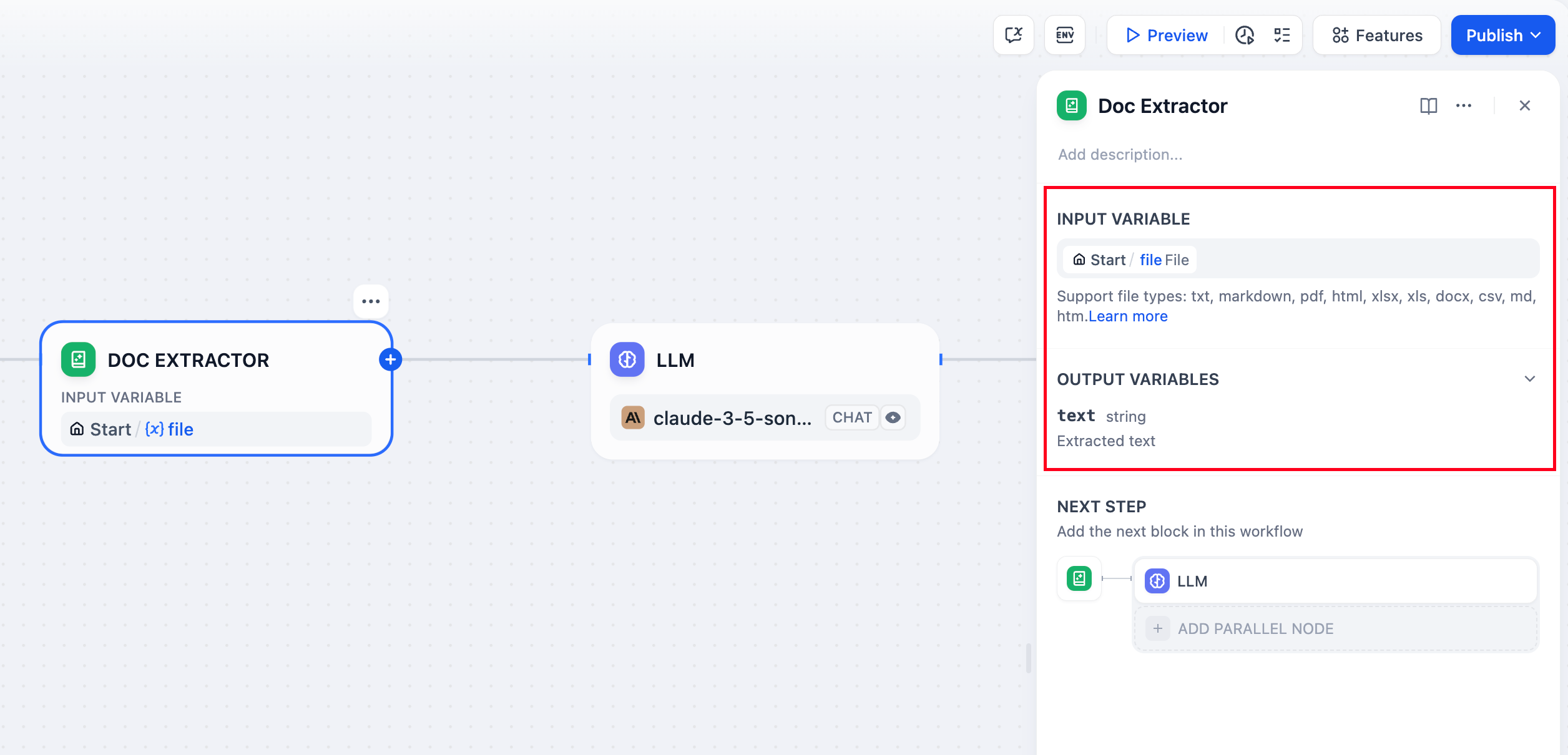 문서 추출기 노드 구조는 입력 변수와 출력 변수로 구분됩니다.입력 변수문서 추출기는 다음과 같은 데이터 구조를 가진 변수만 허용합니다.
문서 추출기 노드 구조는 입력 변수와 출력 변수로 구분됩니다.입력 변수문서 추출기는 다음과 같은 데이터 구조를 가진 변수만 허용합니다.
File, 단일 파일Array[File], 여러 파일
문서 추출기는 TXT, 마크다운, PDF, HTML, DOCX 형식 파일의 내용과 같은 문서 유형 파일에서만 정보를 추출할 수 있습니다. 이미지, 오디오, 비디오 또는 기타 파일 형식은 처리할 수 없습니다.출력 변수출력 변수는 고정되어 있으며 텍스트라는 이름이 지정됩니다. 출력 변수의 유형은 입력 변수에 따라 달라집니다.
- 입력 변수가 이면
File출력 변수는string - 입력 변수가 이면
Array[File]출력 변수는array[string]
배열 변수는 일반적으로 목록 연산 노드와 함께 사용해야 합니다. 자세한 내용은 목록 연산자 를 참조하세요 .
구성 예 #
일반적인 파일 상호작용 Q&A 시나리오에서 문서 추출기는 LLM 노드의 예비 단계 역할을 하여 애플리케이션에서 파일 정보를 추출하고 이를 다운스트림 LLM 노드로 전달하여 파일과 관련된 사용자 질문에 답할 수 있습니다.이 섹션에서는 일반적인 ChatPDF 예제 워크플로 템플릿을 통해 문서 추출 노드의 사용법을 소개합니다.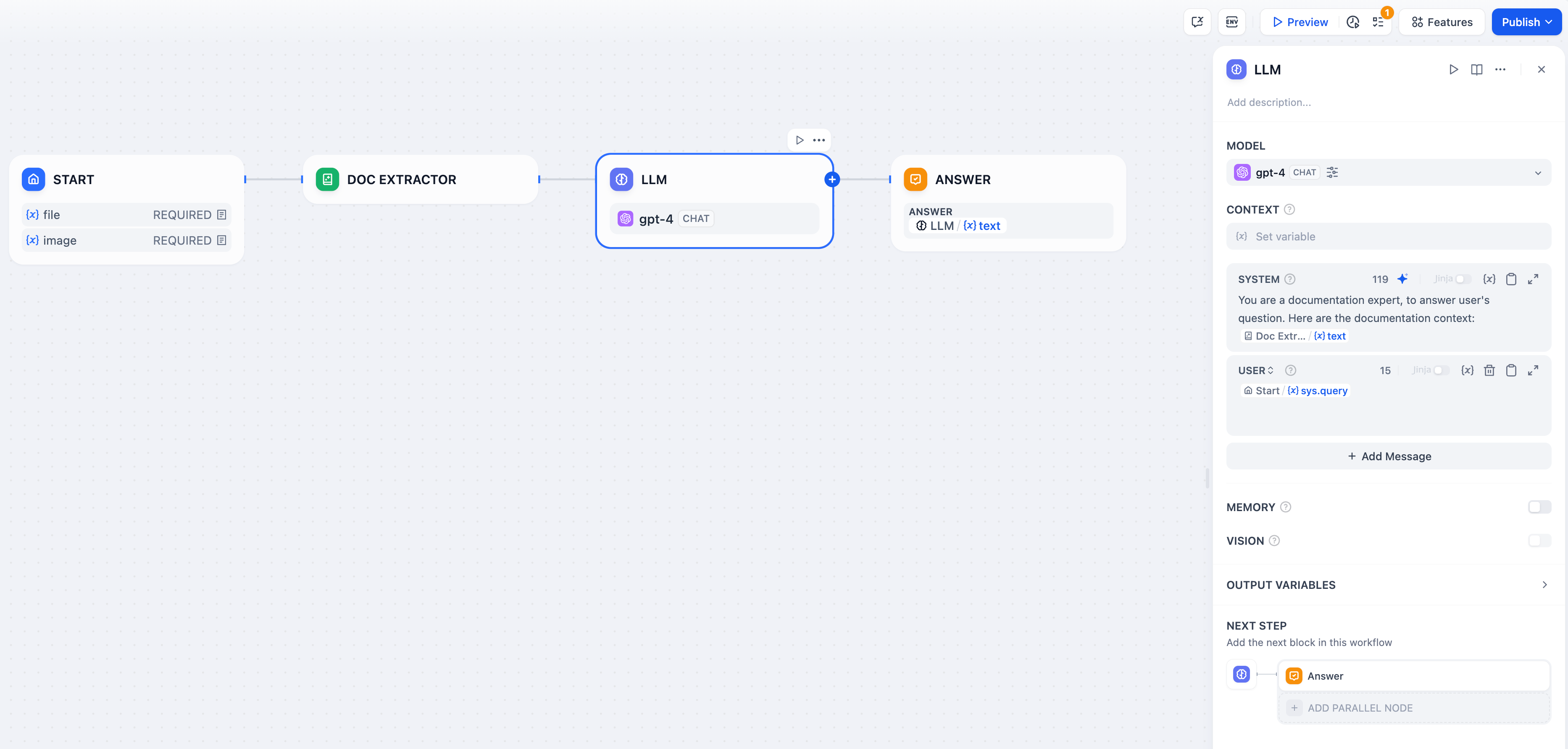 구성 프로세스:
구성 프로세스:
- 애플리케이션의 파일 업로드를 활성화합니다. “시작” 노드에 파일 변수 하나를
pdf추가하고 이름을 . - 문서 추출기 노드를 추가하고
pdf입력 변수에서 변수를 선택합니다. - LLM 노드를 추가하고 시스템 프롬프트에서 문서 추출기 노드의 출력 변수를 선택하세요. LLM은 이 출력 변수를 통해 파일의 내용을 읽을 수 있습니다.
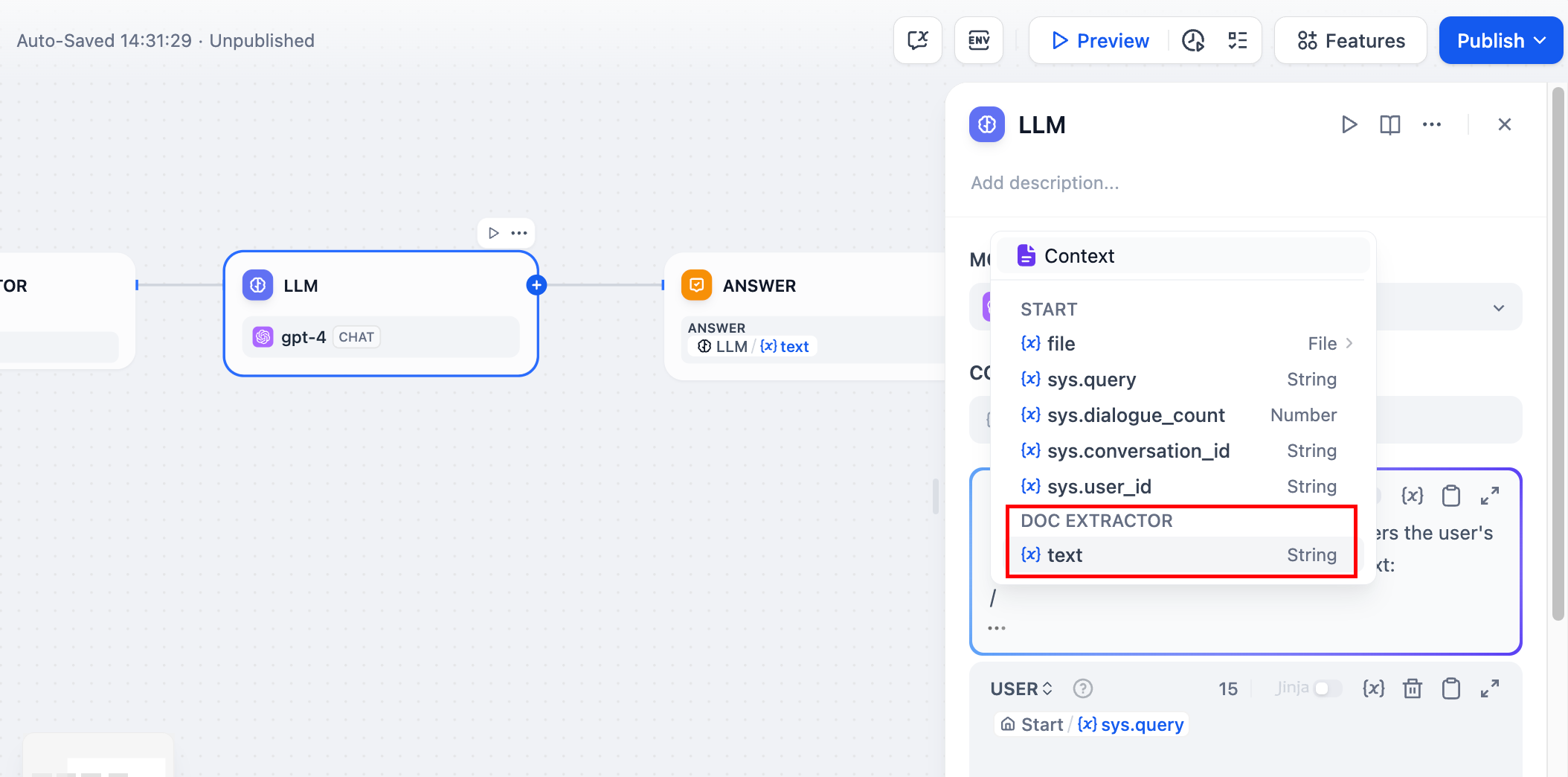 끝 노드에서 LLM 노드의 출력 변수를 선택하여 끝 노드를 구성합니다.
끝 노드에서 LLM 노드의 출력 변수를 선택하여 끝 노드를 구성합니다.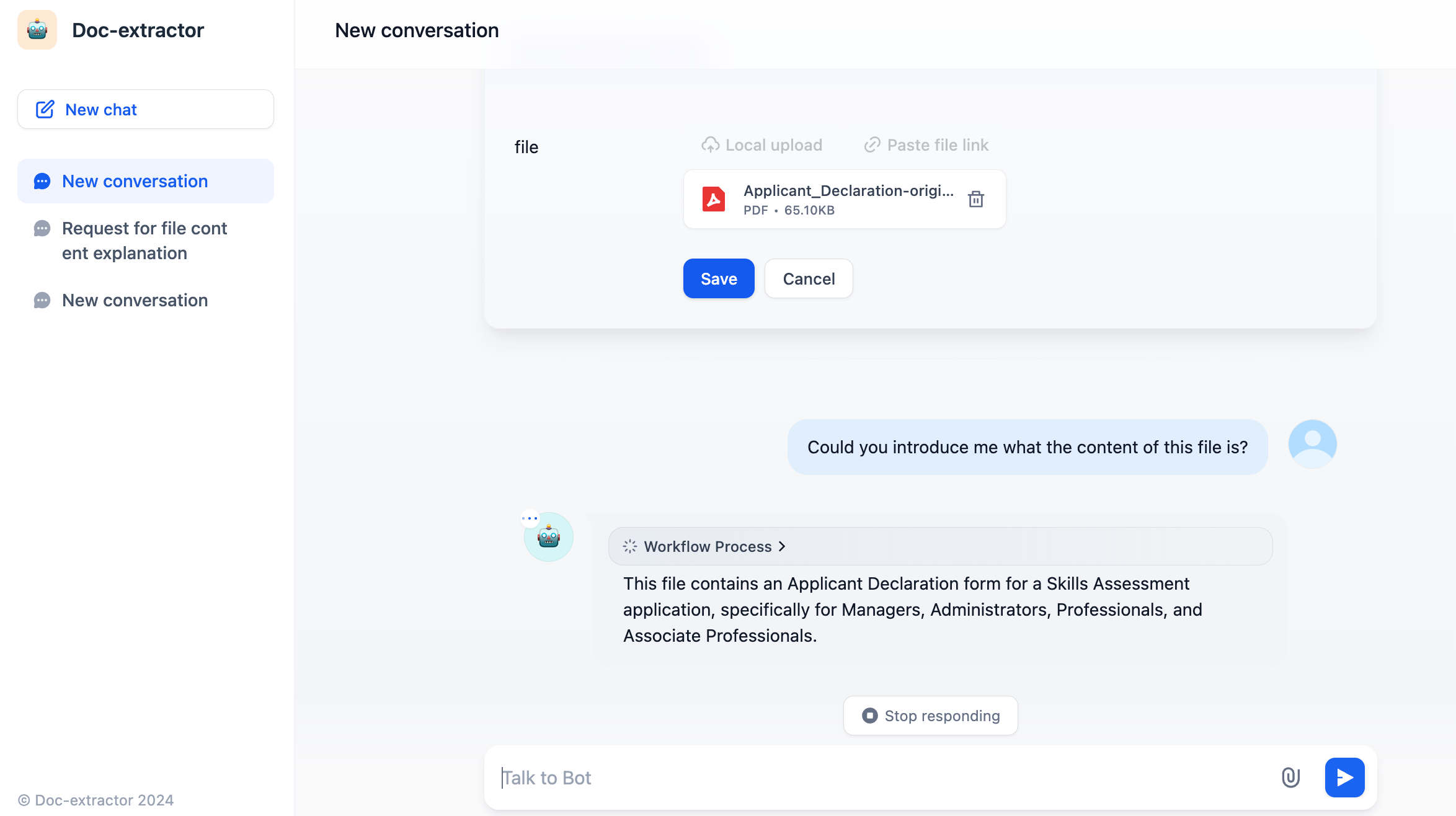 구성 후, 애플리케이션에는 파일 업로드 기능이 추가되어 사용자가 PDF 파일을 업로드하고 대화에 참여할 수 있습니다.
구성 후, 애플리케이션에는 파일 업로드 기능이 추가되어 사용자가 PDF 파일을 업로드하고 대화에 참여할 수 있습니다.
목록 연산자 #
페이지 복사
파일 목록 변수는 문서 파일, 이미지, 오디오, 비디오 파일 등 여러 파일 유형을 동시에 업로드할 수 있도록 지원합니다. 애플리케이션 사용자가 파일을 업로드하면 모든 파일이 동일한 Array[File]배열 유형 변수 에 저장되므로 이후 개별 파일 처리에 적합하지 않습니다.
데이터
Array유형은 변수의 실제 값이 [1.mp3, 2.png, 3.doc]일 수 있음을 의미합니다. LLM은 이미지 파일이나 텍스트 콘텐츠와 같은 단일 값만 입력 변수로 읽을 수 있으며, 배열 변수를 직접 읽을 수는 없습니다.
노드 기능 #
목록 연산자는 파일 형식 유형, 파일 이름, 크기와 같은 속성을 필터링하고 추출하여 다양한 형식의 파일을 해당 처리 노드에 전달하여 다양한 파일 처리 흐름을 정밀하게 제어할 수 있습니다.예를 들어, 사용자가 문서 파일과 이미지 파일을 동시에 업로드할 수 있는 애플리케이션에서 서로 다른 파일을 목록 작업 노드를 통해 정렬해야 하며 , 서로 다른 파일은 서로 다른 프로세스에 의해 처리되어야 합니다.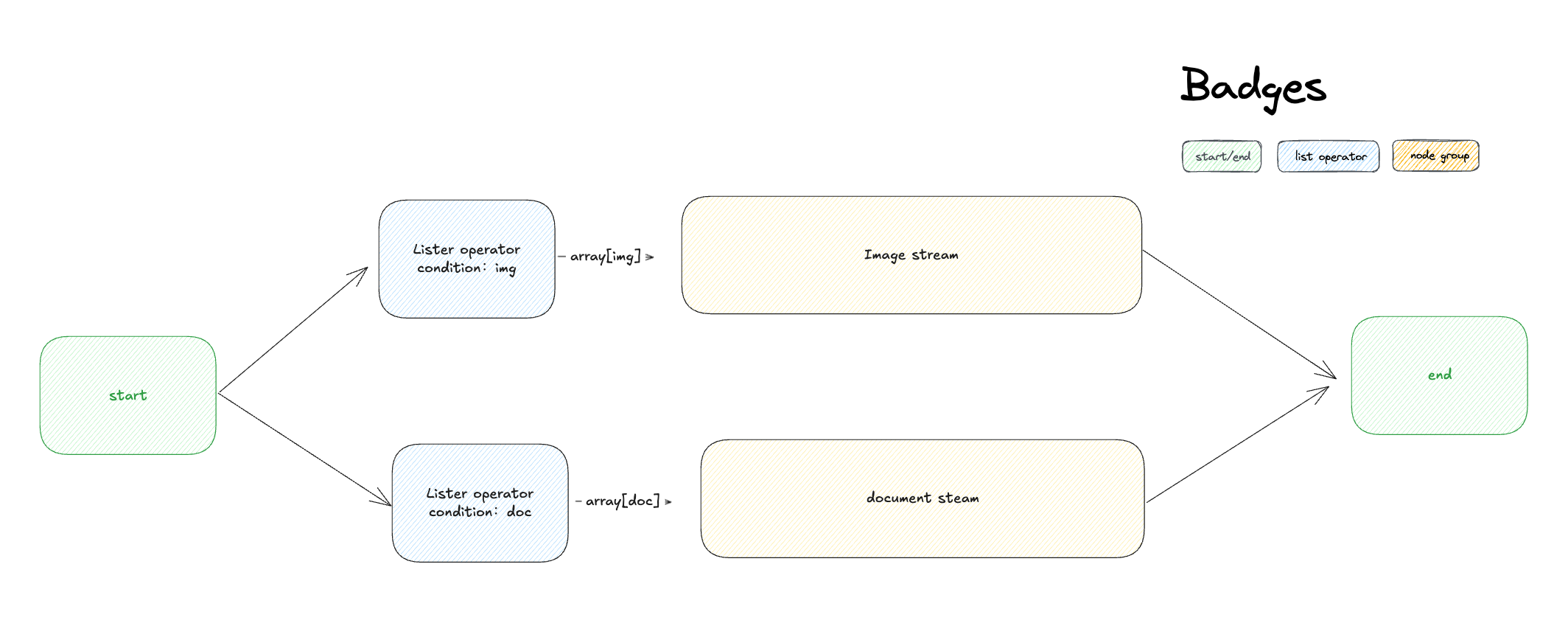 리스트 연산 노드는 일반적으로 배열 변수에서 정보를 추출하여, 조건 설정을 통해 하위 노드에서 수용할 수 있는 변수 유형으로 변환하는 데 사용됩니다. 리스트 연산 노드의 구조는 입력 변수, 필터 조건, 정렬, 처음 N개 항목 가져오기, 그리고 출력 변수로 나뉩니다.
리스트 연산 노드는 일반적으로 배열 변수에서 정보를 추출하여, 조건 설정을 통해 하위 노드에서 수용할 수 있는 변수 유형으로 변환하는 데 사용됩니다. 리스트 연산 노드의 구조는 입력 변수, 필터 조건, 정렬, 처음 N개 항목 가져오기, 그리고 출력 변수로 나뉩니다.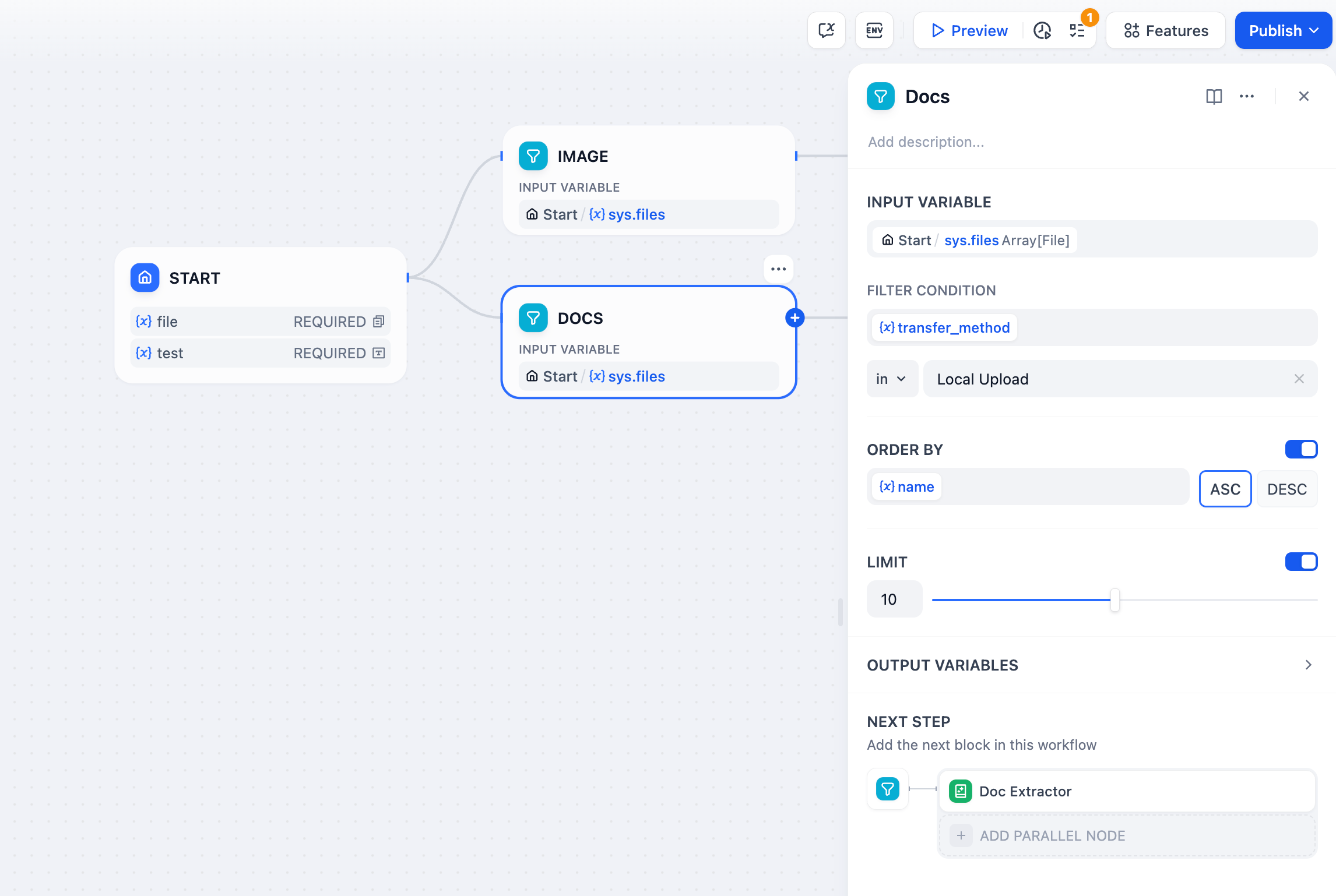 입력 변수목록 작업 노드는 다음 데이터 구조를 가진 변수만 허용합니다.
입력 변수목록 작업 노드는 다음 데이터 구조를 가진 변수만 허용합니다.
- 배열[문자열]
- 배열[숫자]
- 배열[파일]
필터 조건필터 조건을 추가하여 입력 변수의 배열을 처리합니다. 배열의 조건을 충족하는 모든 배열 변수를 정렬합니다. 이는 변수의 속성을 필터링하는 것으로 이해할 수 있습니다.예: 파일에는 파일 이름, 파일 유형, 파일 크기 등 여러 차원의 속성이 포함될 수 있습니다. 필터 조건을 사용하면 배열 변수에서 특정 파일을 선택하고 추출하기 위한 스크리닝 조건을 설정할 수 있습니다.다음 변수 추출을 지원합니다.
- 유형: 이미지, 문서, 오디오, 비디오 유형을 포함한 파일 범주
- 크기: 파일 크기
- 이름: 파일 이름
- url: URL을 통해 애플리케이션 사용자가 업로드한 파일을 참조합니다. 필터링을 위해 전체 URL을 입력할 수 있습니다.
- 확장자: 파일 확장자
- mime_type: MIME 유형은 파일 콘텐츠 유형을 식별하는 데 사용되는 표준화된 문자열입니다. 예: “text/html”은 HTML 문서를 나타냅니다.
- transfer_method: 파일 업로드 방법으로 로컬 업로드와 URL 업로드로 구분됨
정렬파일 속성에 따른 정렬을 지원하여 입력 변수의 배열을 정렬하는 기능을 제공합니다.
- 오름차순(ASC): 기본 정렬 옵션으로, 작은 것부터 큰 것 순으로 정렬합니다. 문자와 텍스트는 알파벳순(A – Z)으로 정렬합니다.
- 내림차순(DESC): 큰 것부터 작은 것 순으로 정렬하며, 문자와 텍스트는 알파벳 역순(Z – A)으로 정렬합니다.
이 옵션은 종종 출력 변수의 first_record 및 last_record와 함께 사용됩니다.첫 번째 N개 항목 가져오기1~20 사이의 값을 선택할 수 있으며, 이는 배열 변수의 처음 n개 항목을 선택하는 데 사용됩니다.출력 변수모든 필터 조건을 충족하는 배열 요소입니다. 필터 조건, 정렬 및 제한 사항은 개별적으로 활성화할 수 있습니다. 동시에 활성화하면 모든 조건을 충족하는 배열 요소가 반환됩니다.
- 결과: 필터링 결과, 데이터 유형은 배열 변수입니다. 배열에 파일이 하나만 포함된 경우, 출력 변수에는 배열 요소가 하나만 포함됩니다.
- first_record: 필터링된 배열의 첫 번째 요소, 즉 result[0]
- last_record: 필터링된 배열의 마지막 요소, 즉 result[array.length-1].
구성 예 #
파일 상호작용 Q&A 시나리오에서 애플리케이션 사용자는 문서 파일이나 이미지 파일을 동시에 업로드할 수 있습니다. LLM은 이미지 파일 인식 기능만 지원하며 문서 파일 읽기 기능은 지원하지 않습니다. 이 경우, 파일 변수 배열을 전처리하고 다양한 파일 유형을 해당 처리 노드로 전송하기 위해 목록 작업 노드가 필요합니다. 오케스트레이션 단계는 다음과 같습니다.
- 기능 기능을 활성화 하고 파일 형식에서 “이미지”와 “문서” 유형을 모두 선택하세요.
- 두 개의 목록 작업 노드를 추가하고 “목록 연산자” 조건에서 각각 이미지와 문서 변수를 추출하도록 설정합니다.
- 문서 파일 변수를 추출하여 “Doc Extractor” 노드로 전달합니다. 이미지 파일 변수를 추출하여 “LLM” 노드로 전달합니다.
- LLM 노드의 출력 변수를 채워서 마지막에 “답변” 노드를 추가합니다.
 애플리케이션 사용자가 문서 파일과 이미지를 모두 업로드하면 문서 파일은 자동으로 문서 추출 노드로, 이미지 파일은 자동으로 LLM 노드로 전환되어 혼합된 파일의 공동 처리가 달성됩니다.
애플리케이션 사용자가 문서 파일과 이미지를 모두 업로드하면 문서 파일은 자동으로 문서 추출 노드로, 이미지 파일은 자동으로 LLM 노드로 전환되어 혼합된 파일의 공동 처리가 달성됩니다.
변수 집계기 #
페이지 복사
1 정의 #
다운스트림 노드에 대한 통합된 구성을 달성하기 위해 여러 분기의 변수를 단일 변수로 집계합니다.변수 집계 노드(이전에는 변수 할당 노드)는 워크플로의 핵심 노드입니다. 여러 분기의 출력 결과를 통합하여 어떤 분기가 실행되든 통합된 변수를 통해 해당 결과를 참조하고 액세스할 수 있도록 합니다. 이는 여러 분기가 있는 상황에서 특히 유용한데, 여러 분기의 동일한 함수를 갖는 변수들을 단일 출력 변수로 매핑하여 다운스트림 노드에서 반복적인 정의를 방지할 수 있기 때문입니다.
2가지 시나리오 #
변수 집계를 통해 문제 분류나 조건 분기 등의 여러 출력을 단일 출력으로 집계하여 다운스트림 노드에서 사용하고 조작할 수 있으므로 데이터 흐름 관리가 간소화됩니다.이슈 분류 후 다중 지점 집계변수 집계가 없다면 분류 1과 분류 2의 분기는 서로 다른 지식 기반 검색을 거친 후 하위 LLM과 직접 응답 노드에 대해 반복적인 정의가 필요할 것입니다.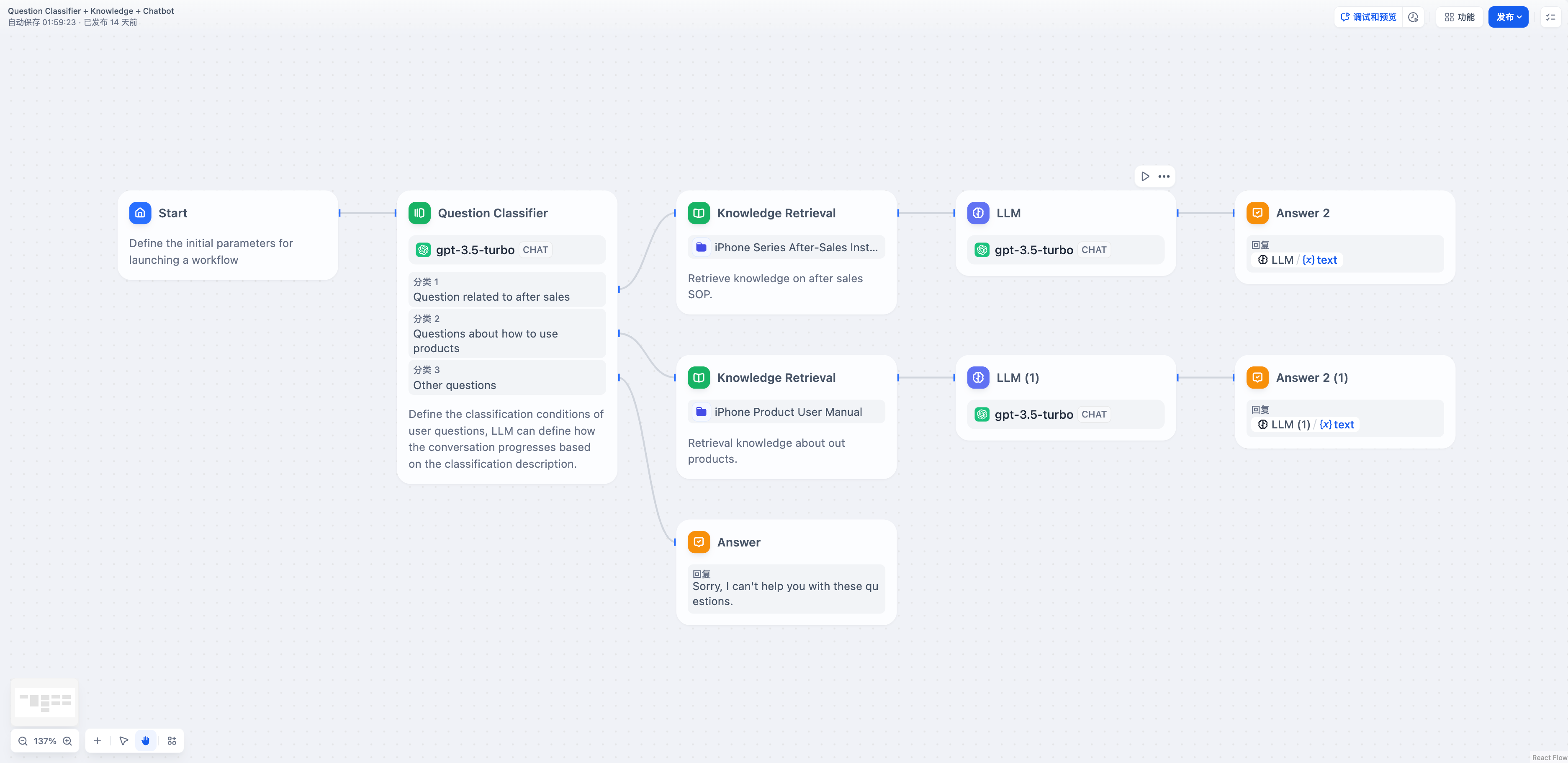 변수 집계를 추가하면 두 개의 지식 검색 노드의 출력을 단일 변수로 집계할 수 있습니다.
변수 집계를 추가하면 두 개의 지식 검색 노드의 출력을 단일 변수로 집계할 수 있습니다.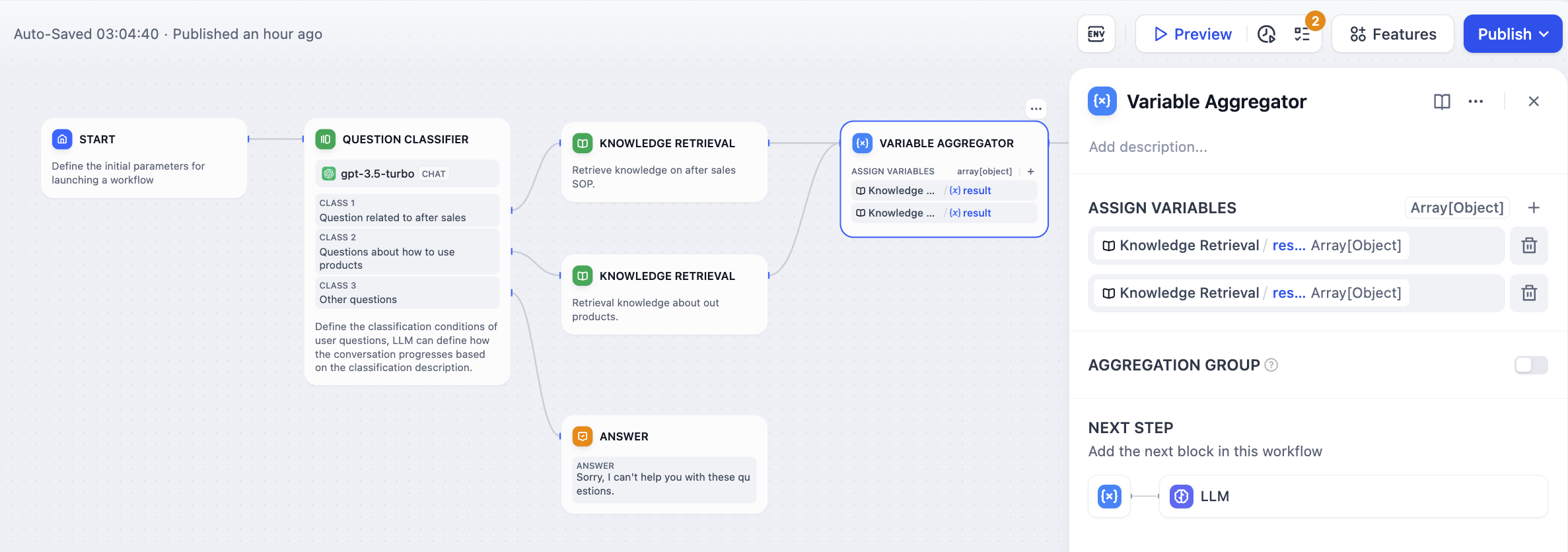 IF/ELSE 조건 분기 후 다중 분기 집계
IF/ELSE 조건 분기 후 다중 분기 집계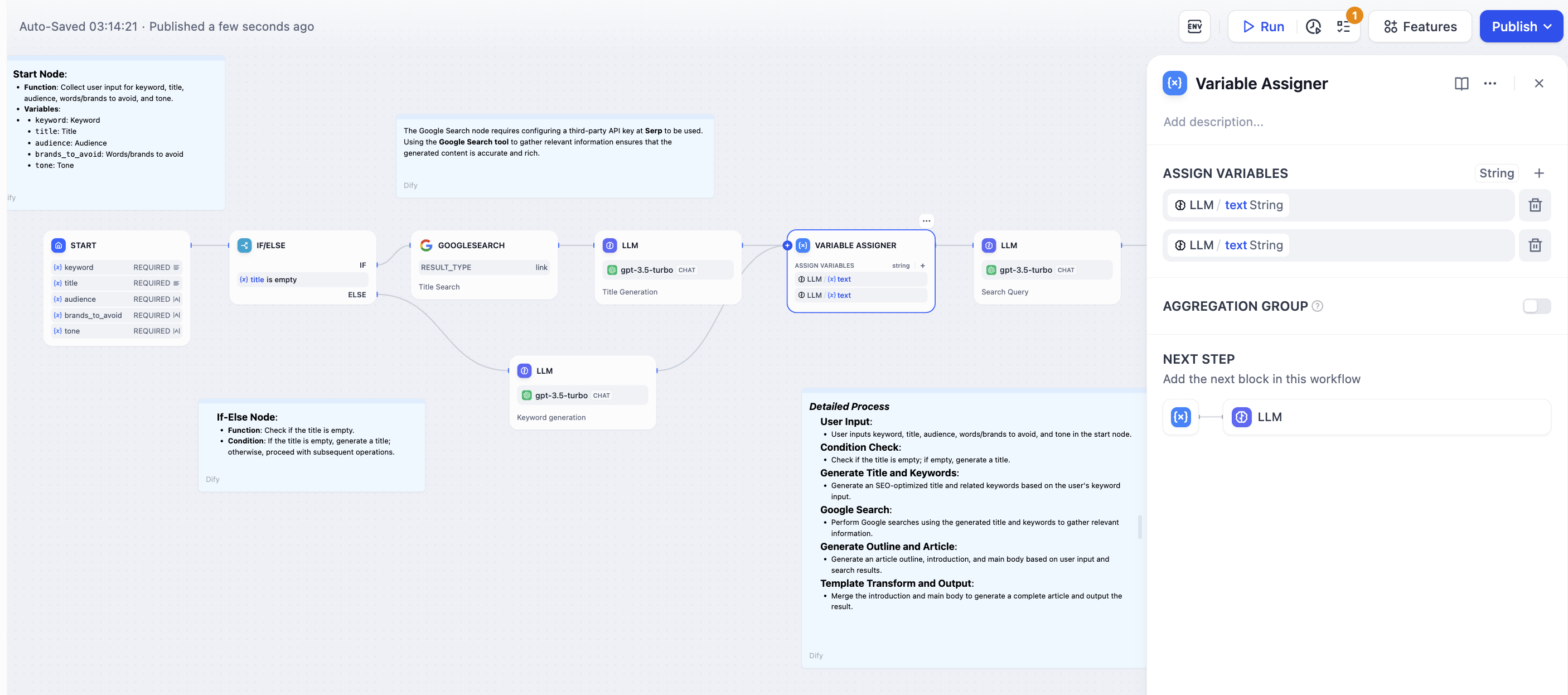
3 형식 요구 사항 #
변수 집계기는 문자열( String), 숫자( Number), 객체( Object), 배열( Array)을 포함한 다양한 데이터 유형의 집계를 지원합니다.변수 집계기는 동일한 데이터 유형의 변수만 집계할 수 있습니다 . 변수 집계 노드에 추가된 첫 번째 변수가 해당 데이터 유형이면 String, 이후 연결은 자동으로 필터링되어 String유형 변수만 추가되도록 허용합니다.집계 그룹화버전 v0.6.10부터 집계 그룹화가 지원됩니다.집계 그룹화가 활성화되면 변수 집계기는 여러 변수 그룹을 집계할 수 있으며, 각 그룹은 집계에 동일한 데이터 유형을 요구합니다.
변수 할당자 #
페이지 복사
정의 #
변수 할당자 노드는 쓰기 가능한 변수에 값을 할당하는 데 사용됩니다. 현재 지원되는 쓰기 가능한 변수는 다음과 같습니다.
- 대화 변수 .
사용법: 변수 할당자 노드를 통해 워크플로 변수를 대화 변수에 할당하여 임시로 저장할 수 있으며, 이후 대화에서 지속적으로 참조할 수 있습니다.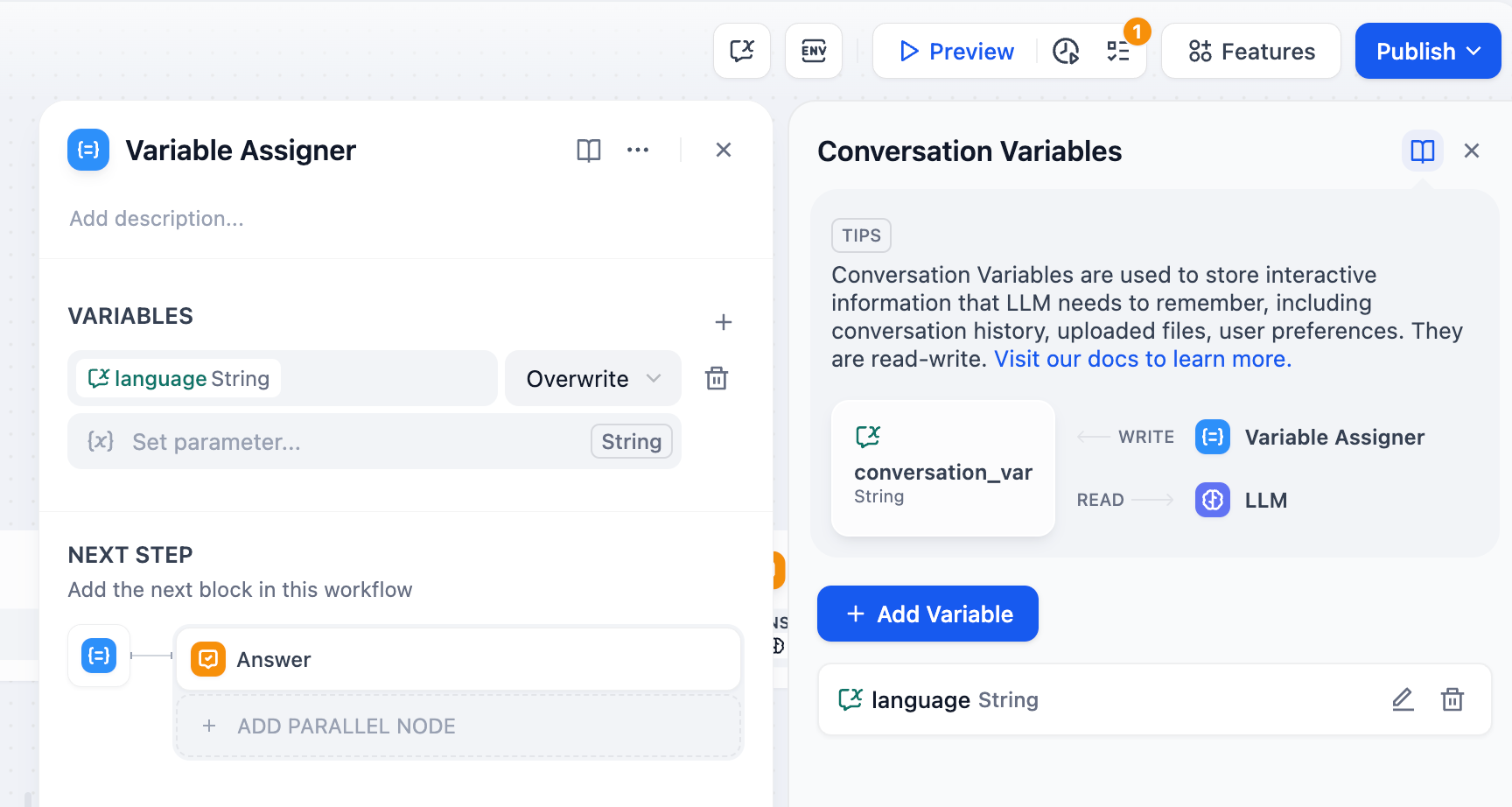
사용 시나리오 예 #
변수 할당자 노드를 사용하면 대화 프로세스의 컨텍스트, 대화 상자에 업로드된 파일, 그리고 사용자 선호도 정보를 대화 변수에 기록할 수 있습니다. 이렇게 저장된 변수는 이후 대화에서 참조되어 다양한 처리 흐름을 지시하거나 응답을 작성할 수 있습니다.시나리오 1자동으로 내용을 판단하고 추출하고 , 대화의 내역을 저장하고, 대화 내의 세션 변수 배열을 통해 중요한 사용자 정보를 기록하고, 이 내역 내용을 사용하여 후속 채팅에서 응답을 개인화합니다.예: 대화가 시작된 후, LLM은 사용자 입력 내용에 기억해야 할 사실, 선호도 또는 채팅 기록이 포함되어 있는지 자동으로 판단합니다. 만약 포함되어 있다면, LLM은 먼저 해당 정보를 추출하여 저장한 후, 이를 맥락으로 활용하여 답변합니다. 기억할 새로운 정보가 없다면, LLM은 이전에 기억했던 관련 정보를 바로 활용하여 질문에 답변합니다.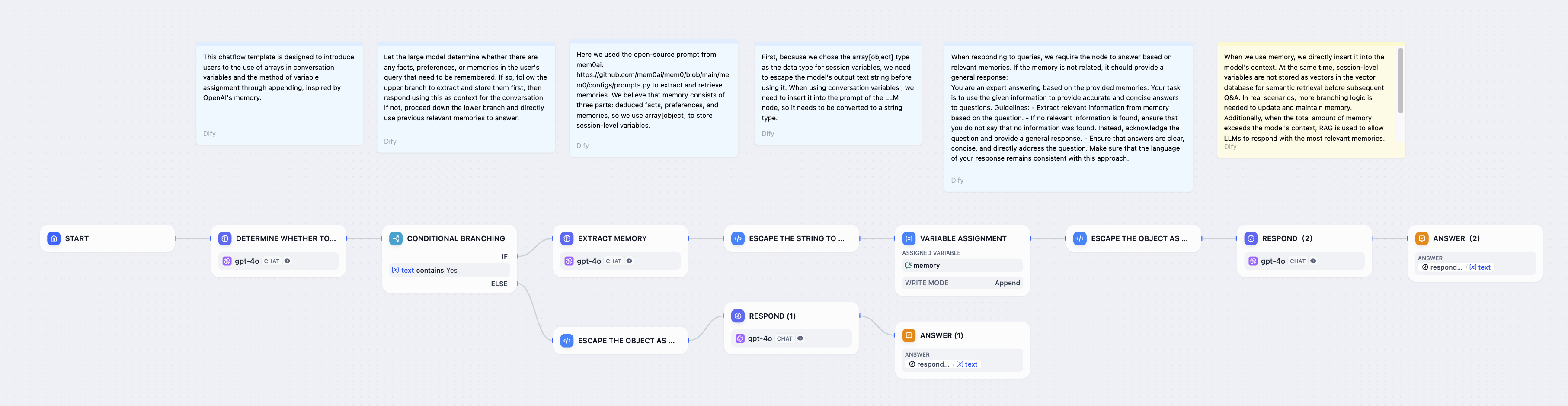 구성 프로세스:
구성 프로세스:
- 대화 변수 설정:
memories먼저, 사용자 정보, 기본 설정, 채팅 기록을 저장하기 위해 array[object] 유형의 대화 변수 배열을 설정합니다 .
- 기억을 확인하고 추출합니다.
- LLM을 사용하여 사용자 입력에 기억해야 할 새로운 정보가 포함되어 있는지 여부를 확인하는 조건 분기 노드를 추가합니다.
- 새로운 정보가 있으면 상위 분기를 따라가고 LLM 노드를 사용하여 이 정보를 추출합니다.
- 새로운 정보가 없다면, 가지를 따라 내려가서 기존의 기억을 직접 사용하여 대답하세요.
- 변수 할당/쓰기:
- 상위 분기에서 변수 할당자 노드를 사용하여 새로 추출한 정보를
memories배열에 추가합니다. - 이스케이프 함수를 사용하여 LLM에서 출력된 텍스트 문자열을 배열[객체]에 저장하기에 적합한 형식으로 변환합니다.
- 상위 분기에서 변수 할당자 노드를 사용하여 새로 추출한 정보를
- 변수 판독 및 사용:
- 이후 LLM 노드에서 배열의 내용을
memories문자열로 변환하여 LLM 프롬프트에 컨텍스트로 삽입합니다. - 이러한 기억을 활용해 개인화된 응답을 생성하세요.
- 이후 LLM 노드에서 배열의 내용을
위 다이어그램의 노드에 대한 코드는 다음과 같습니다.
- 문자열을 객체로 이스케이프합니다.
복사AI에게 물어보세요
import json
def main(arg1: str) -> object:
try:
# Parse the input JSON string
input_data = json.loads(arg1)
# Extract the memory object
memory = input_data.get("memory", {})
# Construct the return object
result = {
"facts": memory.get("facts", []),
"preferences": memory.get("preferences", []),
"memories": memory.get("memories", [])
}
return {
"mem": result
}
except json.JSONDecodeError:
return {
"result": "Error: Invalid JSON string"
}
except Exception as e:
return {
"result": f"Error: {str(e)}"
}
- 객체를 문자열로 이스케이프합니다.
복사AI에게 물어보세요
import json
def main(arg1: list) -> str:
try:
# Assume arg1[0] is the dictionary we need to process
context = arg1[0] if arg1 else {}
# Construct the memory object
memory = {"memory": context}
# Convert the object to a JSON string
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
# Wrap the JSON string in <answer> tags
result = f"<answer>{json_str}</answer>"
return {
"result": result
}
except Exception as e:
return {
"result": f"<answer>Error: {str(e)}</answer>"
}
시나리오 2초기 사용자 환경 설정 입력 기록 : 대화 중에 사용자의 언어 환경 설정 입력을 기억하고 이후 채팅에서 응답할 때 이 언어를 계속 사용합니다.예: 채팅 전에 사용자가 language입력란에 “영어”를 지정합니다. 이 언어는 대화 변수에 기록되고, LLM은 응답 시 이 정보를 참조하여 이후 대화에서도 “영어”를 계속 사용합니다.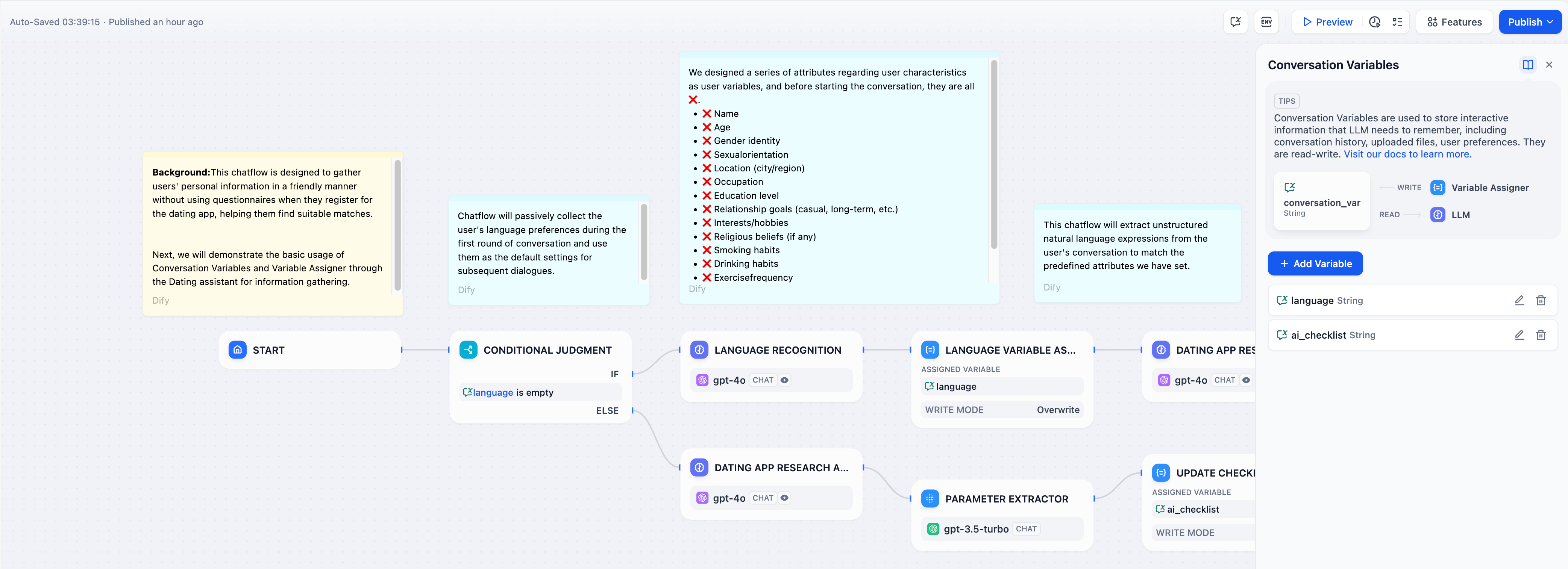 구성 가이드:대화 변수 설정 : 먼저 대화 변수를 설정합니다
구성 가이드:대화 변수 설정 : 먼저 대화 변수를 설정합니다 language. 대화 흐름 시작 부분에 조건 판단 노드를 추가하여 language변수가 비어 있는지 확인합니다.변수 쓰기/할당 : 첫 번째 채팅 라운드가 시작될 때 language변수가 비어 있으면 LLM 노드를 사용하여 사용자의 입력 언어를 추출한 다음 변수 할당자 노드를 사용하여 이 언어 유형을 대화 변수에 씁니다 language.변수 읽기 : 이후 대화 라운드에서 language변수는 사용자의 언어 선호도를 저장합니다. LLM 노드는 언어 변수를 참조하여 사용자가 선호하는 언어 유형을 사용하여 응답합니다.시나리오 3체크리스트 점검 지원 : 대화 변수를 사용하여 대화 내 사용자 입력을 기록하고, 체크리스트의 내용을 업데이트하고, 후속 대화에서 누락된 항목을 확인합니다.예: 대화 시작 후, LLM은 사용자에게 채팅 상자에 체크리스트 관련 항목을 입력하도록 요청합니다. 사용자가 체크리스트의 내용을 언급하면 해당 내용이 업데이트되어 대화 변수에 저장됩니다. LLM은 각 대화 라운드가 끝날 때마다 사용자에게 누락된 항목을 계속 보충하도록 알려줍니다.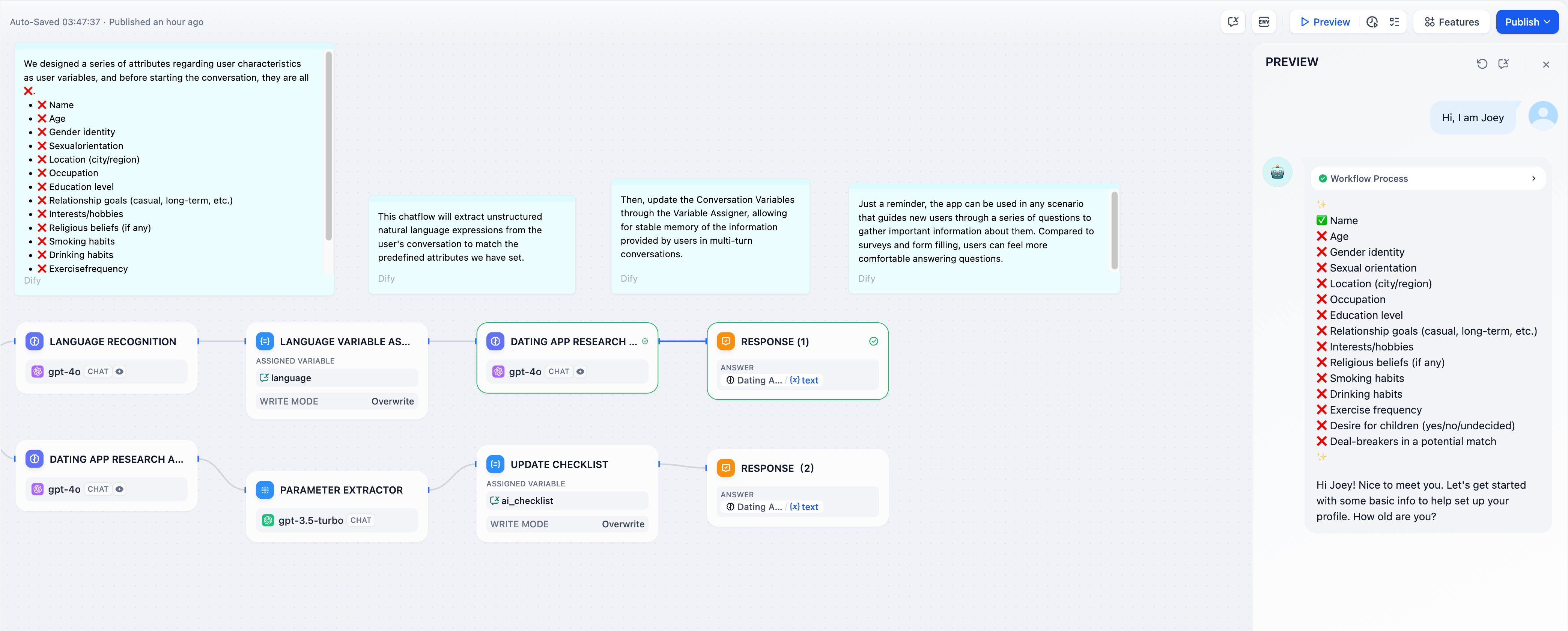 구성 프로세스:
구성 프로세스:
- 대화 변수 설정: 먼저 대화 변수를 설정하고
ai_checklist, LLM 내에서 이 변수를 참조하여 검사를 위한 컨텍스트로 사용합니다. - 변수 할당자/작성 : 각 대화 라운드 동안
ai_checklistLLM 노드 내의 값을 확인하고 사용자 입력과 비교합니다. 사용자가 새로운 정보를 제공하면 체크리스트를 업데이트하고ai_checklist변수 할당자 노드를 사용하여 출력 내용을 작성합니다. - 변수 읽기: 대화의 각 라운드에서 값을 읽고
ai_checklist사용자 입력과 비교하여 체크리스트의 모든 항목이 완료될 때까지 진행합니다.
변수 할당자 노드 사용 #
+노드 오른쪽의 아이콘을 클릭 하고 “변수 할당” 노드를 선택하세요. 대상 변수와 해당 소스 변수를 설정하세요. 이 노드를 사용하면 여러 변수에 동시에 값을 할당할 수 있습니다.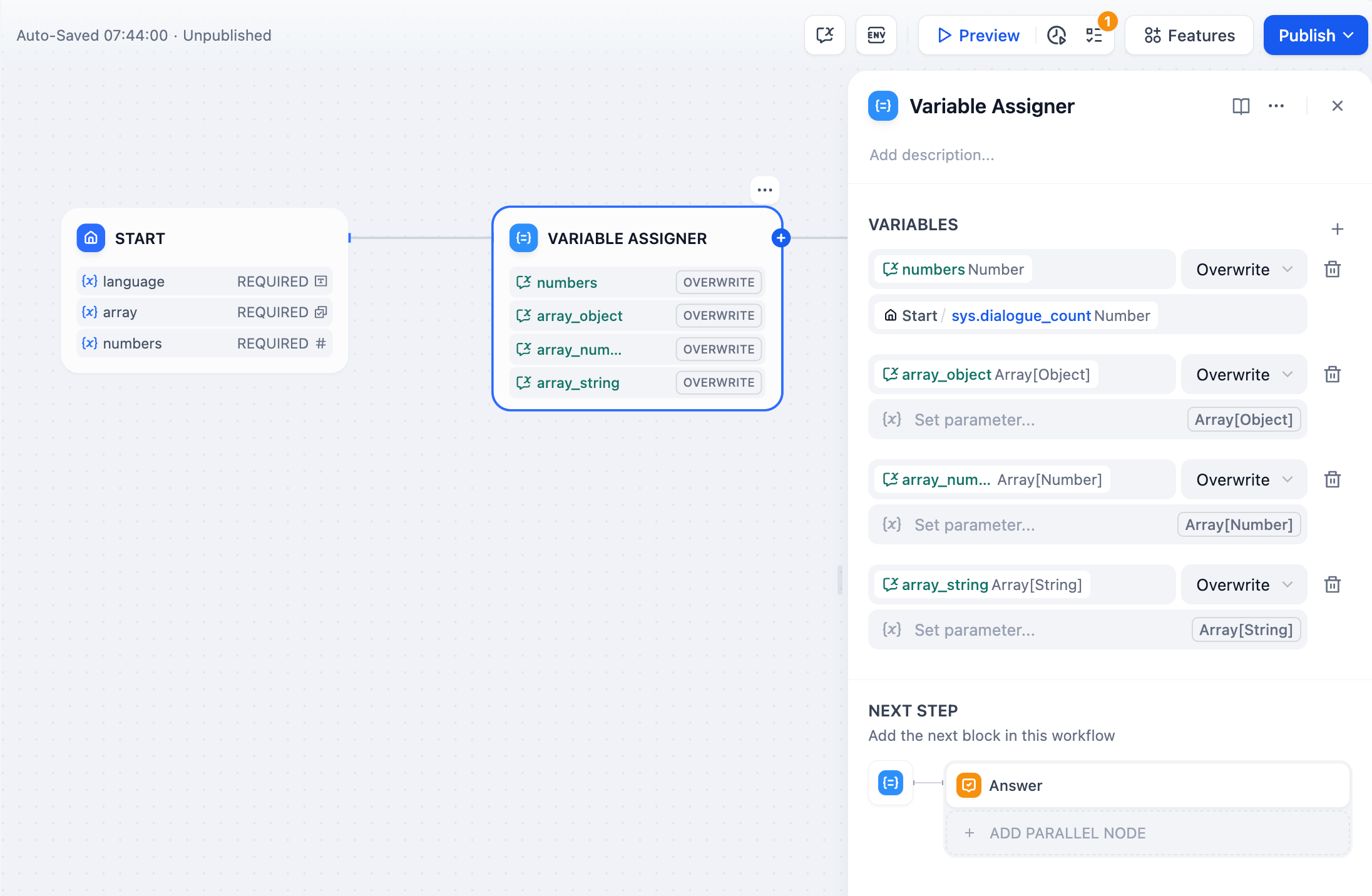 변수 설정:변수: 할당할 변수를 선택합니다. 즉, 할당해야 할 대상 대화 변수를 지정합니다.변수 설정: 할당할 변수를 선택합니다. 즉, 변환해야 할 소스 변수를 지정합니다.위 이미지에 나와 있는 변수 할당 논리는 초기 페이지에서 지정한 사용자의 언어 기본 설정을
변수 설정:변수: 할당할 변수를 선택합니다. 즉, 할당해야 할 대상 대화 변수를 지정합니다.변수 설정: 할당할 변수를 선택합니다. 즉, 변환해야 할 소스 변수를 지정합니다.위 이미지에 나와 있는 변수 할당 논리는 초기 페이지에서 지정한 사용자의 언어 기본 설정을 Start/language시스템 수준 대화 변수에 할당합니다 language.
변수 지정을 위한 작업 모드 #
대상 변수의 데이터 유형에 따라 연산 방식이 결정됩니다. 다음은 다양한 변수 유형에 따른 연산 방식입니다.
- 대상 변수 데이터 유형:
String• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 지정합니다. - 대상 변수 데이터 유형:
Number• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 할당합니다. • 산술 : 대상 변수에 덧셈, 뺄셈, 곱셈 또는 나눗셈을 수행합니다. - 대상 변수 데이터 유형:
Object• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 설정 : 소스 변수 없이 수동으로 값을 지정합니다. - 대상 변수 데이터 유형:
Array• 덮어쓰기 : 대상 변수를 소스 변수로 직접 덮어씁니다. • 지우기 : 선택한 대상 변수의 내용을 지웁니다. • 추가 : 대상 변수의 배열에 새 요소를 추가합니다. • 확장 : 대상 변수에 새 배열을 추가하여 여러 요소를 한 번에 추가합니다. • 제거 : 배열에서 요소를 제거합니다. 첫 번째 위치(First) 또는 마지막 위치(Last)에서 제거하는 옵션이 있으며, 기본값은 “First”입니다.
반복 #
페이지 복사
정의 #
모든 결과가 출력될 때까지 배열 요소에 대해 동일한 작업을 순차적으로 수행하여 작업 배치 프로세서 역할을 합니다. 반복 노드는 일반적으로 배열 변수와 함께 작동합니다.예를 들어, 긴 텍스트 번역을 처리할 때 모든 콘텐츠를 LLM 노드에 직접 입력하면 단일 대화 제한에 도달할 수 있습니다. 이 문제를 해결하기 위해 업스트림 노드는 먼저 긴 텍스트를 여러 개의 청크로 분할한 다음, 반복 노드를 사용하여 일괄 번역을 수행하여 단일 LLM 대화의 메시지 제한을 피합니다.
기능 설명 #
반복 노드를 사용하려면 입력 값을 목록 객체로 포맷해야 합니다. 이 노드는 반복 시작 노드부터 배열 변수의 모든 요소를 순차적으로 처리하며, 각 요소에 동일한 처리 단계를 적용합니다. 각 처리 주기를 반복이라고 하며, 최종 출력으로 마무리됩니다.반복 노드는 입력 변수 , 반복 워크플로 , 출력 변수라는 세 가지 핵심 구성 요소로 구성됩니다 .입력 변수: 배열 유형 데이터만 허용합니다.반복 워크플로: 반복 노드 내에서 작업 순서를 조정하기 위해 여러 워크플로 노드를 지원합니다.출력 변수: 배열 변수( Array[List])만 출력합니다.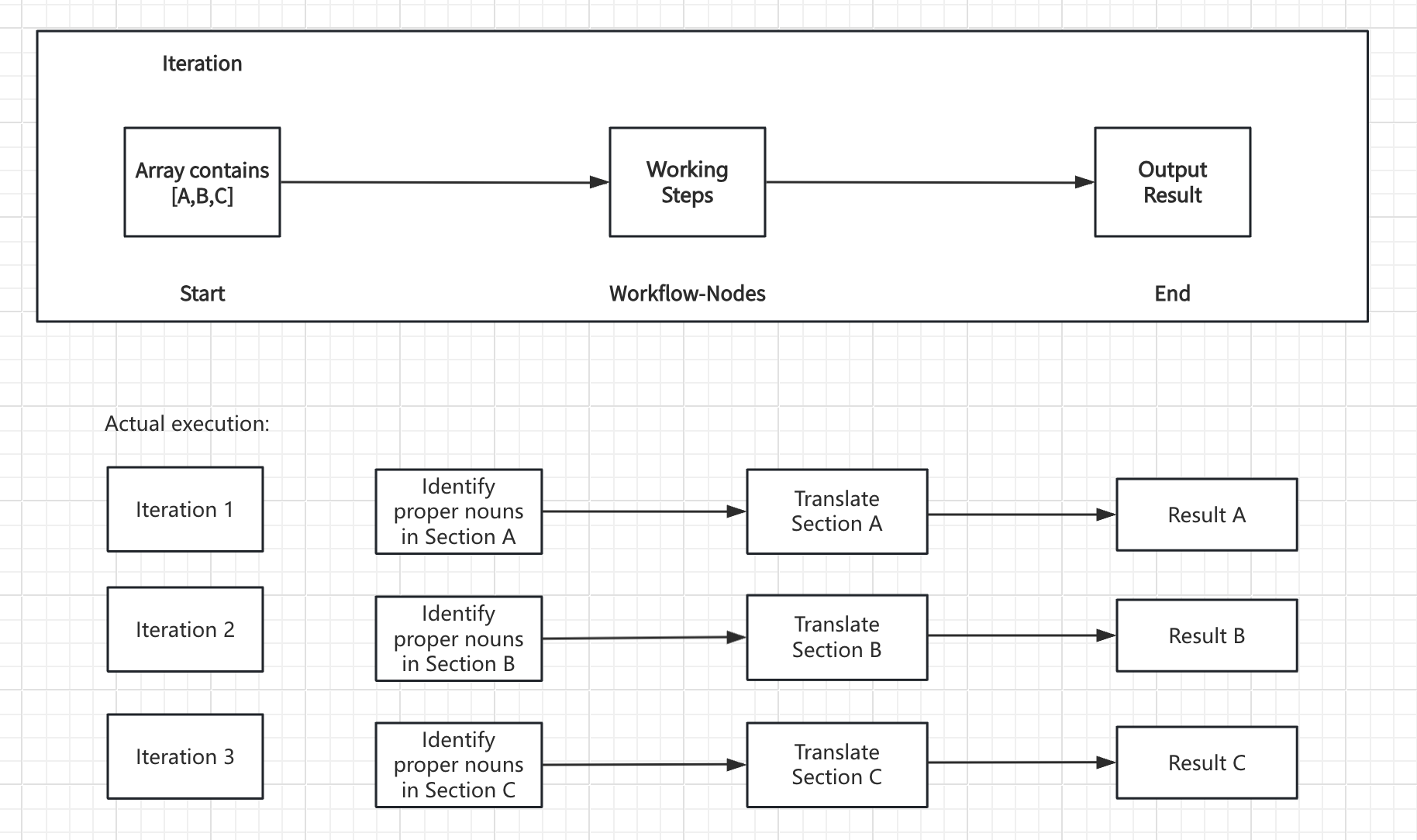
시나리오 #
예제 1: 긴 기사 반복 생성기 #
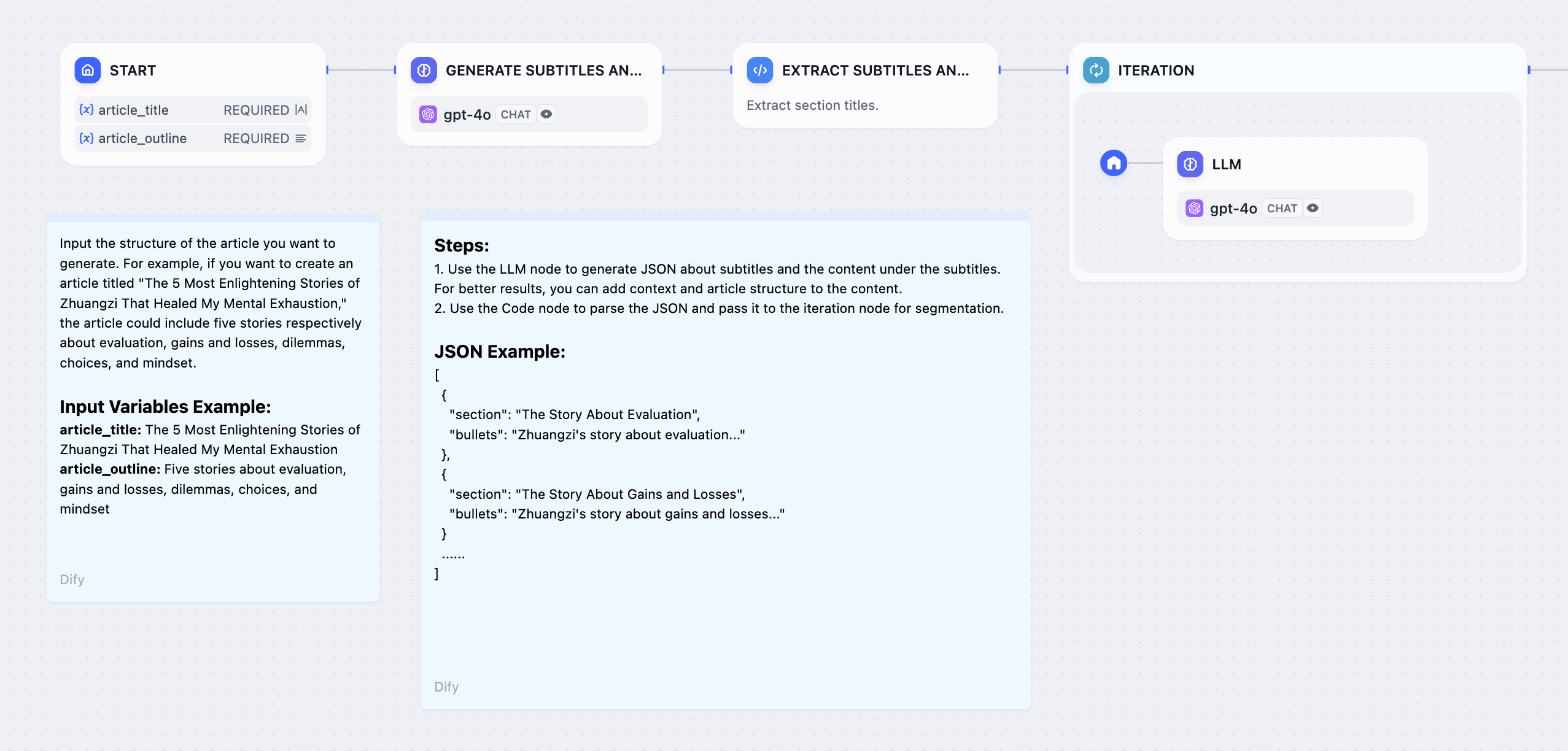
- 시작 노드 에 스토리 제목과 개요를 입력합니다 .
- LLM을 사용하여 사용자 입력으로부터 완전한 콘텐츠를 생성하려면 자막 및 개요 생성 노드를 사용하세요 .
- 자막 및 개요 추출 노드를 사용하여 전체 콘텐츠를 배열 형식으로 변환합니다.
- 반복 노드를 사용하여 LLM 노드를 래핑 하고 여러 반복을 통해 각 장의 콘텐츠를 생성합니다.
- 반복 노드 내부에 직접 답변 노드를 추가하여 각 반복 후에 스트리밍 출력을 얻습니다.
자세한 구성 단계
- 시작 노드 에서 스토리 제목(title)과 개요(outline)를 구성합니다 .
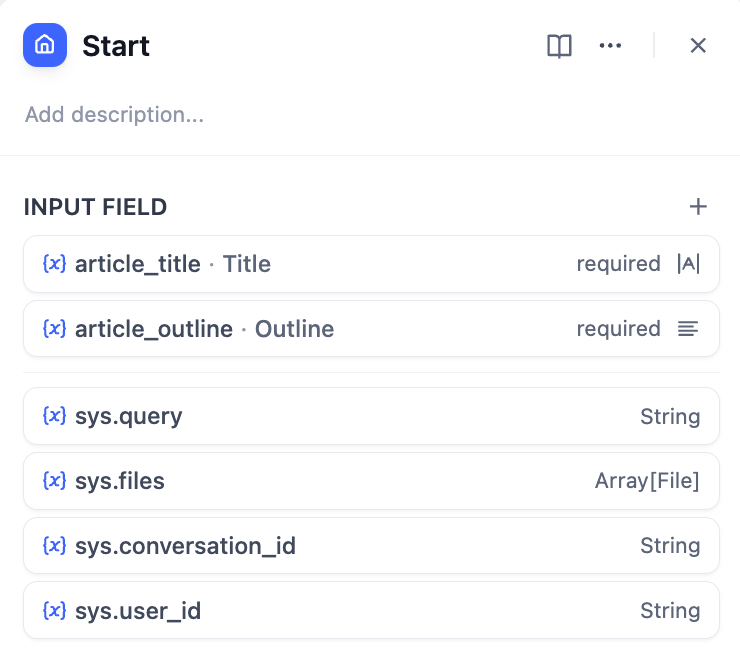
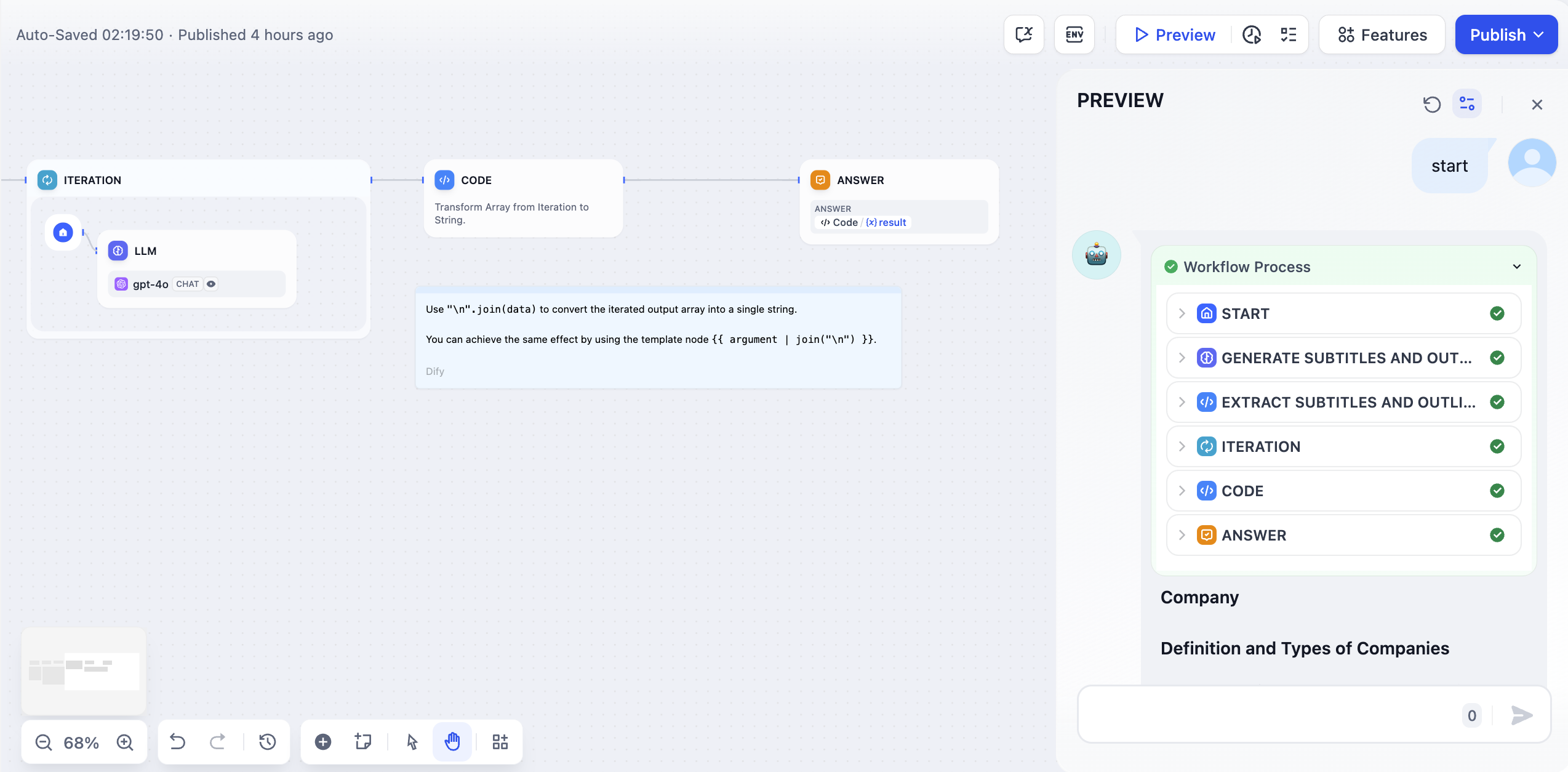
- ‘자막 및 개요 생성’ 노드를 사용하여 스토리 제목과 개요를 완전한 텍스트로 변환합니다.
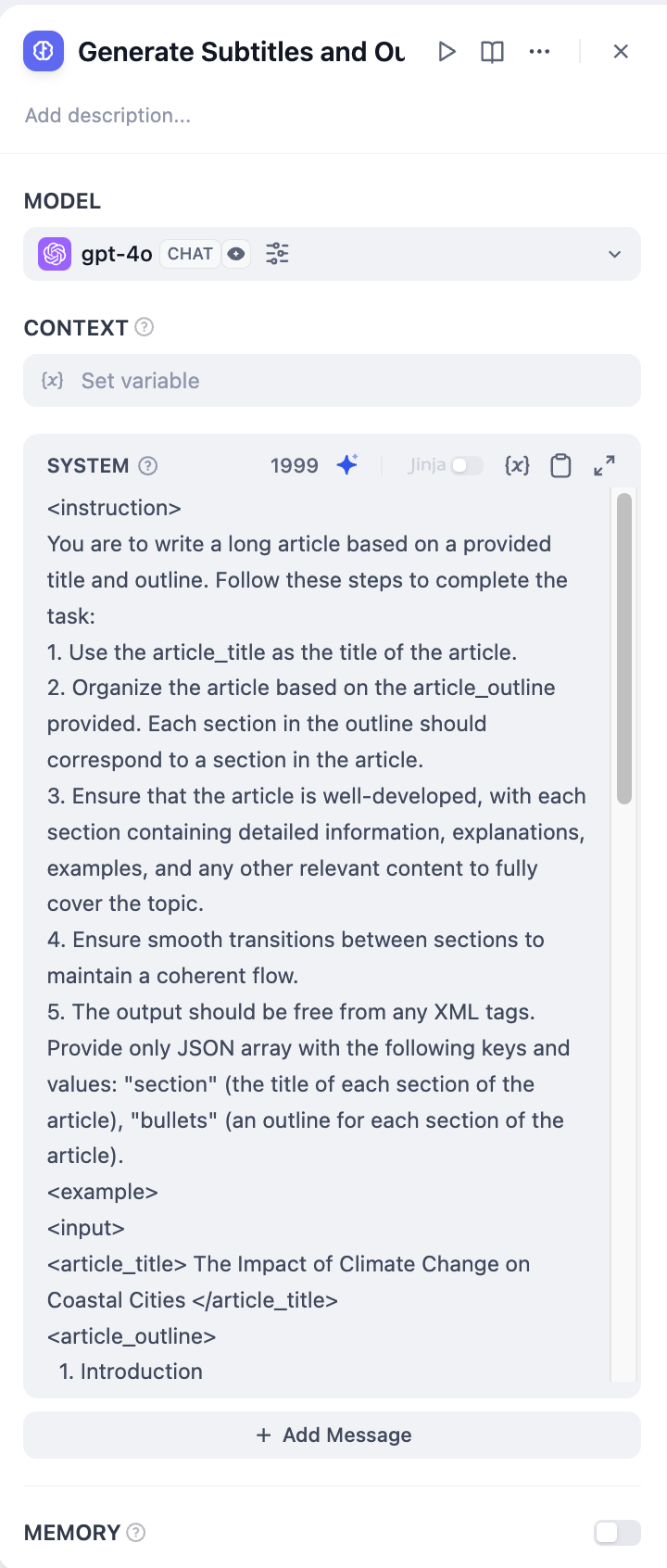
- ‘자막 및 개요 추출’ 노드를 사용하여 스토리 텍스트를 배열(Array) 구조로 변환합니다. 추출할 매개변수는
sections이고 매개변수 유형은 입니다Array[Object].
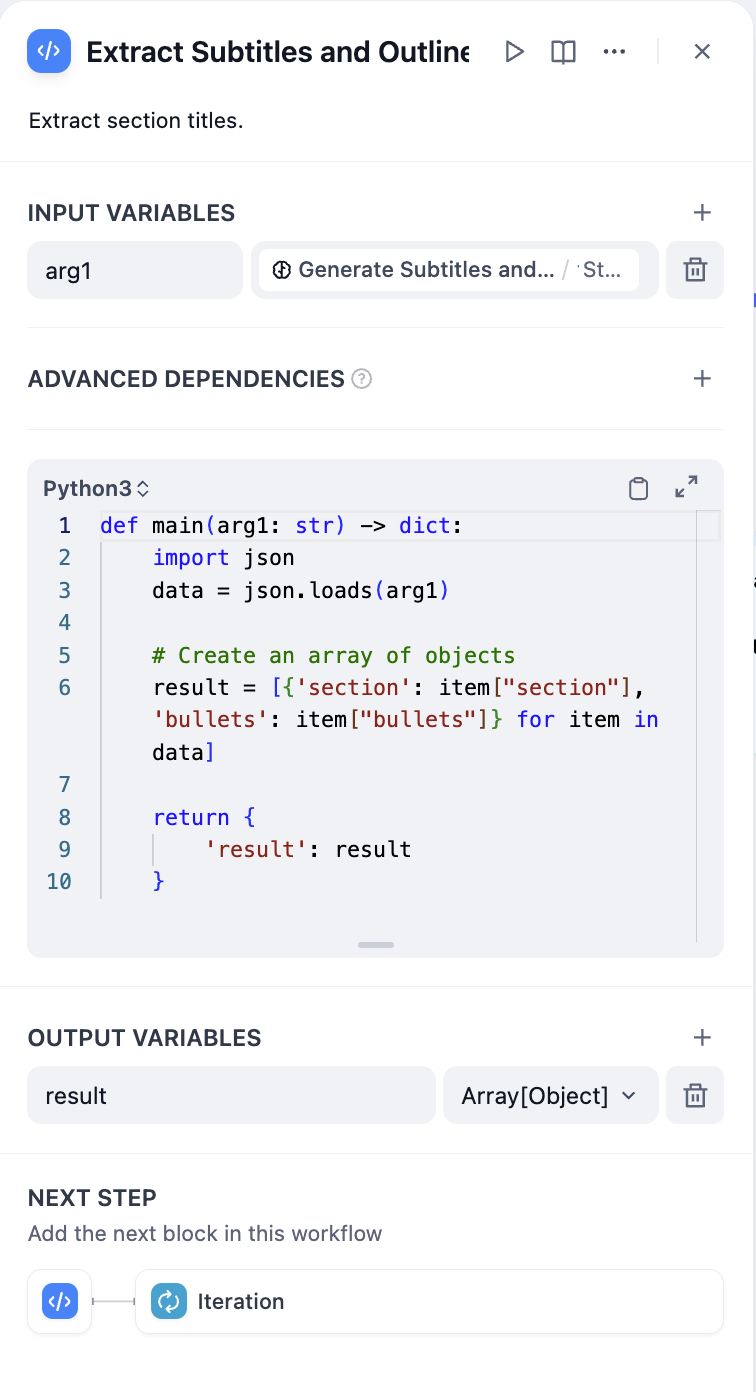
매개변수 추출의 효율성은 모델의 추론 능력과 제공된 지침에 따라 달라집니다. 추론 능력이 더 뛰어난 모델을 사용하고 지침 에 예시를 추가하면 매개변수 추출 결과를 개선할 수 있습니다.
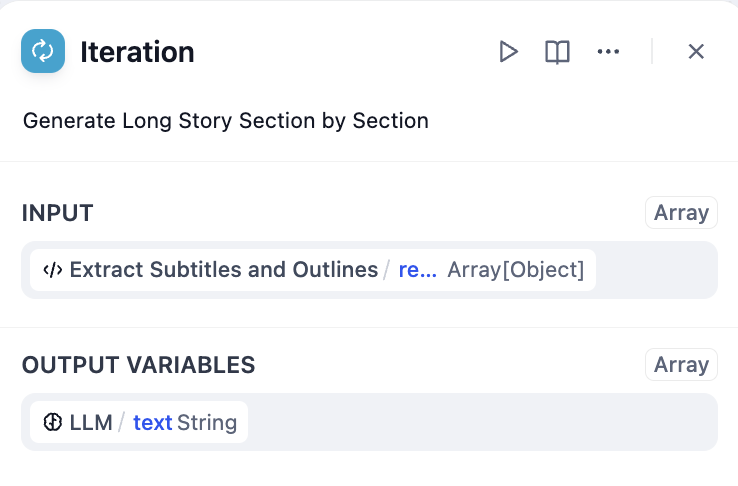
- 배열 형식의 스토리 개요를 반복 노드의 입력으로 사용하고 LLM 노드를 사용하여 반복 노드 내에서 이를 처리합니다 .
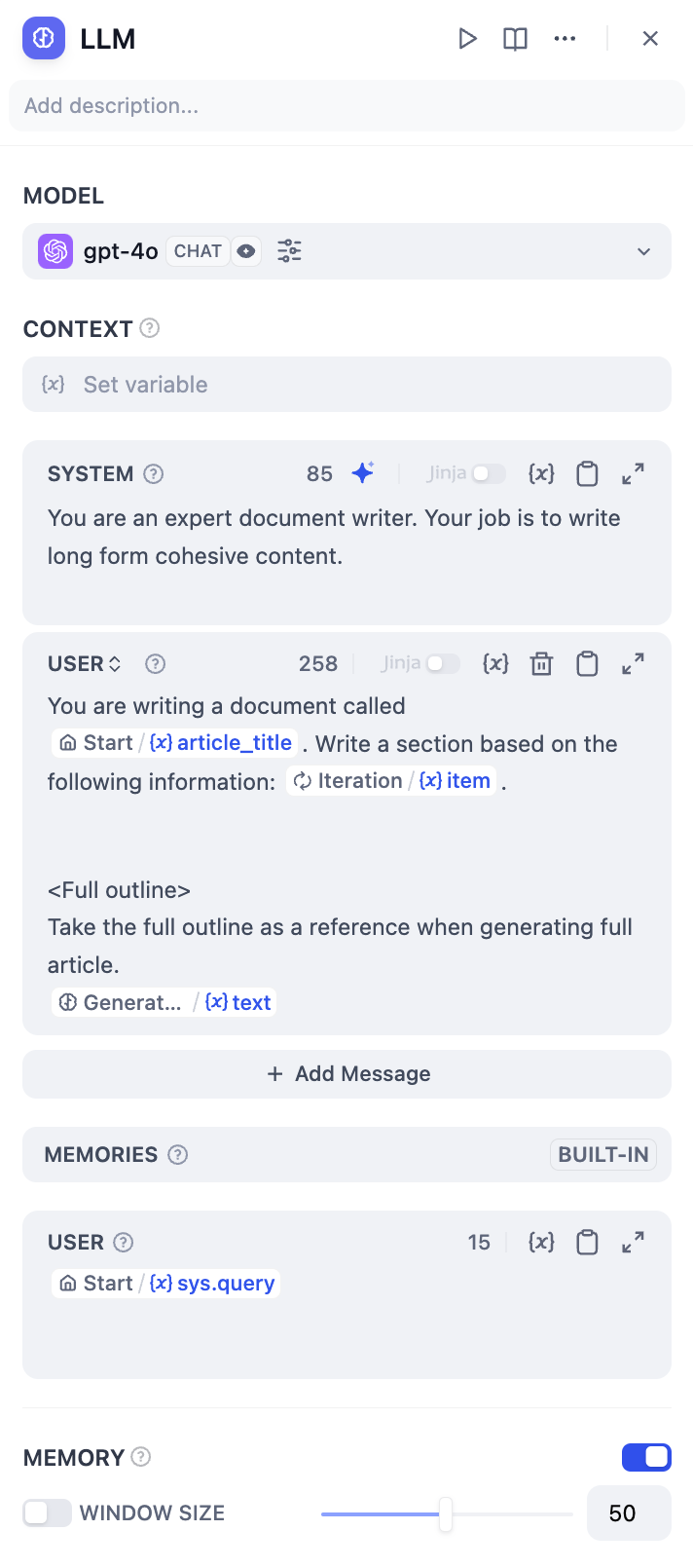
 LLM 노드에서 입력 변수를 구성합니다
LLM 노드에서 입력 변수를 구성합니다 GenerateOverallOutline/output.Iteration/item
반복을 위한 내장 변수: items[object]및 index[number].items[object]각 반복에 대한 입력 항목을 나타냅니다.index[number]현재 반복 라운드를 나타냅니다.
- 반복 노드 내부에 직접 응답 노드를 구성하여 각 반복 후 스트리밍 출력을 얻습니다.
- 디버깅과 미리보기가 완료되었습니다.
예 2: 긴 기사 반복 생성기(또 다른 배열) #

- 시작 노드 에 스토리 제목과 개요를 입력합니다 .
- LLM 노드를 사용하여 기사의 하위 제목과 해당 내용을 생성합니다.
- 코드 노드를 사용하여 전체 내용을 배열 형식으로 변환합니다.
- 반복 노드를 사용하여 LLM 노드를 래핑 하고 여러 반복을 통해 각 장의 콘텐츠를 생성합니다.
- 템플릿 변환 노드를 사용하여 반복 노드의 문자열 배열 출력을 다시 문자열로 변환합니다.
- 마지막으로, 변환된 문자열을 직접 출력하기 위해 직접 응답 노드를 추가합니다.
고급 기능 #
병렬 모드 #
반복 노드는 병렬 처리를 지원하여 활성화 시 실행 효율성이 향상됩니다.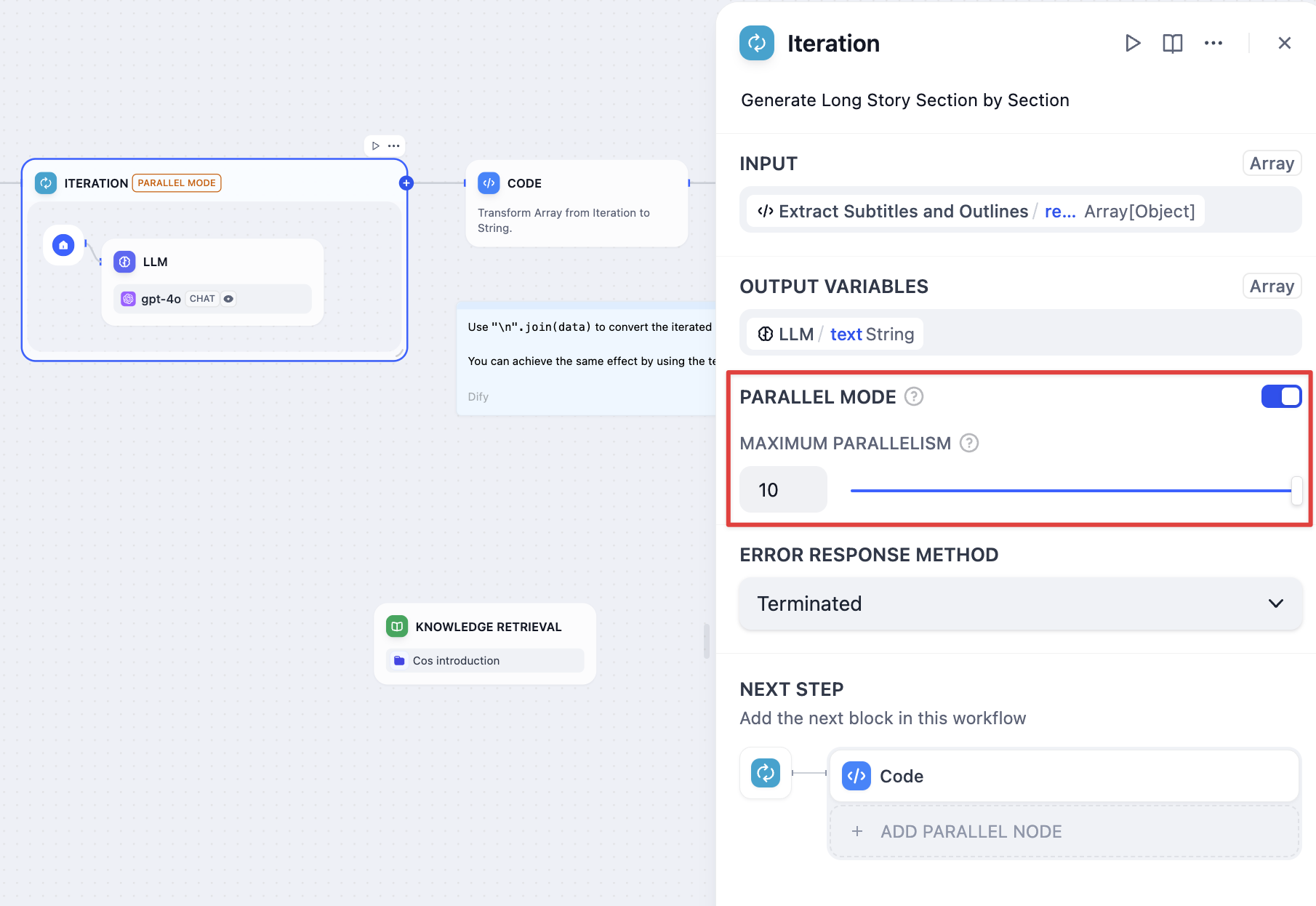 아래는 반복 노드에서 병렬 실행과 순차 실행을 비교한 것입니다.
아래는 반복 노드에서 병렬 실행과 순차 실행을 비교한 것입니다.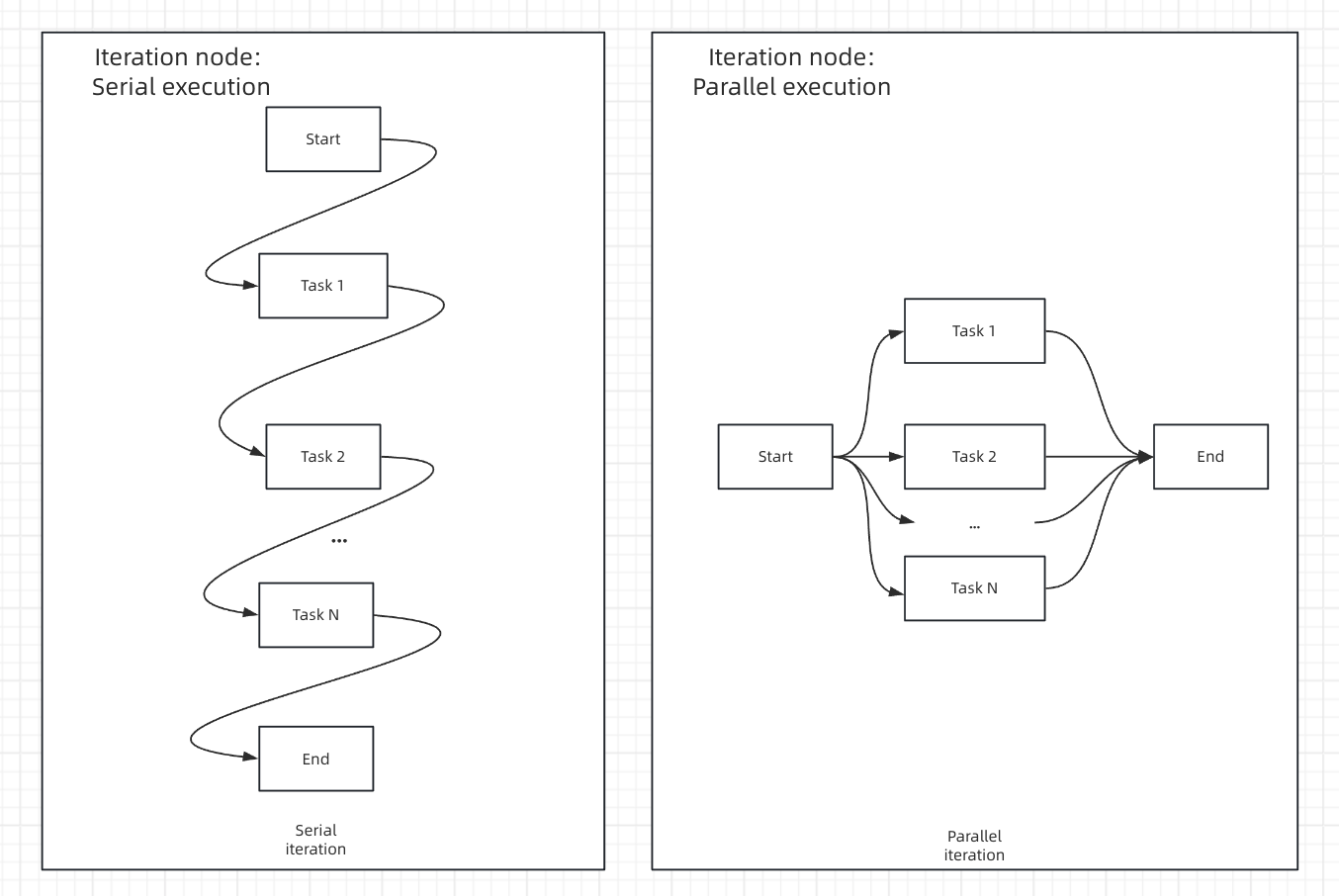 병렬 모드는 최대 10개의 동시 반복을 지원합니다. 10개 이상의 작업을 처리할 때 처음 10개 요소는 동시에 실행되고, 나머지 작업은 초기 배치가 완료된 후 처리됩니다.
병렬 모드는 최대 10개의 동시 반복을 지원합니다. 10개 이상의 작업을 처리할 때 처음 10개 요소는 동시에 실행되고, 나머지 작업은 초기 배치가 완료된 후 처리됩니다.
잠재적인 오류를 방지하려면 반복 노드 내에 직접 답변, 변수 할당 또는 도구 노드를 배치하지 마세요.
- 오류 응답 방법
반복 노드는 여러 작업을 처리하며, 요소 처리 중에 오류가 발생할 수 있습니다. 단일 오류로 인해 모든 작업이 중단되는 것을 방지하려면 다음과 같이 오류 응답 방법을 구성하세요 .
- 종료 : 예외가 감지되면 반복 노드를 종료하고 오류 메시지를 출력합니다.
- 오류 발생 시 계속 : 오류 메시지를 무시하고 나머지 요소 처리를 계속합니다. 출력에는 성공 결과가 포함되고 오류의 경우 null 값이 포함됩니다.
- 비정상 출력 제거 : 오류 메시지를 무시하고 나머지 요소 처리를 계속합니다. 출력에는 성공 결과만 포함됩니다.
입력 변수와 출력 변수는 일대일 대응 관계를 유지합니다. 예를 들면 다음과 같습니다.
- 입력: [1, 2, 3]
- 출력: [결과-1, 결과-2, 결과-3]
오류 처리 예:
- 오류가 발생해도 계속 진행 : [result-1, null, result-3]
- 비정상 출력 제거 : [result-1, result-3]
참조 #
배열 형식의 콘텐츠를 얻는 방법 #
배열 변수는 다음 노드를 반복 노드 입력으로 생성할 수 있습니다.
배열을 텍스트로 변환하는 방법 #
반복 노드의 출력 변수가 배열 형식이므로 직접 출력할 수 없습니다. 간단한 단계를 통해 배열을 다시 텍스트로 변환할 수 있습니다.코드 노드를 사용하여 변환
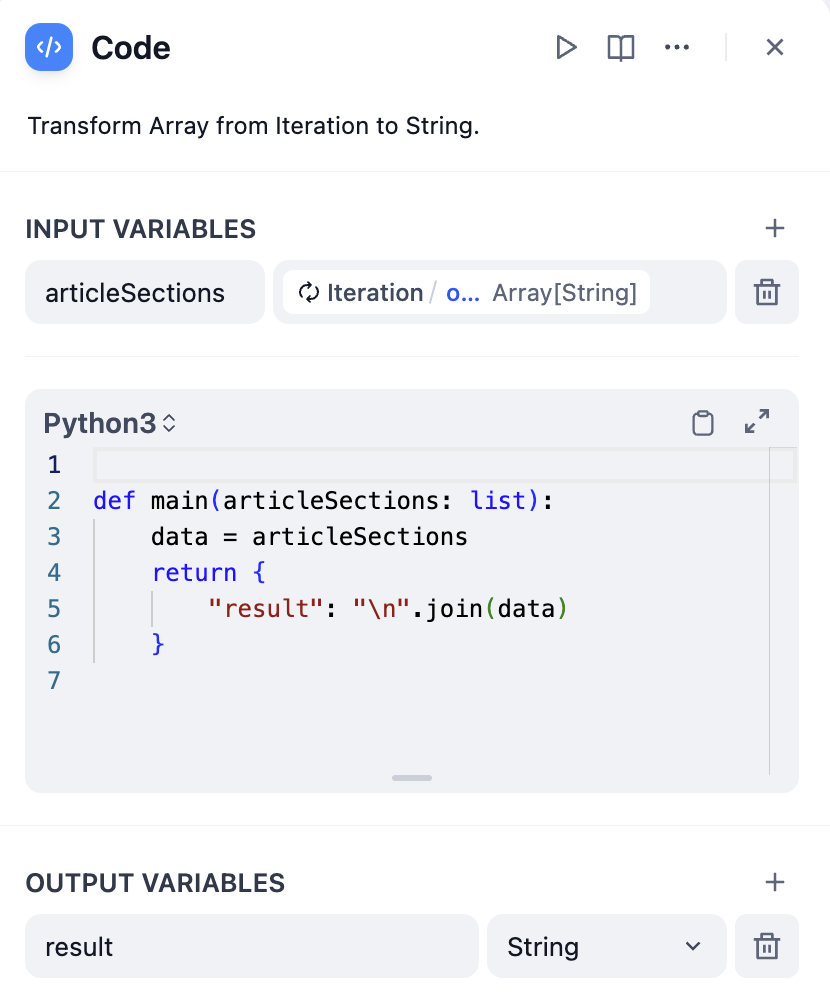
코드 예:복사AI에게 물어보세요
def main(articleSections: list):
data = articleSections
return {
"result": "/n".join(data)
}
템플릿 노드를 사용하여 변환
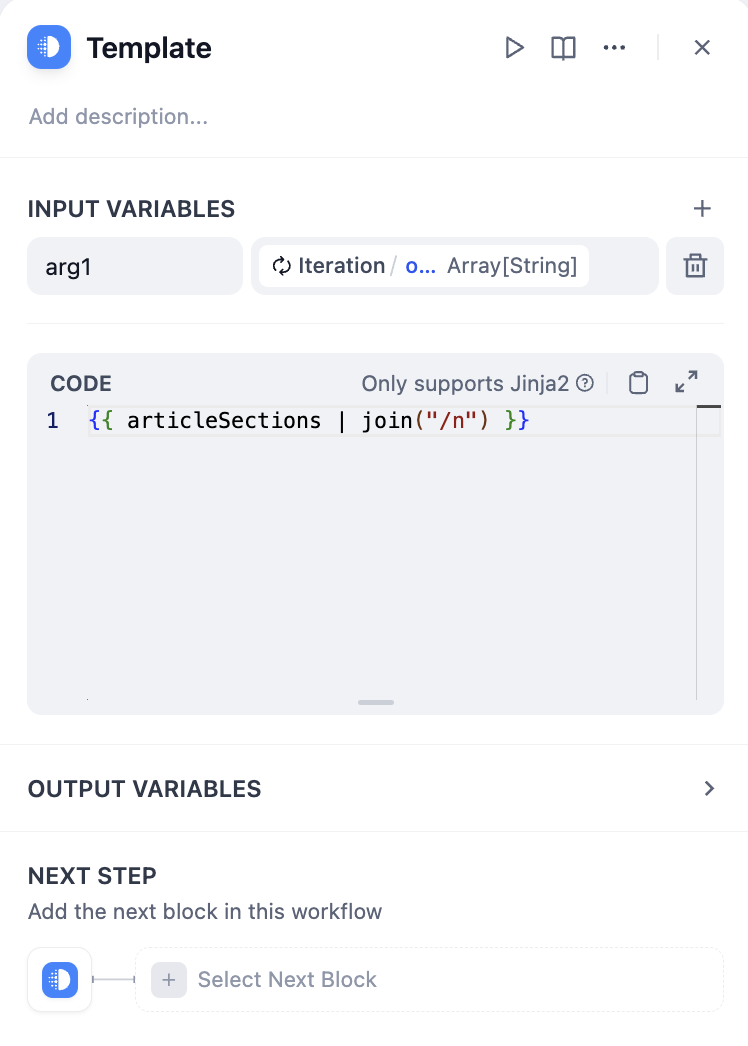
코드 예:복사AI에게 물어보세요
{{ articleSections | join("/n") }}
매개변수 추출 #
페이지 복사
1 정의 #
LLM을 활용하여 자연어에서 구조화된 매개변수를 추론하고 추출하여 후속 도구 호출이나 HTTP 요청에 사용합니다.Dify 워크플로는 다양한 도구 를 제공하며 , 대부분 구조화된 매개변수를 입력으로 필요로 합니다. 매개변수 추출기는 사용자 자연어를 이러한 도구에서 인식 가능한 매개변수로 변환하여 도구 호출을 용이하게 합니다.워크플로 내의 일부 노드는 특정 데이터 형식을 입력으로 필요로 합니다. 예를 들어, 반복 노드는 배열 형식을 필요로 합니다. 매개변수 추출기를 사용하면 구조화된 매개변수 변환을 편리하게 수행할 수 있습니다 .
2가지 시나리오 #
- 자연어에서 도구에 필요한 주요 매개변수를 추출하는 작업 (예: 간단한 대화형 Arxiv 논문 검색 애플리케이션 구축)
이 예시에서는 Arxiv 논문 검색 도구가 논문 저자 또는 논문 ID를 입력 매개변수로 요구합니다. 매개변수 추출기는 “이 논문의 내용은 무엇입니까: 2405.10739″라는 쿼리에서 논문 ID 2405.10739를 추출 하여 정밀한 쿼리를 위한 도구 매개변수로 사용합니다.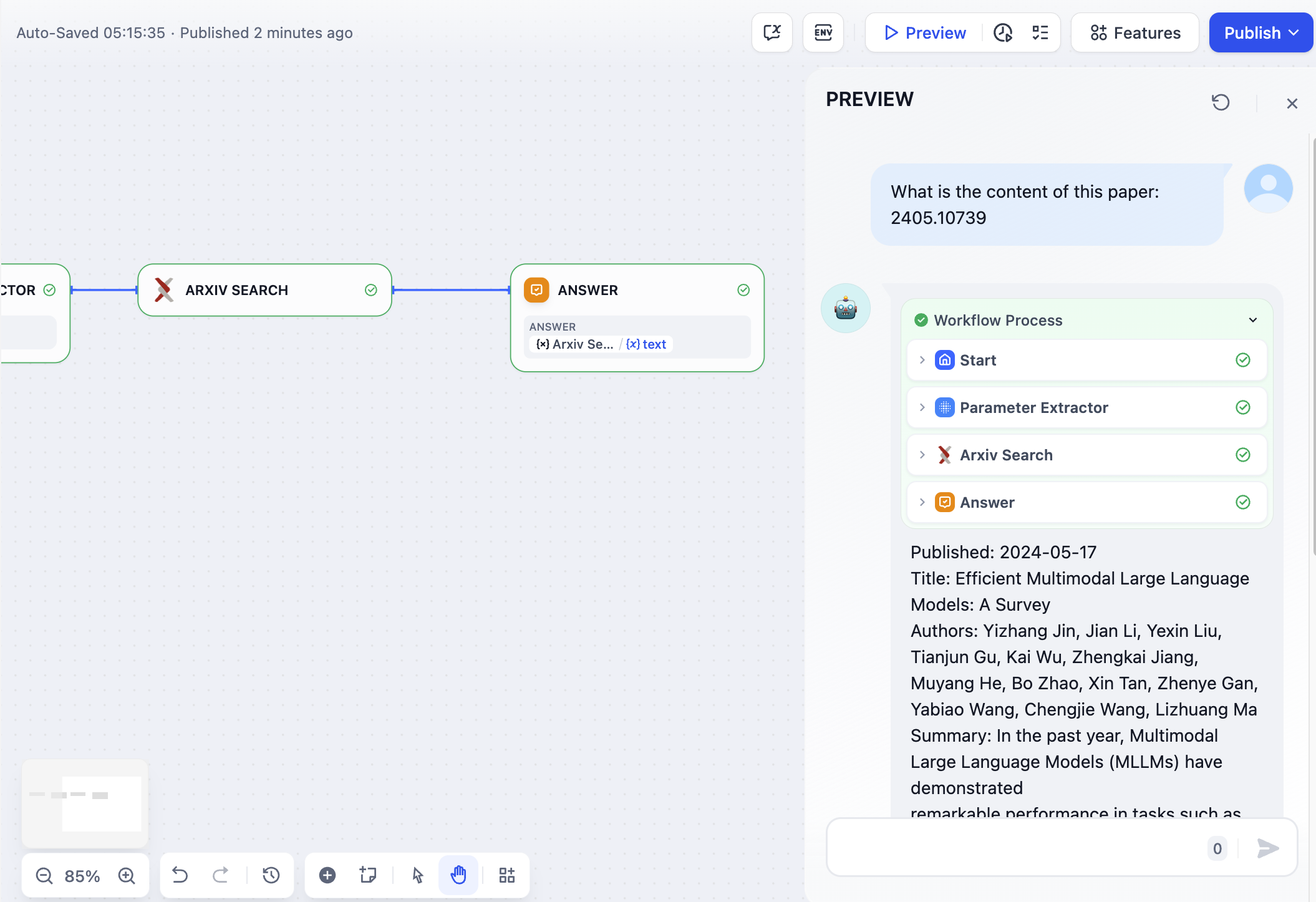
- 긴 스토리 반복 생성 애플리케이션에서처럼 텍스트를 구조화된 데이터로 변환하는 것은 반복 노드 의 사전 단계 역할을 하며 , 텍스트 형식의 챕터 콘텐츠를 배열 형식으로 변환하고, 반복 노드에서 여러 라운드 생성 처리를 용이하게 합니다.
- 구조화된 데이터를 추출하고 HTTP 요청을 사용하여 접근 가능한 모든 URL을 요청할 수 있으며, 외부 검색 결과, 웹훅, 이미지 생성 및 기타 시나리오를 얻는 데 적합합니다.
3 구성 방법 #
구성 단계
- 입력 변수를 선택합니다. 일반적으로 매개변수 추출을 위한 변수 입력입니다.
- LLM의 추론 및 구조화된 생성 기능에 의존하는 매개변수 추출기이므로 모델을 선택하세요.
- 수동으로 추가하거나 기존 도구에서 빠르게 가져올 수 있는 추출할 매개변수를 정의합니다 .
- 복잡한 매개변수를 추출할 때 효과성과 안정성을 개선하는 데 도움이 되는 예를 제공하는 지침을 작성합니다.
고급 설정추론 모드일부 모델은 두 가지 추론 모드를 지원하여 함수/도구 호출 또는 순수 프롬프트 메서드를 통해 매개변수를 추출하며, 명령어 준수 여부에 따라 차이가 있습니다. 예를 들어, 일부 모델은 함수 호출의 효율성이 낮을 경우 프롬프트 추론에서 더 나은 성능을 보일 수 있습니다.
- 함수 호출/도구 호출
- 즉각적인
메모리메모리가 활성화되면 질문 분류기의 각 입력에 대화의 채팅 기록이 포함되어 LLM이 맥락을 이해하고 대화형 대화 중에 질문 이해력을 향상시키는 데 도움이 됩니다.출력 변수
- 추출된 정의된 변수
- 노드 내장 변수
__is_success Number추출 성공 상태이며, 성공 시 값은 1, 실패 시 값은 0입니다.__reason String추출 오류 이유
HTTP 요청 #
페이지 복사
정의 #
HTTP 프로토콜을 통해 서버 요청을 전송할 수 있으며, 외부 데이터 검색, 웹훅, 이미지 생성, 파일 다운로드 등의 시나리오에 적합합니다. 지정된 웹 주소로 맞춤형 HTTP 요청을 전송하여 다양한 외부 서비스와의 상호 연결을 구축할 수 있습니다.이 노드는 일반적인 HTTP 요청 방법을 지원합니다.
- GET : 서버에 특정 리소스를 보내달라고 요청하는 데 사용됩니다.
- POST : 일반적으로 양식을 제출하거나 파일을 업로드하여 서버에 데이터를 제출하는 데 사용됩니다.
- HEAD : GET 요청과 비슷하지만, 서버는 리소스 본문 없이 응답 헤더만 반환합니다.
- PATCH : 리소스에 부분적인 수정 사항을 적용하는 데 사용됩니다.
- PUT : 서버에 리소스를 업로드하는 데 사용되며, 일반적으로 기존 리소스를 업데이트하거나 새 리소스를 만드는 데 사용됩니다.
- DELETE : 서버에 지정된 리소스를 삭제하도록 요청하는 데 사용됩니다.
URL, 요청 헤더, 쿼리 매개변수, 요청 본문 내용, 인증 정보를 포함하여 HTTP 요청의 다양한 측면을 구성할 수 있습니다.
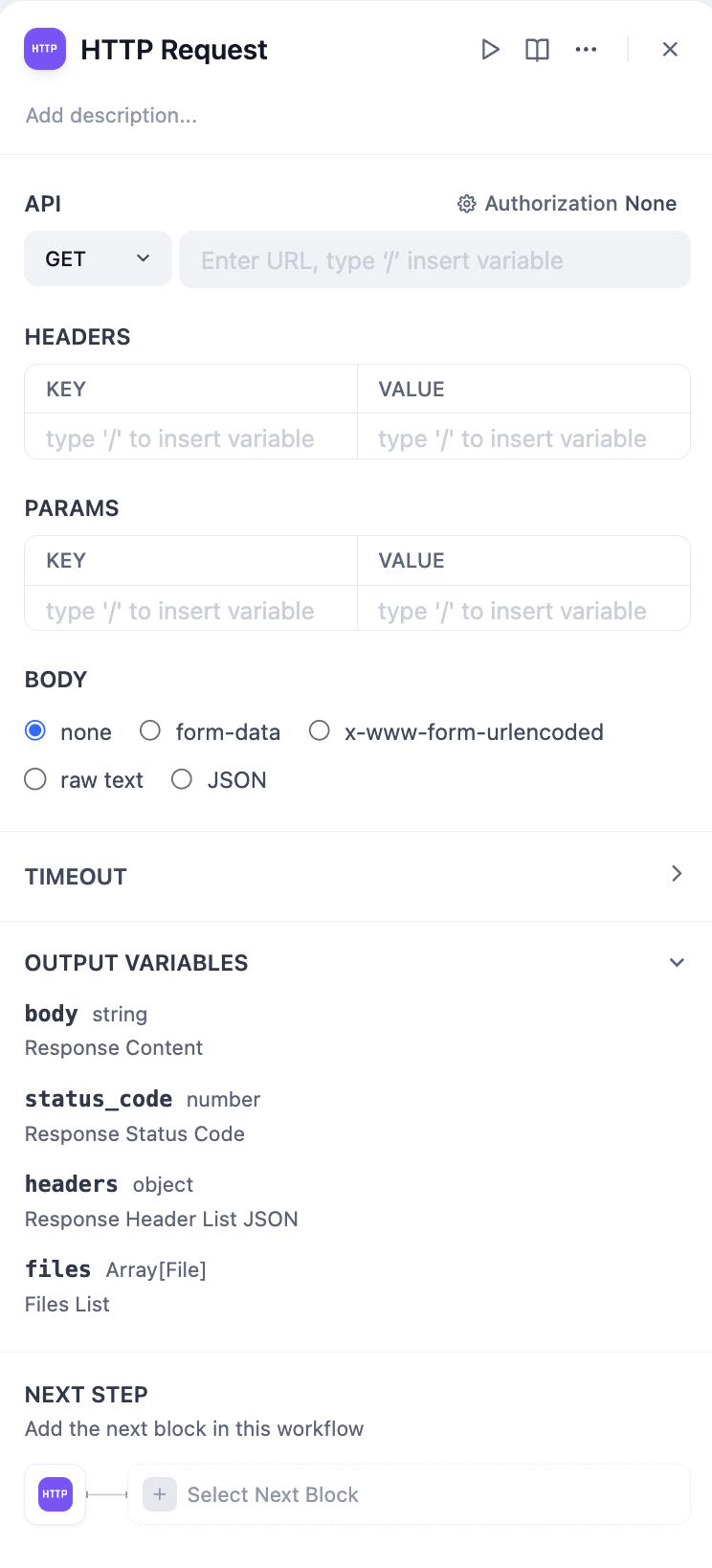
시나리오 #
- 특정 서버로 애플리케이션 상호 작용 콘텐츠 보내기
이 노드의 실용적인 기능 중 하나는 시나리오에 따라 요청의 여러 부분에 변수를 동적으로 삽입할 수 있다는 것입니다. 예를 들어, 고객 피드백 요청을 처리할 때 사용자 이름이나 고객 ID, 피드백 내용 등의 변수를 요청에 임베드하여 자동 응답 메시지를 맞춤 설정하거나 특정 고객 정보를 가져와 관련 리소스를 지정된 서버로 전송할 수 있습니다.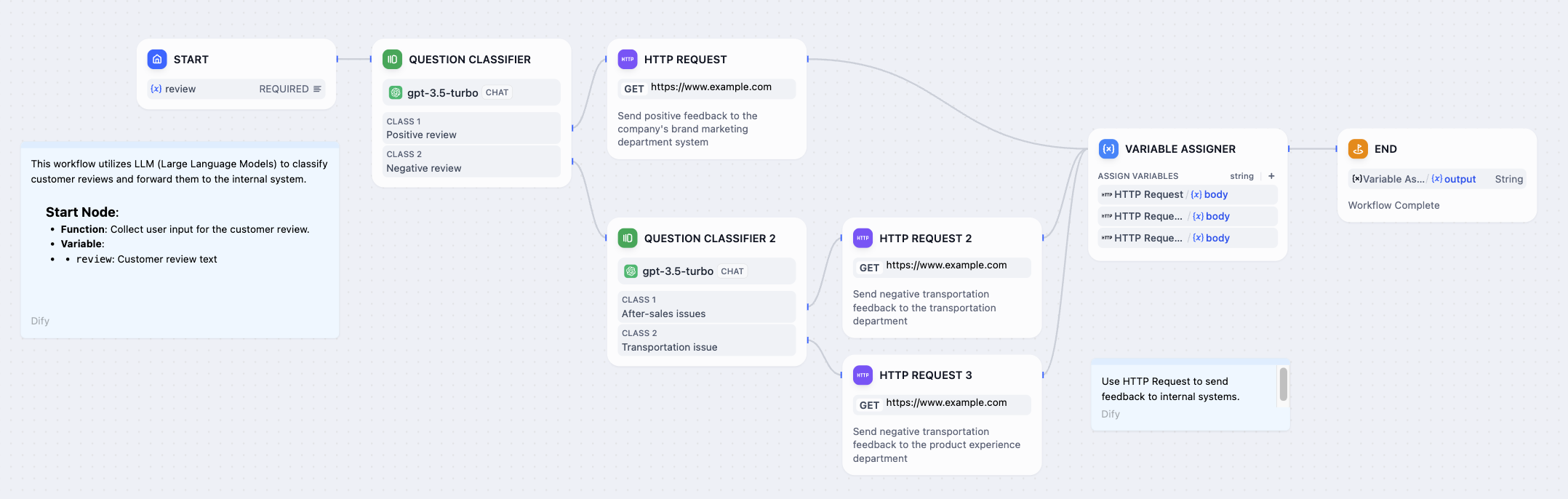 HTTP 요청의 반환 값에는 응답 본문, 상태 코드, 응답 헤더, 파일이 포함됩니다. 특히, 응답에 파일이 포함된 경우, 이 노드는 워크플로의 후속 단계에서 사용할 수 있도록 해당 파일을 자동으로 저장할 수 있습니다. 이러한 설계는 처리 효율성을 향상시킬 뿐만 아니라, 파일이 포함된 응답을 간단하고 직접적으로 처리할 수 있도록 합니다.
HTTP 요청의 반환 값에는 응답 본문, 상태 코드, 응답 헤더, 파일이 포함됩니다. 특히, 응답에 파일이 포함된 경우, 이 노드는 워크플로의 후속 단계에서 사용할 수 있도록 해당 파일을 자동으로 저장할 수 있습니다. 이러한 설계는 처리 효율성을 향상시킬 뿐만 아니라, 파일이 포함된 응답을 간단하고 직접적으로 처리할 수 있도록 합니다.
- 파일 보내기
HTTP PUT 요청을 사용하여 애플리케이션에서 다른 API 서비스로 파일을 전송할 수 있습니다. 요청 본문에서 . 내의 파일 변수를 선택할 수 있습니다 binary. 이 방법은 파일 전송, 문서 저장 또는 미디어 처리와 같은 시나리오에서 일반적으로 사용됩니다.예: 문서 관리 애플리케이션을 개발 중이고 사용자가 업로드한 PDF 파일을 타사 서비스로 전송해야 한다고 가정해 보겠습니다. HTTP 요청 노드를 사용하여 파일 변수를 전달할 수 있습니다.구성 예는 다음과 같습니다.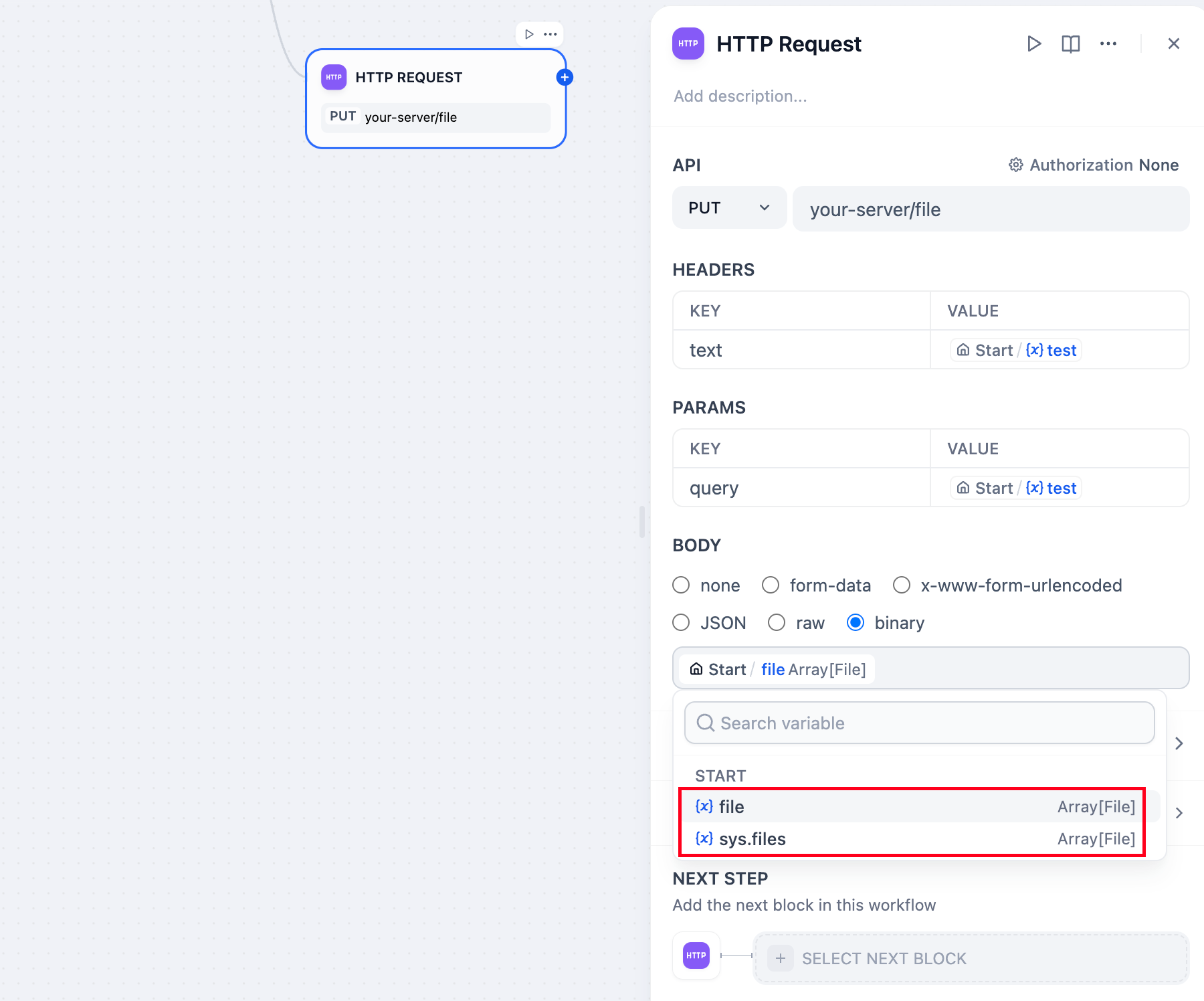
고급 기능 #
실패 시 재시도노드에서 발생하는 일부 예외의 경우, 일반적으로 노드를 다시 시도하는 것으로 충분합니다. 오류 재시도 기능이 활성화되어 있으면 오류 발생 시 노드는 미리 설정된 전략에 따라 자동으로 재시도합니다. 최대 재시도 횟수와 각 재시도 간격을 조정하여 재시도 전략을 설정할 수 있습니다.
- 최대 재시도 횟수는 10회입니다.
- 최대 재시도 간격은 5000ms입니다.
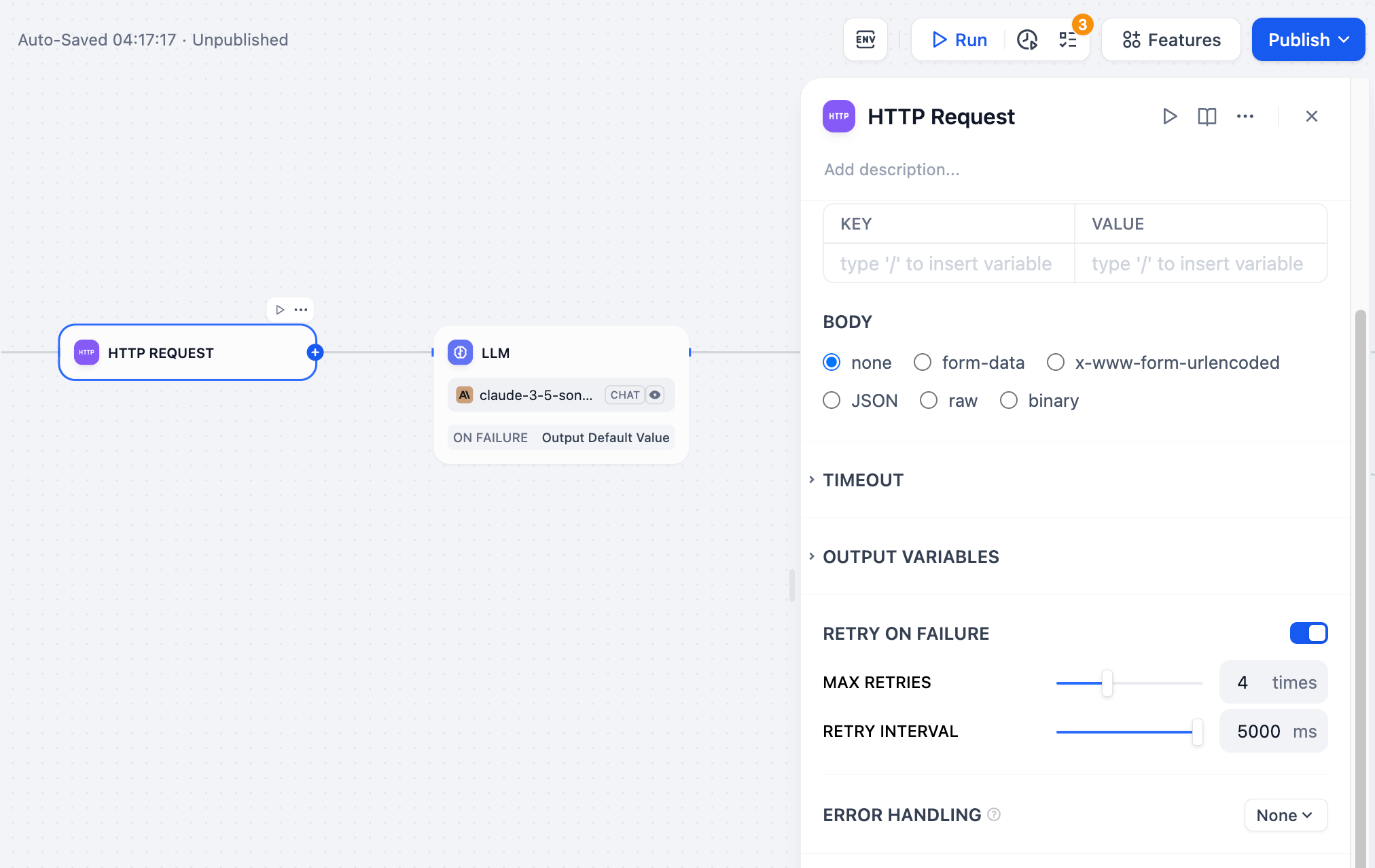 오류 처리HTTP 노드는 정보를 처리할 때 네트워크 요청 시간 초과나 요청 제한과 같은 예외 상황에 직면할 수 있습니다. 애플리케이션 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
오류 처리HTTP 노드는 정보를 처리할 때 네트워크 요청 시간 초과나 요청 제한과 같은 예외 상황에 직면할 수 있습니다. 애플리케이션 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
- HTTP 노드에서 “오류 처리”를 활성화합니다.
- 오류 처리 전략 선택 및 구성
예외 처리 접근 방식에 대한 자세한 내용은 오류 처리를 참조하세요 .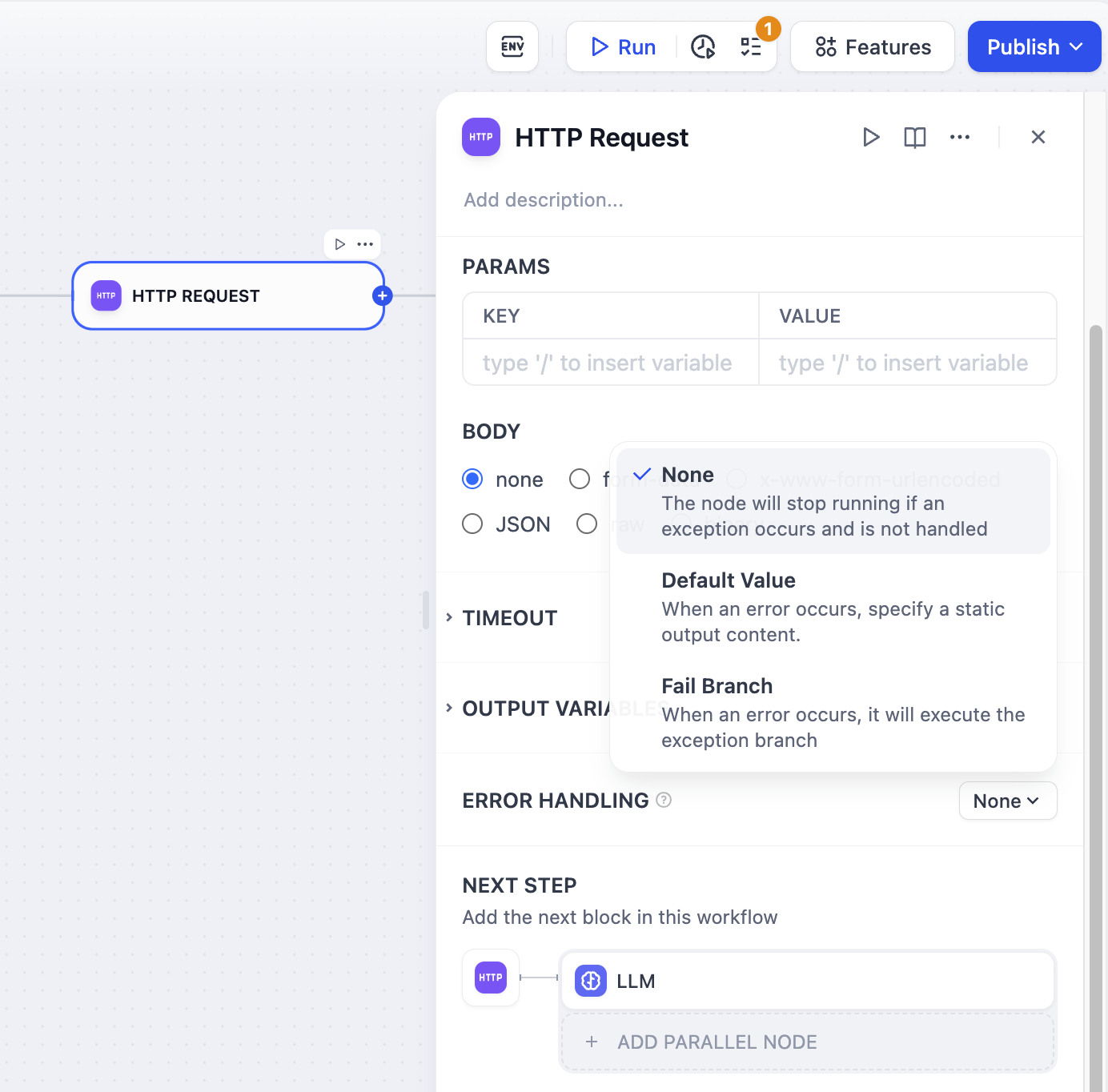
에전트(Agent) #
정의 #
에이전트 노드는 Dify Chatflow/Workflow의 구성 요소로, 자율적인 도구 호출을 지원합니다. 다양한 에이전트 추론 전략을 통합함으로써 LLM은 런타임에 도구를 동적으로 선택하고 실행하여 다단계 추론을 수행할 수 있습니다.
구성 단계 #
노드 추가 #
Dify Chatflow/Workflow 편집기에서 구성 요소 패널에서 에이전트 노드를 캔버스로 끌어다 놓습니다.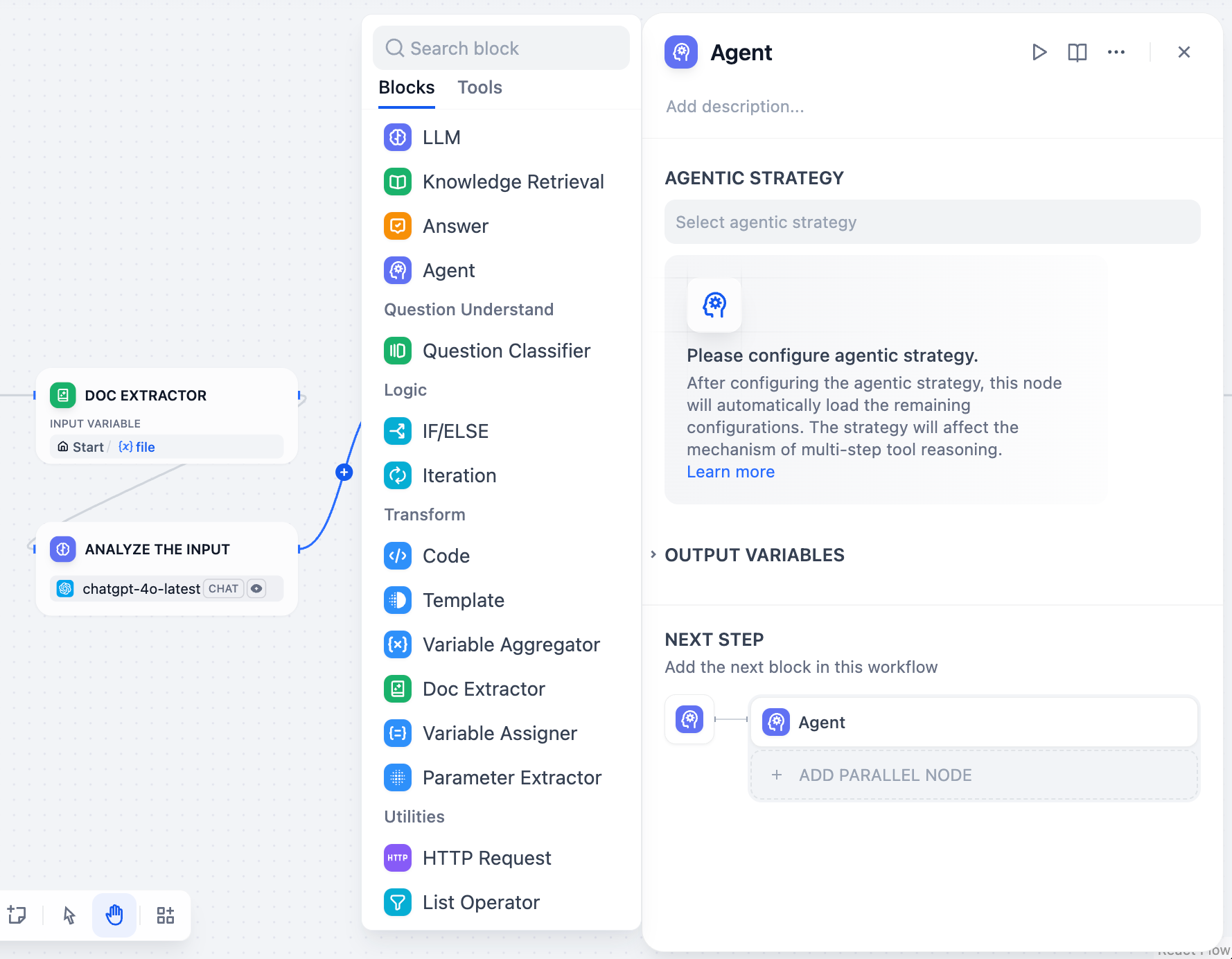
에이전트 전략 선택 #
노드 구성 패널에서 에이전트 전략을 클릭합니다.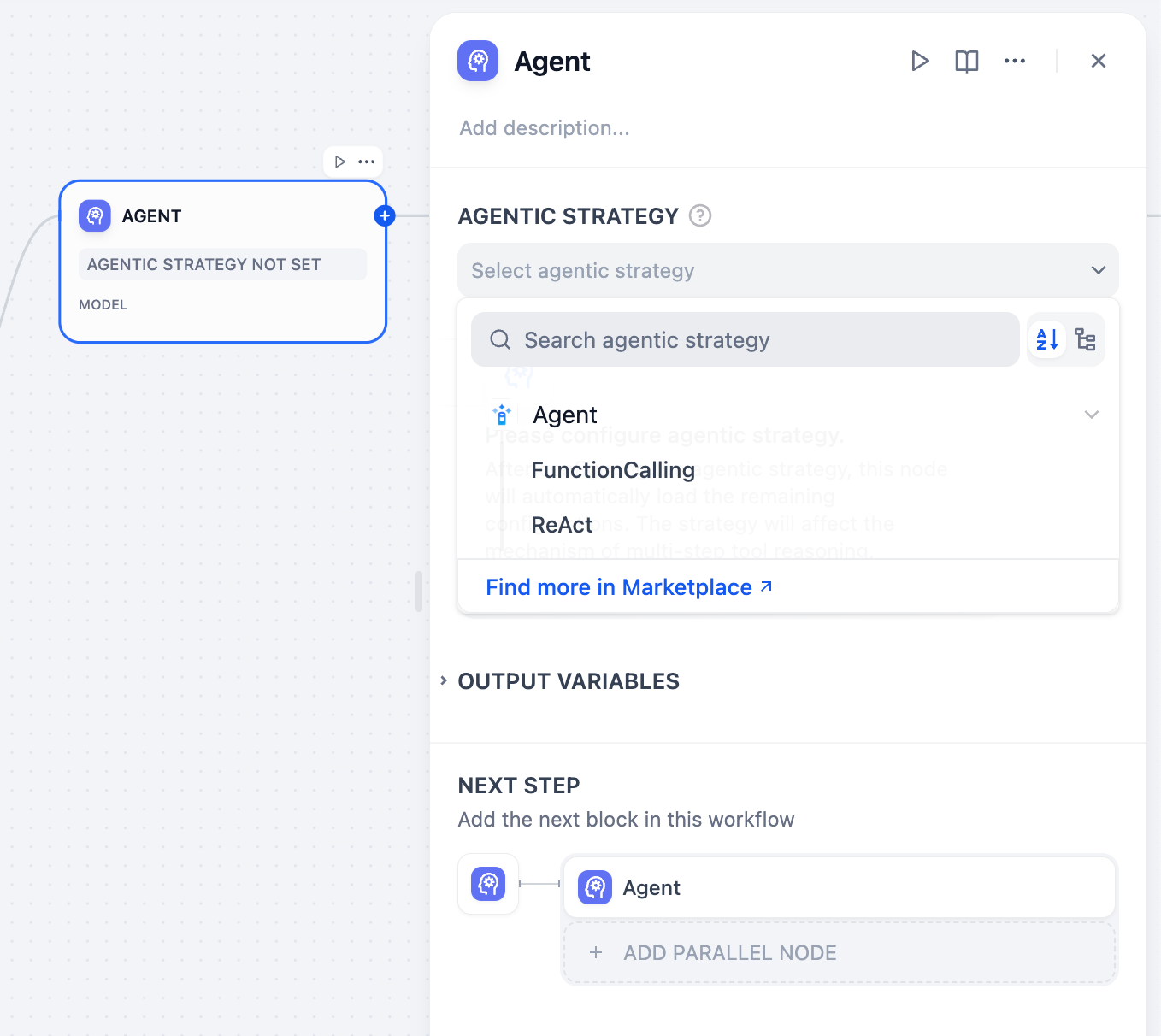 드롭다운 메뉴에서 원하는 에이전트 추론 전략을 선택하세요. Dify는 함수 호출(Function Calling)과 ReAct(ReAct)라는 두 가지 기본 전략을 제공하며, 마켓플레이스 → 에이전트 전략(Agent Strategies) 카테고리 에서 설치할 수 있습니다 .
드롭다운 메뉴에서 원하는 에이전트 추론 전략을 선택하세요. Dify는 함수 호출(Function Calling)과 ReAct(ReAct)라는 두 가지 기본 전략을 제공하며, 마켓플레이스 → 에이전트 전략(Agent Strategies) 카테고리 에서 설치할 수 있습니다 .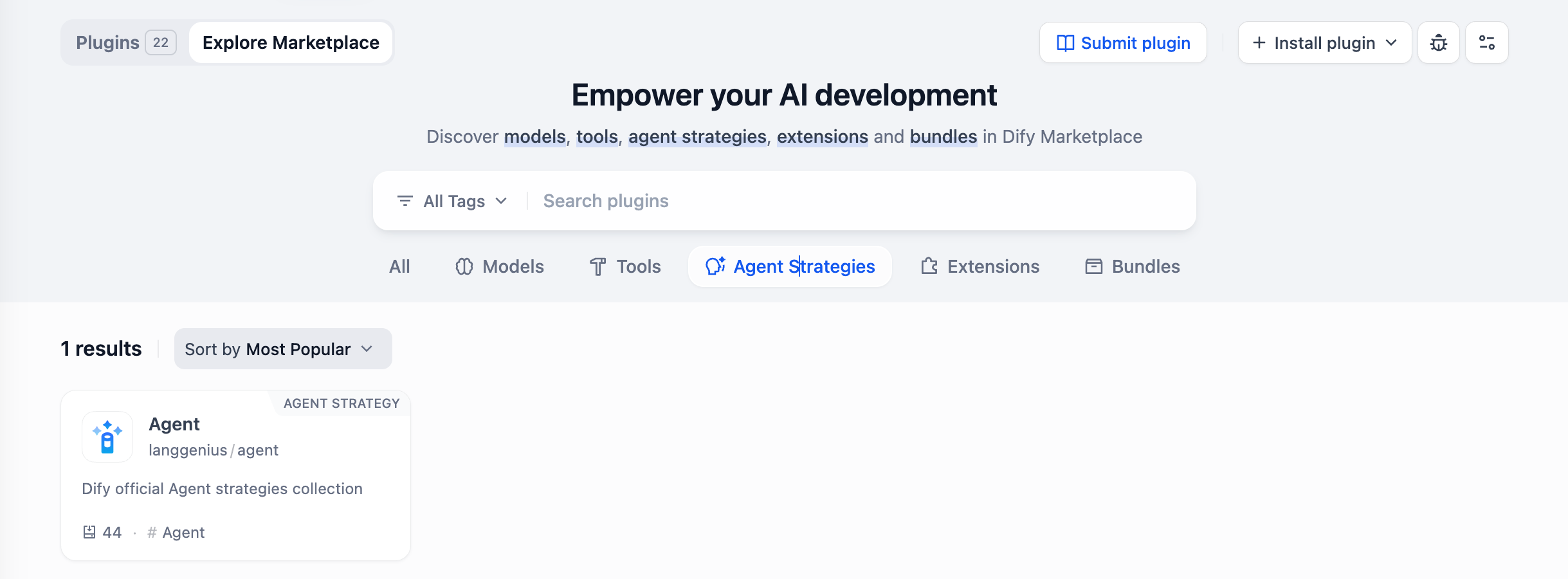
1. 함수 호출 #
함수 호출은 사용자 명령을 미리 정의된 함수 또는 도구에 매핑합니다. LLM은 먼저 사용자 의도를 파악한 후, 호출할 함수를 결정하고 필요한 매개변수를 추출합니다. 핵심 메커니즘은 외부 함수 또는 도구를 명시적으로 호출하는 것입니다.장점:• 정밀도: 명확하게 정의된 작업의 경우 복잡한 추론이 필요 없이 해당 도구를 직접 호출할 수 있습니다.• 외부 기능 통합이 더 쉬워졌습니다. 다양한 외부 API나 도구를 모델에서 호출할 수 있는 함수로 래핑할 수 있습니다.• 구조화된 출력: 모델은 함수 호출에 대한 구조화된 정보를 출력하여 다운스트림 노드의 처리를 용이하게 합니다.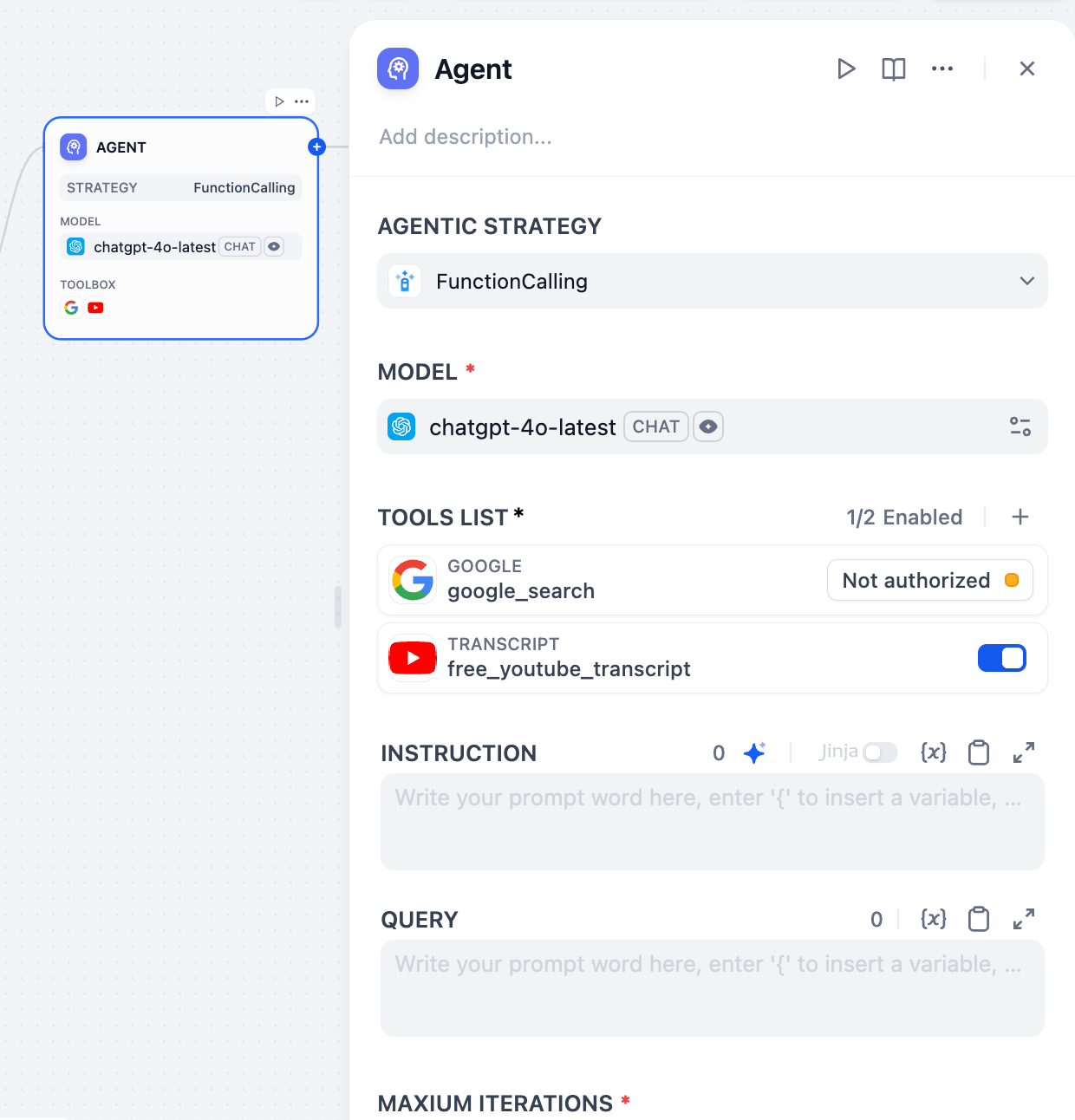
2. ReAct (이유 + 행동) #
ReAct는 에이전트가 추론과 실행을 번갈아 수행할 수 있도록 합니다. LLM은 먼저 현재 상태와 목표를 고려한 후 적절한 도구를 선택하고 호출합니다. 도구의 출력은 LLM의 다음 추론 및 실행 단계를 알려줍니다. 이러한 순환은 문제가 해결될 때까지 계속됩니다.장점:• 효과적인 외부 정보 활용: 외부 도구를 활용하여 모델만으로는 달성할 수 없는 정보를 검색하고 작업을 처리할 수 있습니다.• 설명 가능성 향상: 추론과 행동이 서로 얽혀 있기 때문에 에이전트의 사고 과정에서 일정 수준의 추적 가능성이 있습니다.• 폭넓은 적용성: Q&A, 정보 검색, 작업 실행 등 외부 지식이 필요하거나 특정 작업을 수행해야 하는 시나리오에 적합합니다.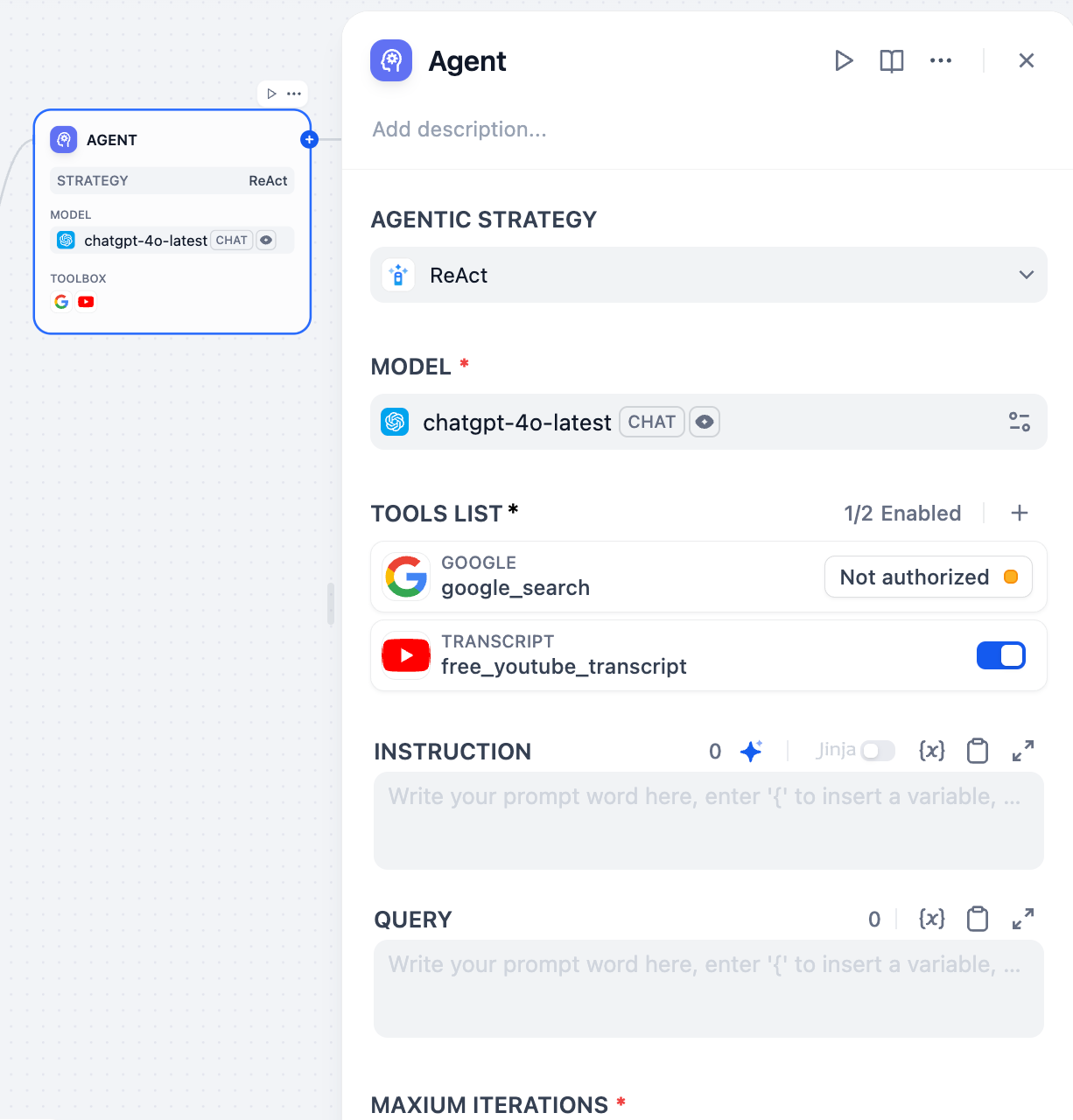 개발자는 에이전트 전략 플러그인을 공개 저장소 에 제공할 수 있습니다 . 검토 후, 해당 플러그인은 마켓플레이스에 등록되어 다른 개발자들이 설치할 수 있도록 합니다.
개발자는 에이전트 전략 플러그인을 공개 저장소 에 제공할 수 있습니다 . 검토 후, 해당 플러그인은 마켓플레이스에 등록되어 다른 개발자들이 설치할 수 있도록 합니다.
노드 매개변수 구성 #
에이전트 전략을 선택하면 구성 패널에 관련 옵션이 표시됩니다. Dify와 함께 제공되는 함수 호출 및 ReAct 전략의 경우, 사용 가능한 구성 항목은 다음과 같습니다.
- 모델: 에이전트를 구동하는 대규모 언어 모델을 선택합니다.
- 도구 목록: 도구 사용 방식은 에이전트 전략에 따라 정의됩니다. 에이전트가 호출할 수 있는 도구를 추가하고 구성하려면 +를 클릭하세요.
- 검색: 드롭다운에서 설치된 도구 플러그인을 선택합니다.
- 승인: 도구를 활성화하기 위해 API 키와 기타 자격 증명을 제공합니다.
- 도구 설명 및 매개변수 설정: LLM이 도구를 언제, 왜 사용해야 하는지 이해하고, 모든 기능적 매개변수를 구성하는 데 도움이 되는 설명을 제공합니다.
- 지침 : 에이전트의 작업 목표와 컨텍스트를 정의합니다. Jinja 구문을 사용하여 업스트림 노드 변수를 참조할 수 있습니다.
- 쿼리 : 사용자 입력을 받습니다.
- 최대 반복 횟수: 에이전트의 실행 단계의 최대 횟수를 설정합니다.
- 출력 변수: 노드가 출력하는 데이터 구조를 나타냅니다.
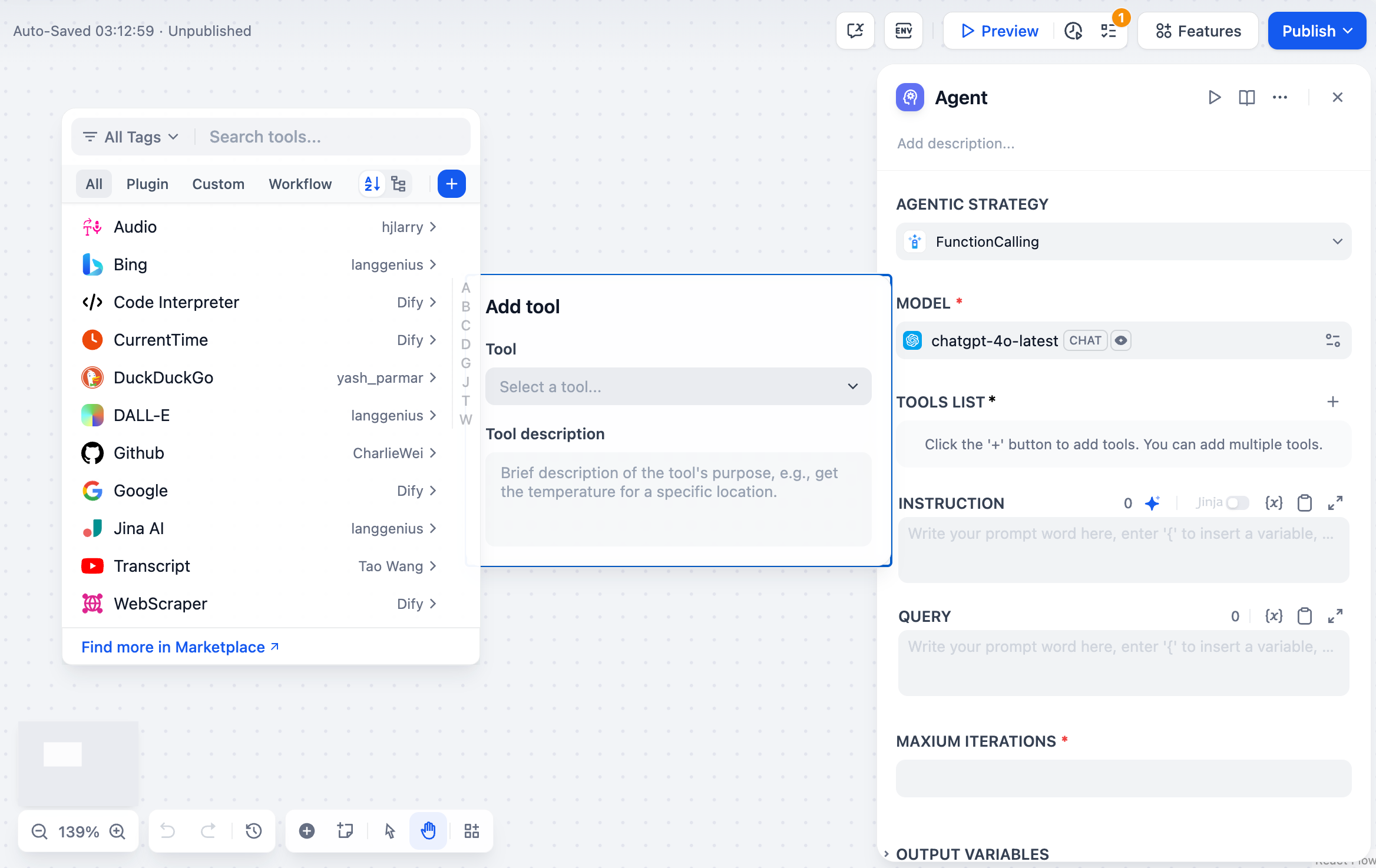
로그 #
실행 중에 에이전트 노드는 자세한 로그를 생성합니다. 입력 및 출력, 토큰 사용량, 소요 시간 및 상태를 포함한 전반적인 노드 실행 정보를 볼 수 있습니다. ‘세부 정보’를 클릭하면 각 에이전트 전략 실행 라운드의 출력을 볼 수 있습니다.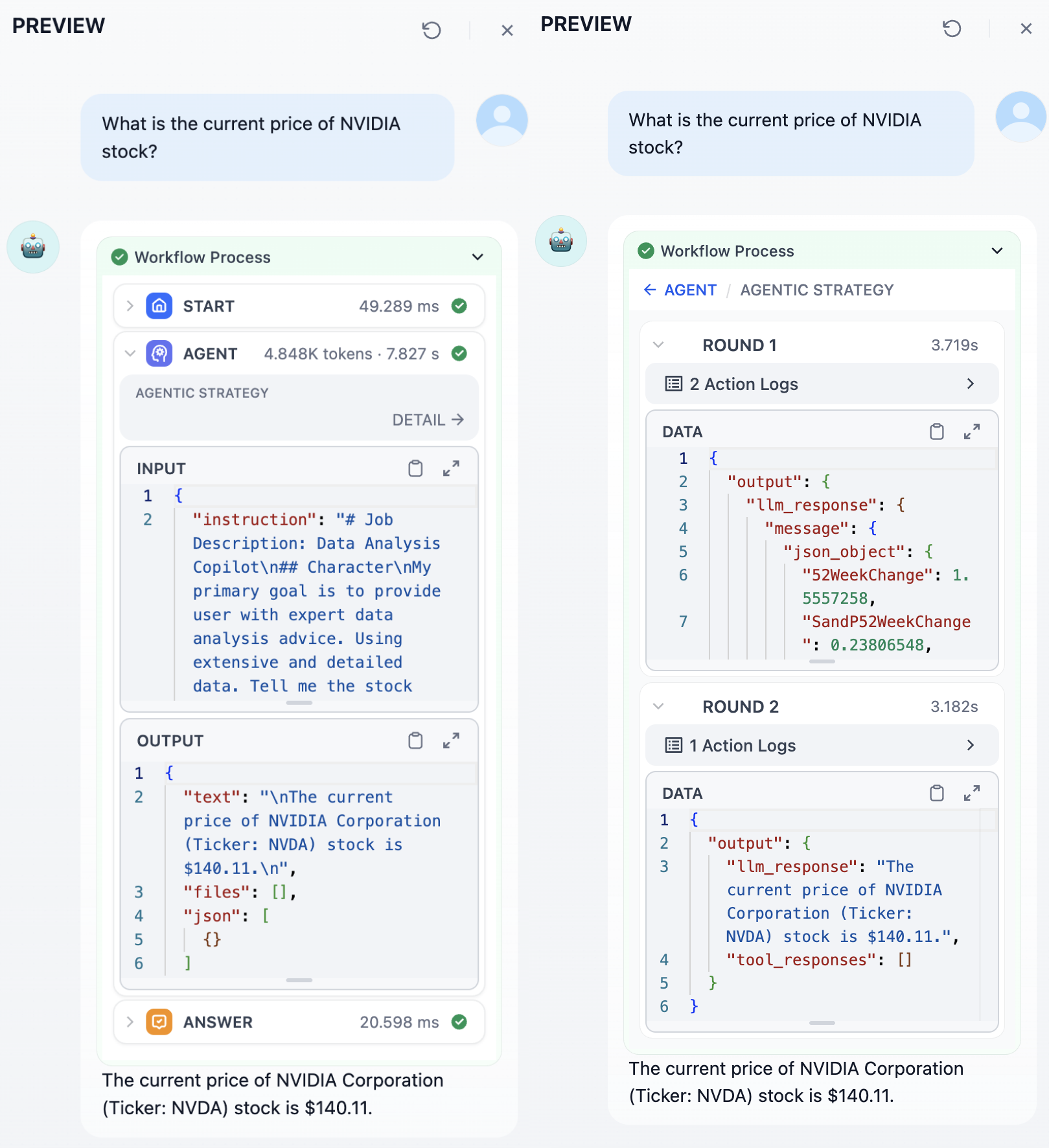
메모리 #
메모리 토글을 활성화하면 에이전트가 대화 맥락을 기억하고 불러올 수 있습니다. 창 크기를 조정하면 에이전트가 “기억”할 수 있는 이전 대화 메시지 수를 제어할 수 있습니다. 이를 통해 에이전트는 이전 대화를 이해하고 참조할 수 있으며, 여러 차례 대화가 이어지는 상황에서도 일관성 있고 맥락에 맞는 답변을 제공하여 대화 경험을 향상시킵니다.예를 들어, 사용자가 후속 메시지에서 대명사(예: “그것”, “이것” 또는 “그들”)를 사용하는 경우 메모리 기능이 활성화된 에이전트는 사용자가 전체 정보를 다시 설명하지 않고도 이전 맥락에서 이러한 대명사가 가리키는 내용을 이해할 수 있습니다.
사용 사례에 맞는 도구 사용자 정의 #
에이전트 노드나 에이전트에 도구를 추가하면 도구의 동작 방식을 사용자 지정할 수 있습니다.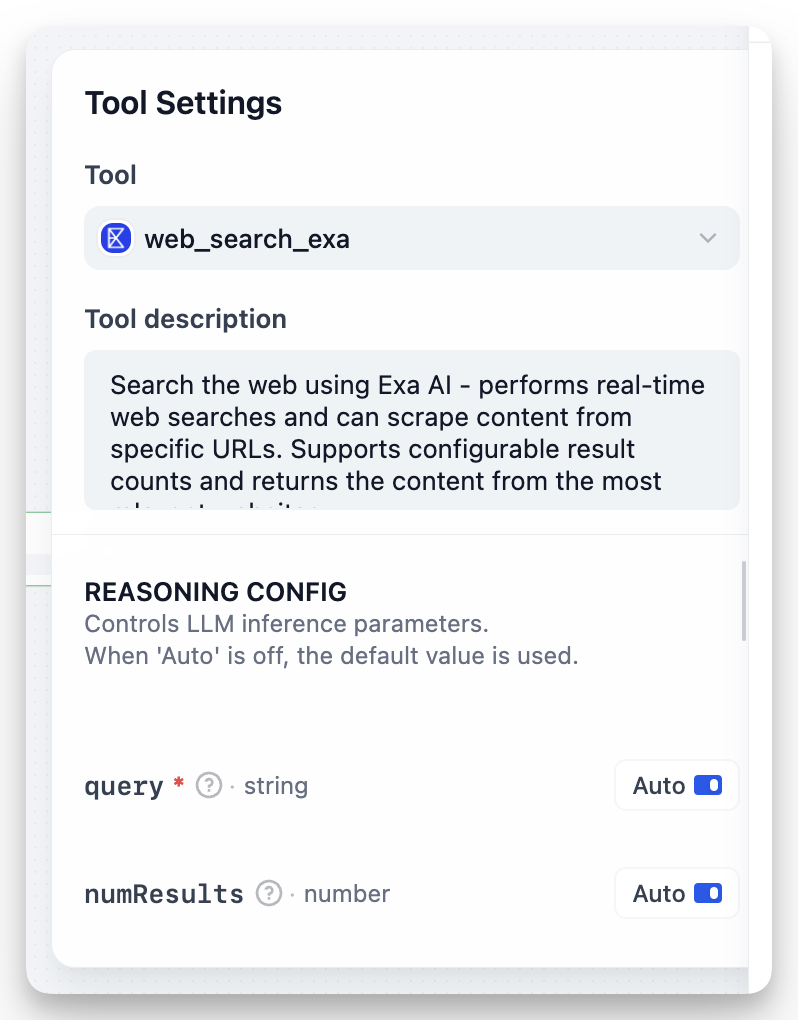
도구 설명 #
MCP 서버에서 제공되는 기본 설명을 재정의할 수 있습니다. 이는 사용 사례에 맞게 설명을 더욱 구체적으로 작성하는 데 유용합니다.
매개변수 구성(추론 구성) #
각 도구 매개변수에 대해 다음 중에서 선택할 수 있습니다.자동 : AI 모델이 컨텍스트에 따라 매개변수 값을 결정하도록 합니다(기본 동작)고정 값 : 항상 사용될 특정 값(정적 값 또는 변수일 수 있음)을 설정하여 AI 추론에서 매개변수를 제거합니다.이것은 다음의 경우에 유용합니다:
- 일관된 구성 값 설정(
numResults: 10검색 도구의 경우와 같이) - 변경되어서는 안 되는 매개변수 미리 채우기(특정 API 엔드포인트 또는 형식 기본 설정 등)
- AI가 처리해야 하는 매개변수 수를 줄여 도구 사용을 단순화합니다.
예를 들어, 웹 검색 도구를 사용하면 다음과 같은 작업을 수행할 수 있습니다.
queryAI가 검색할 내용을 결정하도록 “자동”을 유지하세요 .numResults응답 크기를 제한하려면 “5”와 같은 고정 값으로 설정하세요 .- 일관된 동작을 위해 검색 필터와 같은 다른 매개변수를 고정 값으로 설정합니다.
도구 #
페이지 복사
워크플로는 세 가지 유형으로 분류된 다양한 도구를 제공합니다.
- 내장 도구 : Dify가 제공하는 도구입니다.
- 사용자 정의 도구 : OpenAPI/Swagger 표준 형식을 통해 가져오거나 구성된 도구입니다.
- 워크플로 : 도구로 게시된 워크플로.
도구 노드 추가 및 사용 #
기본 제공 도구를 사용하려면 먼저 도구를 인증 해야 할 수도 있습니다.기본 제공 도구가 요구 사항을 충족하지 못하는 경우 Dify 메뉴 탐색 – 도구 섹션에서 사용자 지정 도구를 만들 수 있습니다.더욱 복잡한 워크플로를 조율하고 도구로 게시할 수도 있습니다.
 도구 노드를 구성하는 데는 일반적으로 두 단계가 포함됩니다.
도구 노드를 구성하는 데는 일반적으로 두 단계가 포함됩니다.
- 도구 승인/사용자 정의 도구 생성/워크플로를 도구로 게시.
- 도구의 입력 및 매개변수 구성.
사용자 정의 도구를 만들고 구성하는 방법에 대한 자세한 내용은 도구 구성 가이드 를 참조하세요 .
고급 기능 #
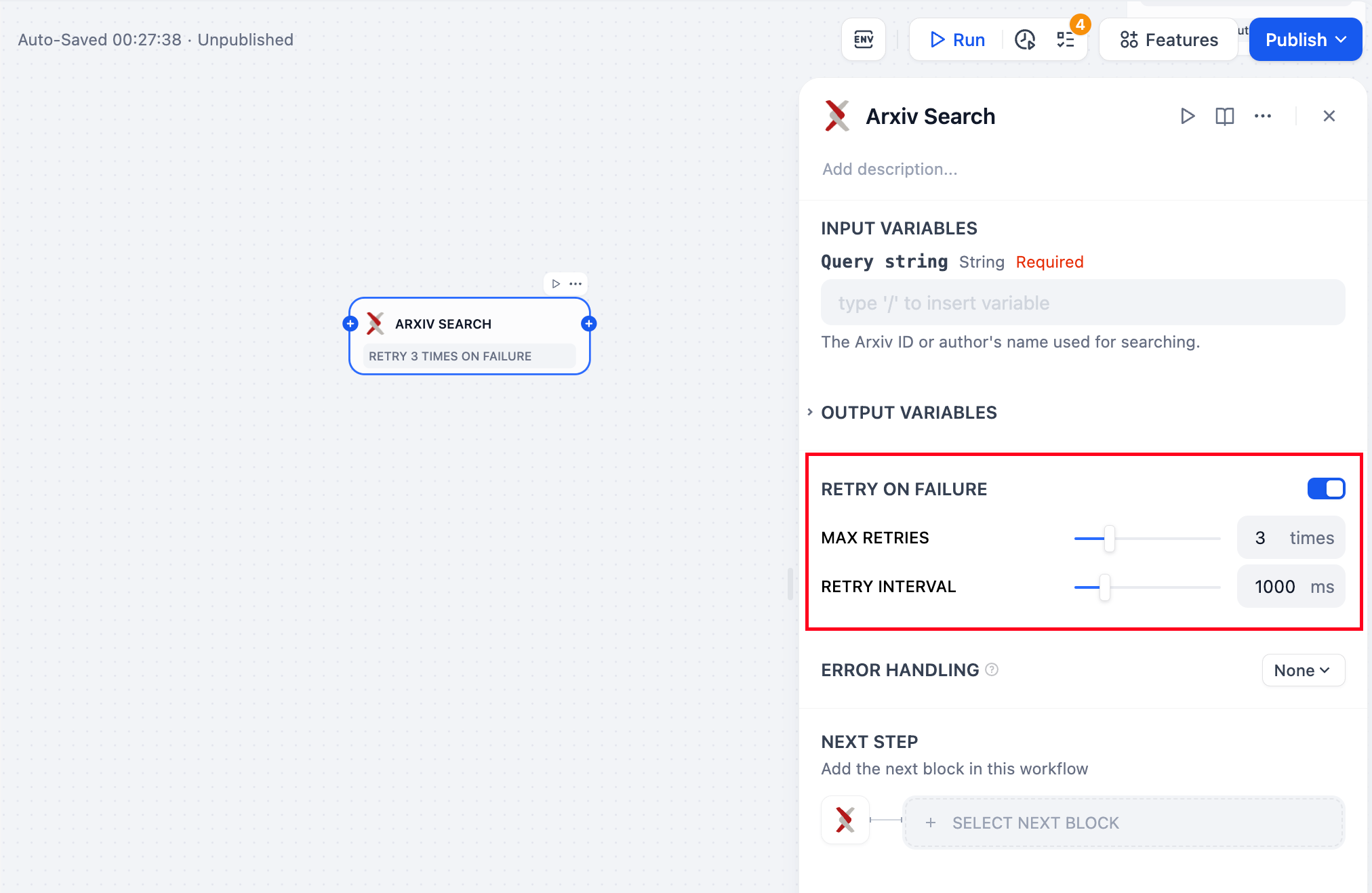
실패 시 재시도노드에서 발생하는 일부 예외의 경우, 일반적으로 노드를 다시 시도하는 것으로 충분합니다. 오류 재시도 기능이 활성화되어 있으면 오류 발생 시 노드는 미리 설정된 전략에 따라 자동으로 재시도합니다. 최대 재시도 횟수와 각 재시도 간격을 조정하여 재시도 전략을 설정할 수 있습니다.
- 최대 재시도 횟수는 10회입니다.
- 최대 재시도 간격은 5000ms입니다.
 오류 처리도구 노드에서는 정보 처리 중에 워크플로를 중단시킬 수 있는 오류가 발생할 수 있습니다. 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
오류 처리도구 노드에서는 정보 처리 중에 워크플로를 중단시킬 수 있는 오류가 발생할 수 있습니다. 개발자는 다음 단계에 따라 실패 분기를 구성하여 노드에서 예외 발생 시 비상 계획을 실행하고 워크플로 중단을 방지할 수 있습니다.
- 도구 노드에서 “오류 처리”를 활성화합니다.
- 오류 처리 전략을 선택하고 구성합니다.
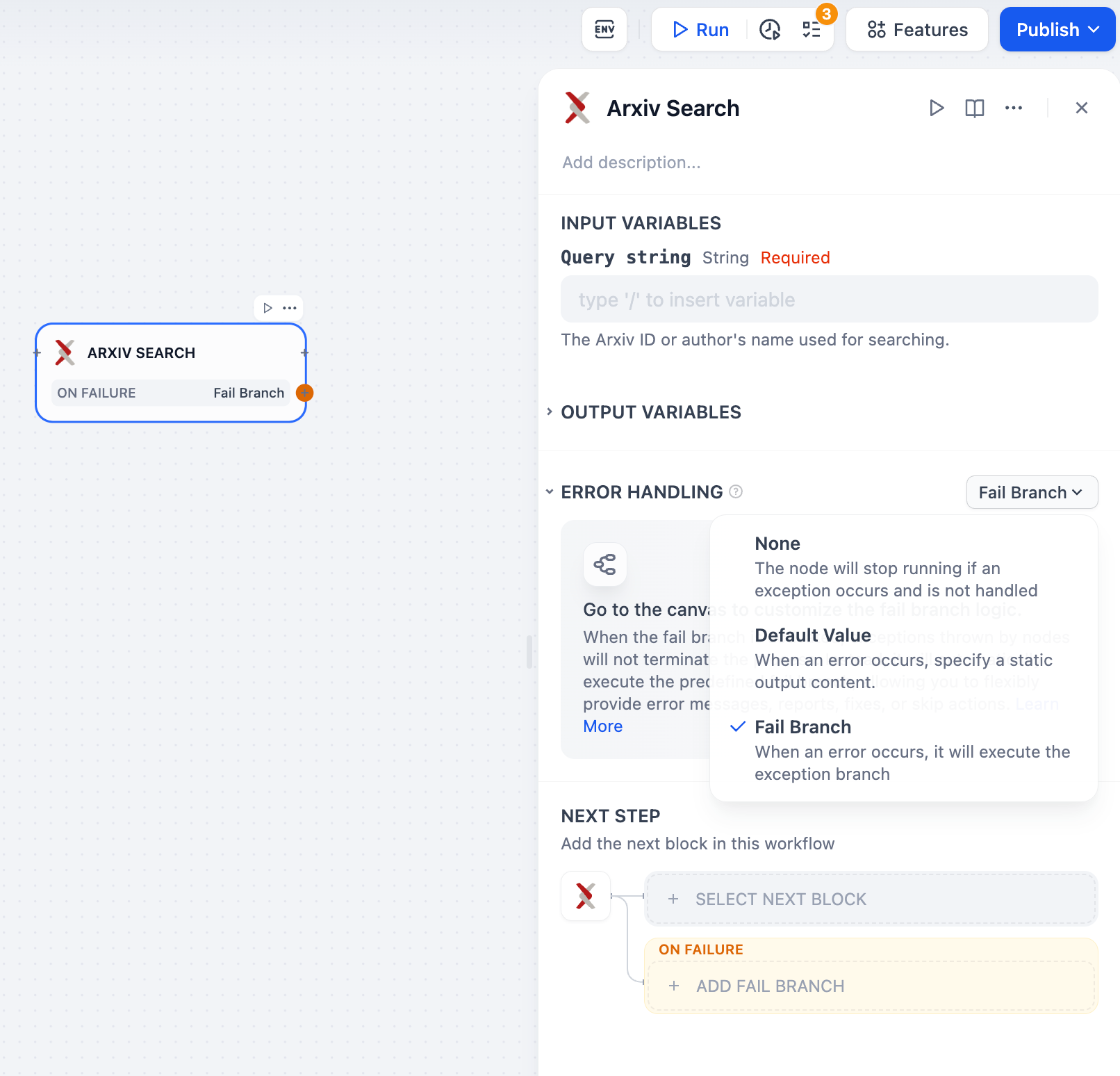 예외 처리 접근 방식에 대한 자세한 내용은 오류 처리를 참조하세요 .
예외 처리 접근 방식에 대한 자세한 내용은 오류 처리를 참조하세요 .
워크플로 애플리케이션을 도구로 게시 #
워크플로 애플리케이션은 도구로 게시되어 다른 워크플로의 노드에서 사용될 수 있습니다. 사용자 지정 도구 및 도구 구성에 대한 자세한 내용은 도구 구성 가이드 를 참조하세요 .
루프(Loop) #
루프 노드란 무엇인가요? #
루프 노드 는 종료 조건이 충족되거나 최대 루프 수에 도달할 때까지 이전 반복 결과에 따라 반복되는 작업을 실행합니다.
루프 대 반복 #
| 유형 | 종속성 | 사용 사례 |
|---|---|---|
| 고리 | 각 반복은 이전 결과에 따라 달라집니다. | 재귀 연산, 최적화 문제 |
| 반복 | 반복은 독립적으로 실행됩니다 | 일괄 처리, 병렬 데이터 처리 |
구성 #
| 매개변수 | 설명 | 예 |
|---|---|---|
| 루프 종료 조건 | 루프를 종료할 시점을 결정하는 표현식 | x < 50,error_rate < 0.01 |
| 최대 루프 수 | 무한 루프를 방지하기 위한 반복 횟수 상한 | 10, 100, 1000 |
| 루프 변수 | 루프가 완료된 후에도 반복 작업 동안 지속되고 노드에서 계속 액세스할 수 있는 값 | 반복할 때마다 카운터가 x < 501씩 증가합니다. 루프 내부에서 계산에 사용한 후, 이후 워크플로 단계에서 최종 값에 접근합니다. |
| 출구 루프 노드 | 도달하면 루프를 즉시 종료합니다. | 다른 조건에 관계없이 실행을 10번의 반복으로 제한합니다. |
루프는 Exit Loop Node 또는 Loop Termination Condition 을 통해 종료될 수 있습니다 . 두 조건 중 하나가 충족되면 루프는 즉시 종료됩니다.종료 조건이 지정되지 않으면 루프는 최대 루프 수에 도달할 때까지 계속 실행됩니다( 와 유사 while (true)) .
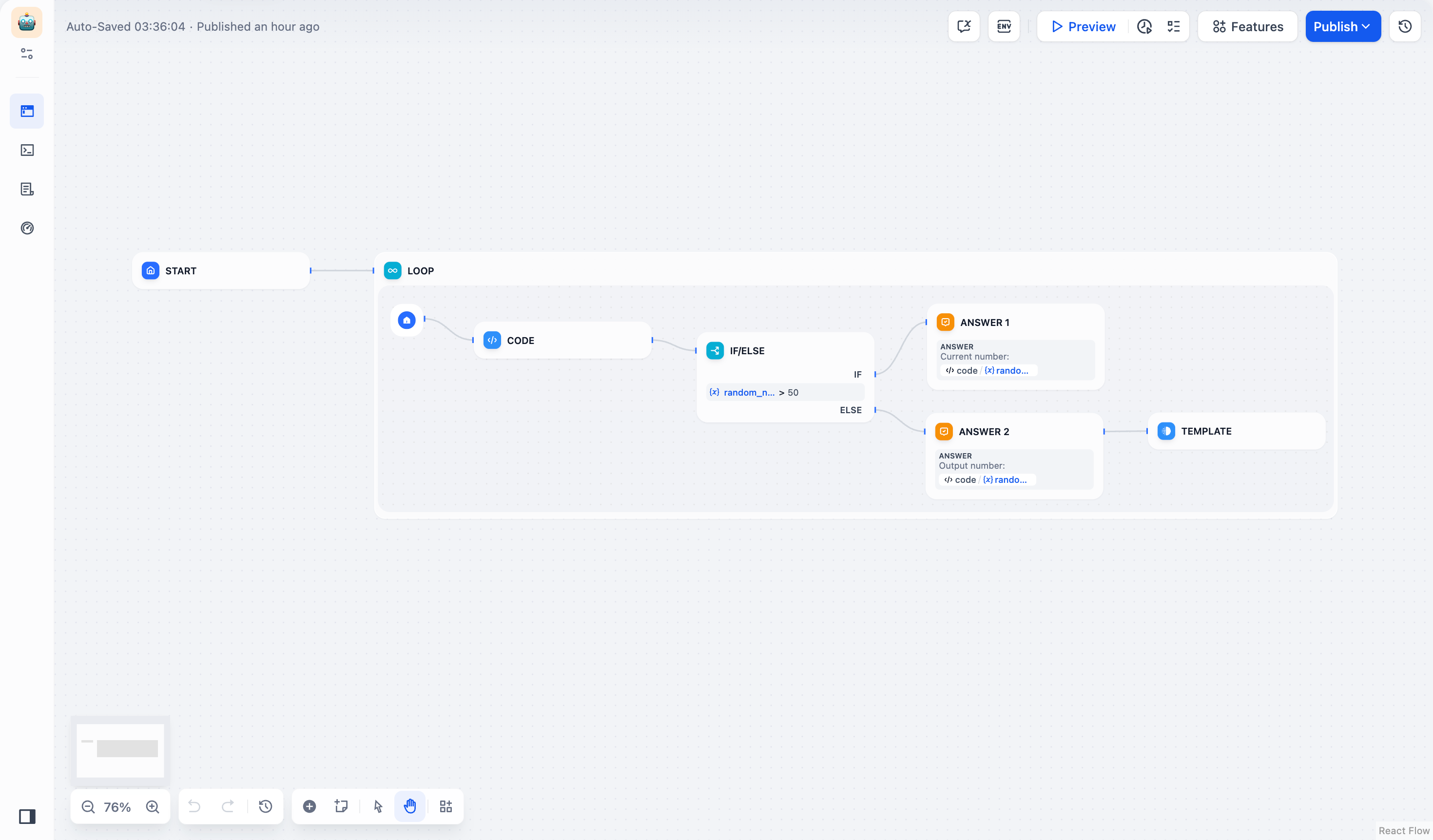
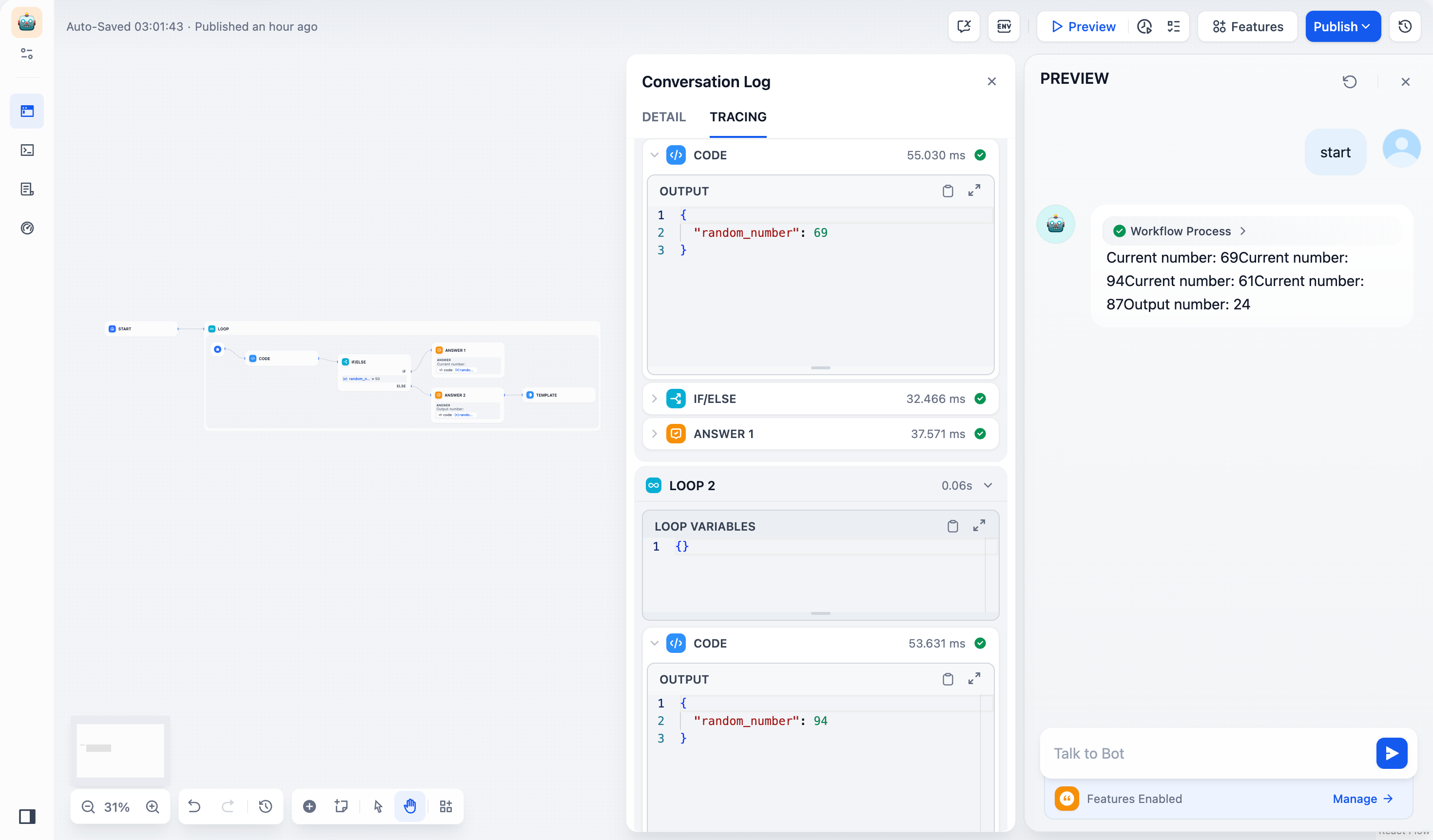
예제 1: 기본 루프 #
목표: 1~100 사이의 난수를 생성하여 50보다 작은 숫자를 생성합니다.단계 :
- 템플릿 노드가 반환될 때 루프 종료 조건 이 트리거되도록 구성하여 루프 노드 를 설정합니다 .
done - 에서 사이의 난수 정수를 생성하는 코드 노드를 설정합니다 .
1100 - 다음 논리를 사용하여 IF/ELSE 노드를 설정합니다 .
- 숫자 ≥ 50의 경우: 출력
Current Number하고 루프를 계속합니다. - 숫자 < 50의 경우: 를 출력한
Final Number다음 Template 노드를 사용하여 반환합니다.done
- 아래 숫자가
50생성되면 워크플로가 자동으로 종료됩니다.
예제 2: 고급 루프(변수 및 종료 노드 포함) #
목표: 이전 버전을 기반으로 각 버전을 구축하여 4번의 반복적 개선을 거쳐 시를 생성하는 워크플로를 설계합니다.단계:
- 다음 루프 변수를 사용하여 루프 노드를 설정합니다 .
- num: 0부터 시작하여 반복마다 1씩 증가하는 카운터
- verse: 초기화된 텍스트 변수
I haven't started creating yet
- 반복 횟수를 평가하는 IF/ELSE 노드를 설정합니다 .
- num > 3일 때: Exit Loop 노드 로 진행합니다.
- num ≤ 3일 때: LLM 노드 로 이동합니다.
- 시를 생성하기 위해 LLM 노드를 설정합니다 .
예시 프롬프트:당신은 유럽의 문학적 인물로서, 시를 바탕으로 시를 창작할 수 있습니다 sys.query.verse마지막 작품입니다. 이전 작품을 바탕으로 작업을 진행하시면 됩니다.
첫 번째 반복은 초기 시 값 으로 시작합니다 I haven't started creating yet. 이후의 각 반복은 이전 출력을 기반으로 하며, 새로운 시가 시 변수의 내용을 대체합니다.
- 상태를 관리하기 위해 변수 할당자 노드를 설정합니다 .
- 각 반복 후에 num을 1씩 증가시킵니다.
- 새로 생성된 시로 구절을 업데이트합니다.
- 워크플로를 실행하면 시의 네 가지 버전이 생성되고, 각 버전은 이전 출력을 기반으로 구축됩니다.



